 |


парной линейной корреляции
|
|
|
|
рода.
Вероятность такой ошибки обычно обозначается как α. В сущности, мы должны были бы указывать в скобках не р < 0,05 или р < 0,01, а α < 0,05 или α < 0,01. В некоторых руководствах так и делается (Рунион Р., 1982; Захаров В.П., 1985 и др.).
Если вероятность ошибки - это α, то вероятность правильного решения: 1—α. Чем меньше α, тем больше вероятность правильного решения.
Исторически сложилось так, что принято считать низшим уровнем статистической значимости 5%-ый уровень (р≤0,05): достаточным – 1%-ый уровень (р≤0,01) и высшим 0,1%-ый уровень (р≤0,001), поэтому в таблицах критических значений обычно приводятся значения критериев, соответствующих уровням статистической значимости р≤0,05 и р≤0,01, иногда - р≤0,001. Для некоторых критериев в таблицах указан точный уровень значимости их разных эмпирических значений. Например, для φ*=1,56 р=О,06.
До тех пор, однако, пока уровень статистической значимости не достигнет р=0,05, мы еще не имеем права отклонить нулевую гипотезу.
Мощность критерия - это его способность выявлять различия, если они есть. Иными словами, это его способность отклонить нулевую гипотезу об отсутствии различий, если она неверна.
Ошибка, состоящая в том, что мы приняли нулевую гипотезу, в то время как она неверна, называется ошибкой II рода.
Вероятность такой ошибки обозначается как β. Мощность критерия - это его способность не допустить ошибку II рода, поэтому:
Мощность= 1—β
Мощность критерия определяется эмпирическим путем. Одни и те же задачи могут быть решены с помощью разных критериев, при этом обнаруживается, что некоторые критерии позволяют выявить различия там, где другие оказываются неспособными это сделать, или выявляют более высокий уровень значимости различий. Возникает вопрос: а зачем же тогда использовать менее мощные критерии? Дело в том, что основанием для выбора критерия может быть не только мощность, но и другие его характеристики, а именно:
|
|
|
а)простота;
б)более широкий диапазон использования (например, по отношению к данным, определенным по номинальной шкале, или по отношению к большим n);
в)применимость по отношению к неравным по объему выборкам;
г)большая информативность результатов.
Вопросы для самопроверки
1. Приведите примеры генеральной совокупности и выборки.
2. Приведите примеры повторной и бесповторной выборок.
3. Преобразуйте признак «Рост» из количественной шкалы в порядковую, а затем в номинальную.
4. Преобразуйте переменную «Качество жилья» из порядковой шкалы в количественную, а затем в номинальную.
5. Объясните, почему «оценка на экзамене» - порядковая, а не количественная переменная.
6. Каким из методов формирования контрольной и экспериментальной группы, на ваш взгляд, необходимо воспользоваться для изучения влияния трудностей обучения в вузе в течение года на массу тела? Почему?
7. Допустим вы сравниваете частоту сердечных сокращений до и после экзамена. Каковы в этом случае нулевая и альтернативная гипотезы? Каковы в данном случае ошибки первого и второго рода?
8. В условиях предыдущего вопроса, каким способом формирования контрольной и экспериментальной группы вы бы воспользовались? Почему?
9. Выберите область вашей будущей специализации. Придумайте эксперимент. Сформулируйте нулевую и альтернативную гипотезу.
10. Как вы считаете, почему за пороговое значение Р принята величина 0,05?
11. Приведите примеры, когда требуется выбрать уровень ошибки первого рода отличный от 0,05 и 0,01?
РАЗДЕЛ III. СТАТИСТИЧЕСКИЕ МЕТОДЫ ОБРАБОТКИ ЭКСПЕРИМЕНТАЛЬНЫХ ДАННЫХ
|
|
|
| Задача | Количественные переменные, имеющие нормальное распределение | Количественные и порядковые переменные | Качественные переменные |
| Описательные статистики | M±S или M±m | Me, 25 и 75 персентиль | % |
| Сравнение двух независимых выборок | Т критерий | U критерий Манна-Уитни | Тест Фишера, c2 |
| Сравнение более двух независимых выборок | Дисперсионный анализ Фишера | Дисперсионный анализ Краскел-Уоллиса | c2 |
| Сравнение двух зависимых выборок | Парный Т критерий | Критерий Вилкоксона | Тест Мак-Немара |
| Изучение взаимосвязи между признаками | Коэффициент корреляции Пирсона | Коэффициент корреляции Спирмена | c2 |
| Предсказать изменение одного значения, если было измерено другое значение | Простая линейная или нелинейная регрессия | Непараметрическая регрессия | Простая логистическая регрессия |
В данной таблице приведены основные методы, использующиеся в биологических исследованиях, в зависимости от задач исследователя. В следующих главах мы постараемся подробно описать области применения, способ расчета и интерпретацию получаемых результатов.
Проверка гипотезы о законе распределения
Большое познавательное значение имеет сопоставление фактических кривых распределения с теоретическими.
Под теоретической кривой распределения понимается графическое изображение ряда в виде непрерывной линии изменения частот в вариационном ряду, функционально связанного с изменением вариантов (значений признака). Теоретическое распределение может быть выражено аналитически - формулой, которая связывает частоты вариационного ряда и соответствующие значения признака. Такие алгебраические формулы носят название законов распределения
Гипотезы о распределениях заключаются в том, что выдвигается предположение о том, что распределение в генеральной совокупности подчиняется какому-то определенному закону. Проверка гипотезы состоит в том, чтобы на основании сравнения фактических (эмпирических) частот с предполагаемыми (теоретическими) частотами сделать вывод о соответствии фактического распределения гипотетическому распределению. Может проводиться и сравнение частостей.
Под гипотетическим распределением необязательно понимается нормальное распределение. Может быть выдвинута гипотеза о биномиальном распределении, распределении Пуассона и т.д. Причина частого обращения к нормальному распределению в том, что в этом типе распределения выражается закономерность, возникающая при взаимодействии множества случайных причин, когда ни одна из них не имеет преобладающего влияния. Закон нормального распределения лежит в основе многих теорем математической статистики, применяемых для оценки репрезентативности выборок, при измерении связей и т. д.
|
|
|
Итак, пусть имеется вариационный ряд. Предположим, что признак Х распределен по некоторому вероятностному закону Р. 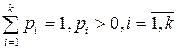
| х | х1 | х2 | .... | xk |
| р | p1 | p2 | ..... | pk |
По теоретическому распределению Р можно построить так называемое выравнивающие или теоретические частоты 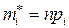 . Если отличия между теоретическими и эмпирическими частотами небольшое, то можно считать, что Х распределен по закону Р.
. Если отличия между теоретическими и эмпирическими частотами небольшое, то можно считать, что Х распределен по закону Р.
χ2 Пирсона
Критерий согласияχ2 разработан достаточно хорошо и поэтому используется достаточно часто. Он основан на сравнении эмпирических частот интервалов группировки с теоретическими (ожидаемыми) частотами, рассчитываемыми по формулам нормального распределения.

Если все эмпирические частоты равны соответствующим теоретическим частотам, то χ2 равно нулю. Очевидно, что чем больше отличаются эмпирические и теоретические частоты, тем χ2 больше; если расхождение несущественно, то χ2 должно быть малым.
Гипотезы -
Н0: Различия между двумя распределениями недостоверны.
H1: Различия между двумя распределениями достоверны.
Существуют табличные значения (см. приложение) для соответствующего числа степеней свободы К и уровня значимости  . По таблице находятся
. По таблице находятся 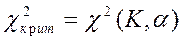 K=k-1-r, где r - число общих характеристик теоретического распределения, принятых равными соответствующим эмпирическим.
K=k-1-r, где r - число общих характеристик теоретического распределения, принятых равными соответствующим эмпирическим.
λ - критерий Колмогорова-Смирнова
Назначение критерия
Критерий λпредназначен для сопоставления двух распределений:
а) эмпирического с теоретическим, например, равномерным или нормальным;
|
|
|
б) одного эмпирического распределения с другим эмпирическим распределением.
Критерий позволяет найти точку, в которой сумма накопленных расхождений между двумя распределениями является наибольшей, и оценить достоверность этого расхождения.
Если в методе χ2 мы сопоставляли частоты двух распределений отдельно по каждому разряду, то здесь мы сопоставляем сначала частоты по первому разряду, потом по сумме первого и второго разрядов, потом по сумме первого, второго и третьего разрядов и т. д. Таким образом, мы сопоставляем всякий раз накопленные к данному разряду частоты.
Гипотезы -
Н0: Различия между двумя распределениями недостоверны (судя по точке максимального накопленного расхождения между ними).
H1: Различия между двумя распределениями достоверны (судя по точке максимального накопленного расхождения между ними).
Если различия между двумя распределениями существенны, то в какой-то момент разность накопленных частот достигнет критического значения, и мы сможем признать различия статистически достоверными. В формулу критерия λвключается эта разность. Чем больше эмпирическое значение λ, тем более существенны различия.
Описательные статистики
Концепция сжатия экспериментальных данных
Графическое представление всей совокупности экспериментальных данных позволяет многими способами осмыслить длинные ряды наблюдений. Тем не менее, построение графиков и таблиц представляет собой только первый шаг при статистическом анализе данных. Следующий шаг — представление результатов в компактной форме, удобной для хранения, сопоставления с другими данными и т. д. При этом желательно, чтобы характерные особенности распределения численностей выражались небольшим числом показателей.
Графические представления распределения численностей, рассмотренные нами ранее, очень существенно отличаются друг от друга. Однако у всех этих графиков существуют и общие характерные особенности, которые позволяют их сравнивать между coбой.
Прежде всего, видно, что все распределения группируются относительно некоторого центра. Для измерения положения этого центра существует группа показателей, носящих название мер центральной тенденции. К ним относятся средние (среднее арифметически среднее геометрическое, среднее гармоническое), мода и медиана.
Другой характерной особенностью распределений численностей является разброс экспериментальных значений относительно центра распределения. Количественная оценка этого разброса осуществляется с помощью мер рассеяния, важнейшими из которых являются размах, дисперсия, среднеквадратическое отклонение и коэффициент вариации.
|
|
|
Визуальный анализ графических изображений показывает, что некоторые распределения асимметричны, т. е. по обе стороны от центра расположено неравное количество значений, причем асимметрия может быть как право-, так и левосторонней. Наконец, графики некоторых распределений более заострены, а других — уплощены. Эти характерные особенности распределений экспериментальных данных — скошенность и островершинность — также могут быть описаны с помощью показателей асимметрии и эксцесса (островершинности).
Оказывается, что для описания практически любого встречающегося на практике распределения численностей достаточно этих четырех групп мер: показателей центральной тенденции, показателей рассеяния (вариации), показателей асимметрии, показателей эксцесса, вся совокупность которых получила название «статистик свертки».
Показатели центральной тенденции. Средние.
В отличие от индивидуальных числовых характеристик средние величины обладают большей устойчивостью, способностью характеризовать целую группу одним (средним) числом.
В зависимости от того, как распределены исходные данные - в равно- или неравноинтервальный вариационный ряд, для их характеристики применяют разные средние величины. Именно при распределении собранных данных в неравноинтервальный вариационный ряд более подходящей обобщающей характеристикой изучаемого объекта служит так называемая плотность распределения, т. е. отношение частот или частостей к ширине классовых интервалов. Кроме того, числовыми характеристиками таких рядов могут служить средние из абсолютных или относительных показателей плотности распределения. Средняя плотность показывает, сколько единиц данной совокупности приходится в среднем на интервал, равный единице измерения учитываемого признака.
В качестве статистических характеристик равноинтервальных вариационных рядов применяют средние величины.
Средняя арифметическая. Этот показатель является центром распределения, вокруг которого группируются все варианты статистической совокупности. Средняя арифметическая может быть простой и взвешенной. Простую арифметическую определяют как сумму всех членов совокупности, деленную на их общее число.

Когда отдельные варианты повторяются, среднюю арифметическую вычисляют по формуле:  и называют взвешенной средней.
и называют взвешенной средней.
Имеется распределение учета численности косуль за апрель 2003г. Требуется вычислить среднее количество косуль за учет.
| Число косуль | 0 | 1 | 2 | 3 | 4 | 5 | Итого 30 |
| Число учетов | 3 | 7 | 10 | 4 | 3 | 3 |
X=(7+20+12+12+15)/30=66/30=2.02.
В биологических науках среднюю арифметическую принято обозначать как М.
Средняя арифметическая обладает рядом важных свойств.
1. Если каждую варианту статистической совокупности уменьшить или увеличить на некоторое произвольно взятое положительное число, то и средняя уменьшится или увеличится на это число.
2. Если каждую варианту разделить или умножить на какое-то одно и то же число, то и средняя арифметическая изменится во столько же раз.
3. Сумма произведений отклонений вариант от их средней арифметической на соответствующие им частоты равна нулю.
4. Сумма квадратов отклонений вариант от их средней меньше суммы квадратов отклонений тех же вариант от любой другой величины.
Это свойство среднего имеет приложения в приближенных решениях задач следующего вида. Допустим, на основании достаточно обширного экспериментального материала известны средние характеристики одного и того вида животных или растений, занимающих разные экологические ниши. Экземпляры из разных мест обитания будут, как правило, отличаться по численным значениям некоторых характеристик. Если в распоряжении исследователя оказалась одна или несколько особей, для которых известно, что они взяты из одного какого-то местообитания, но неизвестно, из какого именно, то как решить вопрос об их принадлежности к той или иной экологической нише? (Впервые поставил и решил такую задачу немецкий ихтиолог Ф. Гейнике при изучении принадлежности отдельных особей к той или иной расе сельдей Северного моря. При этом было использовано приведенное выше свойство среднего.)
Как практически его использовать, покажем на следующем примере. Известен пример определения вида по 8 количественным характеристикам измерения черепа. Были найдены отклонения этих характеристик для черепа зайца неизвестного вида от соответствующих средних для зайца-беляка и зайца-русака. Ряды отклонений по абсолютной величине выглядят так: беляка— 1,7; 4,2; 0; 2; 1,8; 3,4; 0,6; 6,1, от русака—2,8; 2,5; 1; 0; 0,8; 2,1; 2,1; 2. Суммы квадратов этих отклонений равны соответственно 60,05 и 28,55, поэтому сделан вывод о том, что неизвестный череп принадлежал зайцу-русаку.
Средняя гармоническая. Эту характеристику в отличие от средней арифметической определяют как сумму обратных значений вариант, деленную на их число. 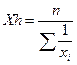
Средняя гармоническая применяется тогда, когда результаты наблюдений обнаруживают обратную зависимость заданных обратными значениями вариант.
5 студентов за 1 час набрали следующее количество жуков: 1 - 10, 2 - 20, 3 - 25, 4 - 30, 5 - 20. Всего 105 штук. Оценим итоги с помощью Х и Хh. X=21 жук.
Xh=5/(1/10+1/20+1/25+1/30+1/20)=18.31.
Разница весьма заметна. Какая же из средних верна. Попробуем с помощью Х вычислить время, затраченное на 1 жука - 60/21=2.86 мин. Верно ли это? Проверим результат. первый студент затратил 6 мин, 2 - 3, 3 - 2.4, 4 - 2, 5 - 3. В среднем получится 3.38мин. Видно, что средняя арифметическая непригодна для определения среднего времени, затрачиваемого на поимку 1 жука.
Средняя квадратическая. Для более точной числовой характеристики мер площади применяется средняя квадратическая.
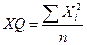 .
.
Имеются три участка земельной площади со сторонами квадрата x1=100м, x2=200м, x3=300м. Если использовать арифметическую среднюю величину, то общая площадь всех участков была бы 3*2002=120000м2. Правильный ответ дает средняя квадратическая величина – 3*2162=140000м2.
Средняя кубическая. В качестве характеристики объемных признаков более точной является средняя кубическая.

Средняя геометрическая. Этот показатель представляет собой корень n-й степени из произведений членов ряда. Средняя геометрическая - более точная характеристика рядов динамики, чем средняя арифметическая. Однако, они, как правило, незначительно отличаются друг от друга. К тому же вычисление средней арифметической проще. Поэтому вместо средней геометрической в качестве приближенной характеристики темпов динамики нередко используют среднюю арифметическую. При этом приходится учитывать, что средняя геометрическая дает хорошие (не искаженные) результаты лишь при наличии геометрической прогрессии, заложенной в самой динамике явления. Это обстоятельство ограничивает область применения средней геометрической.
Количество волков в прошлом году увеличилось в два раза и в этом еще в три раза. Ясно, что за два года численность выросла в 6 раз. Каков средний рост за год? Арифметическая средняя здесь непригодна, ибо если за год численность возросла бы в (2+3)/2=2,5 раз, то за два года численность бы выросла в 2,5*2,5=6,25 раз, а не в шесть раз. Геометрическая средняя дает правильный ответ: Ö6 = 2,45 раз.
Медиана
Медиана (Md) определяется как срединное значение в ранжированном ряду данных. Это значит, что по обе стороны от нее расположено ровно по половине данных. Применительно к кривой распределения медиана представляет такую точку на оси абсцисс, что ордината, проходящая через нее, делит площадь под кривой на две равные части.
Для определения медианы рекомендуется сначала упорядочить данные. Например, для определения значения медианы в массиве {8, 11, 12, 20, 12, 13, 9, 15, 19, 17, 19} необходимо этот массив упорядочить (произвести сортировку по возрастанию): {8, 9, 11, 12, 12, 13, 15, 17, 19, 19, 20}. Медиана будет равна 13 (обозначатся след. образом: Ме = 13). Если количество данных в выборке четное, то медиана равна средней арифметической между двумя центральными значениями. Например, если добавить в последнюю выборку значение 20, и упорядоченный массив примет следующий вид: {8, 9, 11, 12, 12, 13, 15, 17, 19, 19, 20, 20}, то медиана будет равна 14. В подобном случае медиана не может соответствовать ни одному из значений выборки. Медиана может принимать и дробные значения. Например, если мы в последнем примере 15 (одно из двух центральных значений) заменим на 14, то выборка примет вид {8, 9, 11, 12, 12, 13, 14, 17, 19, 19, 20, 20} и медиана будет равна 13,5.
В тех случаях, когда в выборке относительно немного данных, медиана ищется по указанному правилу. Если же данных много и они представлены в виде таблицы распределения численностей, то медиана определяется приближенно в том класс-интервале, для которого накоплено более половины значений анализируемого ряда данных.
Медиана обладает свойством, на котором основывается теоретическое и практическое применение. Это свойство состоит в том, что сумма абсолютных значений отклонений всех значений ряда от его медианы есть величина наименьшая.
Персентили
Персентили - это показатели типа средних по расположению в ряду. Если данные не сгруппированы, они определяются по месту нахождения после того, как все данные будут расположены по восходящей градации по величине изучаемого признака (пятидесятый персентиль известен под именем медианы, в предыдущем примере было показано как он вычисляется). Если данные сгруппированы в равномерно отстоящие друг от друга интервалы, то для получения соответствующих персентилей используется формула:
Pi=LPi+(c/f)*e,
где Lpi - нижняя граница интервала, в котором находится соответствующий персентиль;
с - число случаев, которое требуется прибавить к кумулятивному ряду случаев доперсентильных интервалов, чтобы получить порядковое число персентильного случая;
f - число случаев персентильного интервала;
е - величина персентильного интервала.
В практике обычно пользуются только некоторыми из персентилей: P3, P10, P25, P50, P75, P90, P97. Считается, что если индивидуально наблюдаемый признак находится в границах от Р25 до Р75, то величина его соответствует норме (следовательно, в норму входят 50% всех случаев), если он находится в границах от Р10 до Р25 и от Р75 до Р90, то оценка его соответственно выше или ниже средней (по 15%). Если величина рассматриваемого признака находится в границах от Р3 до Р10 и Р90 до Р97, оценка будет соответственно низкой или высокой (по 7%). В остальных случаях - очень низкая или очень высокая.
Если распределение изучаемого признака отличается от нормального, то при выработке нормативов следует предпочесть метод персентилей.
Имеются следующие данные о истолическом давлении крови у мужчин в возрасте 25-29лет. Необходимо найти персентили P3, P10, P25, P50, P75, P90, P97 и определить интервалы, в границах которых находятся отдельные нормативные группы .
Чтобы выполнить заданную задачу, первоначально находят так называемый начетный ряд (кумулятивные итоги - третий столбец таблицы). Он получается следующим образом, к числу случаев первого интервала прибавляют число случаев второго, к полученному итогу прибавляют число случаев третьего интервала и т.д.
| RR в мм. рт. сб. | Число случаев | Куммулятивные суммы |
| 70-90 | ||
| 90-110 | ||
| 110-130 | ||
| 130-150 | ||
| 150-170 | ||
| 170-190 | ||
| 190-210 | ||
| 210-230 | ||
| 230-250 | ||
| 250-270 |
Затем находим номера соответствующих персентилей по формуле:
Sf/100*Pi, где Sf - сумма всех случаев (в нашем примере 1000), Pi - соответствующий персентиль. По этой формуле номер третьего персентиля будет равен 30=(1000/100)*3, десятого персентиля -100, остальных персентилей соответственно 250, 500, 750, 900, 970.
По куммулятивным суммам определяют, в каком интервале находится каждый из требующихся персентилей. Например, персентиль №30 находится во втором интервале 90-100, №100 - в том же интервале, №250 - в интервале 110-130 и т.д. Затем при помощи формулы 1 находят величины искомых персентилей. В нашем случае: Р3=90+(20/100)*20=94 мм;
Р10=90+(90/100)*20=108 мм; Р25=110+(140/400)*20=117 мм;
Р50=110+(390/400)*20=129.5 мм; Р75=150+(40/100)*20=158 мм;
Р90=190+(20/60)*20=186.67 мм;
Р97=210+(30/30)*20=230 мм;
Следовательно, интервалы нормативов будут следующие:
| Персентиль | Р3 | Р10 | Р25 | Р50 | Р75 | Р90 | Р97 |
| Давление | |||||||
| Очень низкое. Сильно выраженная гипотония | Низкое. Гипото-ния. | Ниже среднего. Слабо выраженная гипотония. | Средние. Нормальные случаи. | Выше среднего. Слабо выраженная гипертония. | Высокие. Гипертония. | Очень высокие. Сильно выраженная гипертония. |
Следует учитывать, что вырабатывать нормативы следует на большом количестве случаев (100-200 и более). Только тогда имеет смысл вычислять персентили.
Мода
Мода (Mo) представляет собой наиболее часто встречающееся в распределении численностей значение. Если к данным таблицы распределения численностей подобрать теоретическую кривую распределения, то мода равна абсциссе точки, имеющей максимальную для этой кривой ординату.
Например, в следующей выборке: {2, 3, 5, 1, 4, 5, 6, 5, 2} модой будет являться значение 5 (обозначатся следующим образом: Мо = 5). Если массив содержит 2 моды, то распределение называется бимодальным. Таким примером может служить выборка { 3, 3, 5, 1, 4, 5, 6, 5, 3 }. Здесь Мо1 = 5, а Мо2 = 3.
Бимодальное или полимодальное распределение могут рассматриваться как признак неоднородности выборки. Например, школьный класс образован в результате механического слияния двух разных классов, и показатели мод интеллекта были изначально различны. После слияния в объединенной выборке профиль интеллекта будет иметь 2 моды.
Существует несколько приближенных способов оценки моды. Один из них состоит в том, что гистограмма тем или иным способом аппроксимируется непрерывной кривой, и затем находится абсцисса, соответствующая максимальной ординате. Она и будет приближенно равна моде.
В симметричных распределениях х, Mo, Md совпадают, в умеренно асимметричных распределениях Md находится между х и Мо на расстоянии от х, равном примерно одной третьей расстояния от х до Мо. На этом и построено приведенное ниже эмпирическое соотношение:
Mo = x-3*(x-Md).
Показатели изменчивости
Изучение и количественное описание изменчивости (вариации) осуществляется различными методами, и можно сказать, что разработанные в математической статистике методы анализа экспериментальных данных в значительной своей части предназначены именно для оценки вариации.
Размах вариации. Это показатель, представляющий собой разность максимальной и минимальной вариант совокупности. Чем сильнее варьирует признак, тем больше размах вариации и наоборот.
Р = Хmax – Xmin
Лимиты и размах вариации - простые и наглядные характеристики варьирования, однако им присущи существенные недостатки: при повторных измерениях одного и того же группового объекта они могут существенно изменяться; кроме того, они не отображают существенные черты варьирования.
Более удобной характеристикой вариации мог бы служить показатель, который строится на основании отклонений вариант от их средней. Сумма таких отклонений, взятая без учета знаков и отнесенная к числу наблюдений, называется средним линейным отклонением.
Дисперсия и ее свойства. Несмотря на явное преимущество среднего линейного отклонения перед лимитами и размахом вариации, этот показатель не получил широкого распространения на практике. Наиболее подходящим оказался показатель, построенный не на отклонениях вариант от их средних, а на квадратах этих отклонений, его называют дисперсией (рассеяние) и выражают формулой  .
.
Ценность дисперсии заключается в том, что, являясь мерой варьирования числовых значений признака вокруг их средней арифметической, она измеряет и внутреннюю изменчивость значений признака, зависящую от разностей между наблюдениями. Преимущество дисперсии перед другими показателями вариации состоит также в том, что она разлагается на составные компоненты, позволяя тем самым оценивать влияние различных факторов на величину учитываемого признака.
Вместе с тем установлено, что рассчитываемая по формуле дисперсия оказывается смещенной по отношению к своему генеральному параметру на величину, равную n/n-1. Чтобы получить несмещенную дисперсию, нужно в формулу ввести в качестве множителя поправку на смещенность, называемую поправкой Бесселя. В результате  Разность n-1 называют числом степеней свободы, под которым понимают число свободно варьирующих единиц в составе численно ограниченной статистической совокупности.
Разность n-1 называют числом степеней свободы, под которым понимают число свободно варьирующих единиц в составе численно ограниченной статистической совокупности.
Дисперсия обладает рядом важных свойств, из которых необходимо выделить следующие.
1. Если каждую варианту совокупности уменьшить или увеличить на одно и то же постоянное число, то дисперсия не изменится.
2. Если каждую варианту совокупности умножить или разделить на одно и то же постоянное число А, то дисперсия уменьшится или увеличится в А2 раз.
Среднее квадратичное отклонение (S) Наряду с дисперсией важнейшей характеристикой варьирования является среднее квадратичное отклонение - показатель, представляющий корень квадратный из дисперсии.
Эта величина в ряде случаев оказывается более удобной характеристикой варьирования чем дисперсия, так как выражается в тех же единицах, что и средняя арифметическая.
Коэффициент вариации. Рассмотренные до сих пор показатели изменчивости: размах, дисперсия, стандартное отклонение определяют вариацию в абсолютных единицах, имеют размерность такую же или в квадрате (для дисперсии), как и сама измеряемая величина. При описании распределений численности это удобно, но если есть необходимость сравнить показатели рассеяния двух распределений, данные которых имеют разные размерности, то естественно возникают затруднения. Такие же затруднения возникают иногда даже в тех случаях, когда измеряемые величины имеют одну и ту же размерность. Например, показатели рассеяния в распределениях количества выпавших осадков и роста людей вычислены в сантиметрах. Однако из того, что стандартное отклонение роста людей больше, чем стандартное отклонение выпавших осадков, не следует, что изменчивость в первом случае больше. Меры изменчивости при сравнении показательны лишь в соотношении со средними, от которых измеряют отклонения. Поэтому возникает необходимость в таком показателе рассеяния, который был бы безразмерным и указывал на изменчивость по отношению к среднему, относительно которого вычисляются отклонения. Наиболее часто используемым показателем, удовлетворяющим этим требованиям, является коэффициент вариации  .
.
Из формулы видно, что на величину коэффициента вариации влияет как стандартное отклонение, так и среднее. Причем так как среднее стоит в знаменателе, при стремлении его к нулю коэффициент вариации становится неопределенным. Поэтому для распределений численностей со средними, близкими к нулю, использование коэффициента вариации в качестве показателя изменчивости нежелательно.
Стандартизованные данные
Из информации о конкретном значении признака и знания средней всей совокупности не очевидно относительное положение интересующего нас значения. Тем не менее достаточно часто желательно иметь возможность описать место некоторого значения в совокупности данных. Это можно сделать, измеряя его отклонение от среднего в единицах стандартного отклонения, т. е.  .
.
Величины zi носят название стандартизованных (стандартизированных) величин.
Ясно, что при переходе к стандартизированным данным любое распределение численностей преобразуется в распределение со средним, равным нулю, и единичной дисперсией.
Стандартизованные данные, как и коэффициент вариации, являются безразмерными величинами, поэтому с их помощью можно сравнивать между собой распределения численностей, имеющие разную размерность.
Показатели асимметрии и эксцесса
При анализе распределения численностей значительный интерес представляет оценка отклонения данного распределения от симметричного, или, иначе говоря, его скошенность. Степень скошенности (асимметрия) является одним из наиболее важных свойств распределения численностей. Существует целый ряд статистических показателей, предназначенных для вычисления асимметрии. Все они отвечают, как минимум, двум требованиям, предъявляемым к любому показателю скошенности: он должен быть безразмерным и равным нулю, если распределение симметрично.

Из этой формулы следует, что распределения, скошенные влево, имеют положительную асимметрию, а скошенные вправо — отрицательную. Естественно, что для симметричных распределений, для которых среднее и медиана совпадают, асимметрия равна нулю.
Известно, что величина As, определяемая по формуле, находится в интервале [-3,3]. Но практически эта величина очень редко достигает своих крайних значений, и для умеренно асимметричных одновершинных распределений она по модулю обычно меньше единицы.
Показатель асимметрии может быть использован не только для формального описания распределения численностей, но и для содержательной интерпретации полученных данных.
В самом деле, если наблюдаемый нами признак формируется под воздействием большого числа независимых друг от друга причин, каждая из которых вносит относительно небольшой вклад в величину этого признака, то в соответствии с некоторыми теоретическими предпосылками, обсуждавшимися в разделе по теории вероятностей, вправе ожидать, что получаемое в результате эксперимента распределение численностей будет симметричным. Однако если для экспериментальных данных получена значительная величина асимметрии (большая по абсолютной величине, чем 0,5), то можно предположить, что условия, указанные выше, не соблюдаются.
В этом случае имеет смысл предположить либо существование какого-то одного или двух факторов, вклад которых в формирование наблюдаемой в эксперименте величины существенно больше, чем остальных, либо постулировать наличие специального механизма, отличного от механизма независимого влияния множества причин на величину наблюдаемого признака.
Так, например, если изменения интересующей нас величины, соответствующие действию некоторого фактора, пропорциональны самой этой величине и интенсивности действия причины, то получаемое при этом распределение будет всегда скошено влево, иметь положительную асимметрию. С таким механизмом сталкиваются, например, биологи, оценивая величины, связанные с ростом растений и животных.

Другой способ оценки асимметрии основан на методе моментов.
 .
.
Таким образом, мера скошенности представляет собой среднее значение стандартизованных данных, возведенных в куб.
Показатели асимметрии, вычисленные по разным формулам, отличаются друг от друга по величине, но одинаково указывают на характер скошенности. В пакетах прикладных программ для статистического анализа при расчете асимметрии используют последнюю формулу.
Эксцесс
Итак, мы рассмотрели три из четырех групп показателей, с помощью которых описываются распределения числен
|
|
|
