 |


Подходы к составлению компьютерных программ контроля
|
|
|
|
Здесь будут рассмотрены особенности подходов к созданию набора контрольных заданий для организации компьютерного контроля знаний. Такие наборы часто именуются тестами (предметно-ориентированными тестами), хотя между набором заданий и тестом имеются существенные отличия. Вопрос о том, при выполнении каких условий набор можно считать тестом, широко обсуждался в журнале «Вопросы тестирования в образовании». В частности, сошлюсь на обстоятельную статью А.И.Самыловского [Самыловский А.И., 2001]. Замечу лишь, что набор заданий, претендующий на наименование теста, должен, по меньшей мере, удовлетворять требованиям валидности и надежности. Для проверки претензий набора заданий на тест, существенную роль играют статистические испытания. Но педагогические статистические испытания почти невозможно производить в однородных условиях. Это обусловлено не только неправомерностью повторных предъявлений одних и тех же заданий одному и тому же составу проверяемых, но и вообще теоретической невозможностью обеспечить статистическую устойчивость (повторяемость) педагогических экспериментов. Тем не менее, выводы и методы теории статистки можно использовать в педагогике. Сошлюсь здесь на известную книгу Дж.Гласса и Дж.Стэнли «Статистические метолы в педагогике и психологии» [Гласс Дж., Стэнли Дж., 1976].
Возможны несколько подходов к составлению наборов тестовых заданий, которые могут быть заложены в компьютерную программу. Рассмотрим два известных и один предлагаемый подходы.
А) Традиционный подход
Этот подход подробно описан в работах В.С.Аванесова [Аванесов В.С., 1989; Аванесов В.С., 1991] и книге Г.А.Атанова [Атанов Г.А., 2002] и И.Н.Пустынниковой [Пустынникова И.Н., 2001]. Для полноты представлений, кратко рассмотрю процедуру составления набора заданий без детального представления математических выкладок. При регистрации результатов выполнения каждого из набора заданий в дихотомической системе (успех – единица, неуспех – ноль) принципиальным является вопрос об одинаковой сложности (трудности) предъявляемых заданий, т.е. о составлении набора равнотрудных заданий. Только такой набор может правильно отражать результаты проверки испытуемых. С точки зрения статистики можно представить, что имеется однородная по трудности гипотетическая генеральная совокупность, из которой произведена невозвратная выборка, составляющая данный набор заданий. Поскольку никакой априорной уверенности в составленном так наборе заданий об однородности нет, нужно произвести некоторую селекцию заданий, исключив из набора те, которые имеют «выпадаюшую из ряда» трудность. Как это сделать? Для этого проводится эксперимент, состоящий из предъявления значительной группе учащихся достаточно большого набора заданий. Очень было бы хорошо, чтобы группа была однородна по подготовке. Поскольку такой уверенности также нет, хорошо бы произвести много повторных испытаний с различными группами. Однако, в традиционном подходе по понятным причинам ограничиваются одной группой. По результатам проверки составляется таблица, в которой имеется столбец списка участников, столбцы с перечнем номеров упражнений и результатами испытаний, т.е. нулями и единицами расставленным по строкам списка. Для удобства таблицу дополняют строкой суммарных отметок по столбцам (по каждому упражнению) и столбцом суммарных результатов по каждому испытуемому. Далее эта таблица подвергается «чистке»: из нее удаляются упражнения, «выпадающие» по трудности из ряда остальных. Первоначально производится простое сопоставление результатов для всех упражнений. Если для какого-либо упражнения ответы почти всех испытуемых были равными единице, т.е. результат явно превосходит результаты испытаний для остальных упражнений, значит это упражнение явно легче остальных, обладает малой селективностью и должно быть удалено из перечня. Аналогично, если суммарный результат испытаний некоторого упражнения близок к нулю (имеет малое значение), упражнение слишком трудное. Оно также не селективно, и его также следует удалить.После этого первоначального этапа производится дальнейшая «чистка» таблицы.
|
|
|
|
|
|
Сравниваются результаты, полученные для каждого упражнения (ряд нулей и единиц каждого столбца) с числами последнего столбца, где записаны суммарные данные. Те упражнения, которые не коррелируют с данными последнего столбца, также следует удалить. Мерой сравнения служит коэффициент корреляции Пирсона, который записывается в добавляемой для этого нижней строке таблицы для каждого упражнения. Отбрасываются те задания, коэффициент корреляции для которых меньше по абсолютному значению 0,3 (такова условная норма). На этом чистка не завершается. Следующий этап состоит в вычислении коэффициентов корреляции Пирсона между столбцами таблицы: каждого задания с каждым из всех остальных, т.е. первого столбца с самим собой (это 1), со вторым, третьим и т.д. Второго с первым, вторым и т.д. По этим коэффициентам строится корреляционная матрица. Она квадратная, симметрична, с единицами по главной диагонали.
Далее вычисляются средние коэффициенты корреляции для каждого из заданий (столбцов), которые сравниваются между собой. Из матрицы удаляются те столбцы, для которых средний коэффициент корреляции «выпадает» из ряда, т.е. значения которых не коррелируют с остальными и их коэффициент корреляции меньше 0,3.
В результате получается новая таблица, по которой строится новая корреляционная матрица,– и так до разумных пределов. Полученная окончательная таблица претендует на наименование теста. Ее нужно только проанализировать на надежность. Для этого проверяют, насколько коррелируют между собой суммарные результаты, полученные по отдельным (равным по размерам) частям «очищенной» таблицы, например четным и нечетным столбцам или левой и правой половинами таблицы. Так складываются результаты испытаний для упражнений с нечетными номерами (один столбец) и четными номерами упражнений (второй столбец) и вычисляется коэффициент корреляции Пирсона между этими столбцами. При значении коэффициента корреляции выше 0,8 (такова условная норма) набор заданий можно считать удовлетворяющим требованию надежности.
|
|
|
Описанная процедура позволяет составить набор приблизительно равнотрудных заданий. Правда, нет уверенности в том, что она сохраниться на другом наборе испытуемых, а повторное предъявление тому же набору испытуемых бессмысленно.
Б) Модель Раша
Датским математиком Рашем в 1957 г была предложена модель контроля знаний, описанная в работе В.С.Аванесова и подвергнутая дальнейшему обстоятельному теоретическому исследованию в работах Ю.М.Неймана [Нейман Ю.М., 2001], где сделаны выводы об основных свойствах модели. Некоторые из них, однако, нуждаются в более прозрачном толковании, например такой «…уровень трудности тестовых заданий, измеренный в рамках модели этой модели, также имеет объективный характер, не зависит от уровня подготовленности того контингента, с помощью которого получены оценки трудности заданий». Или такое заключение: «…если, например, уровень подготовленности какого-нибудь испытуемого в рамках модели Раша измерять многократно с помощью различных педагогических тестов разных трудностей, то различие результатов может быть только за счет неизбежных ошибок измерений, но не за счет различия в тестах» (с. 45 работы [Королев М.Ф., Пашков В.А., 1991]). Прямое прочтение этих утверждений может привести к неоправданным выводам, и здесь необходимы пояснения. Представление о свойствах модели Раша я приведу в таком изложении, которое потребует минимального привлечения математических преобразований, но полностью сохраняет свою строгость и делает выводы более прозрачными.
Пусть вероятность того что некоторое случайное событие (например, некоторый успех или выигрыш) произошло, имеет вероятность Р. Тогда можно говорить о шансе на успех (т.е. реализацию этого события), который описывается отношением этой вероятности к вероятности неудачи Q= 1- Р, т.е. Ш=P/Q. Это удобная мера: она определена на множестве рациональных чисел [0-  ), равна нулю (шансов нет), когда равна нулю вероятность и шанс бесконечно велик при вероятности Р=1, т.е. наступления события. Это отвечает интуитивному представлению о шансах на успех. Модель Раша исходит из естественного предположения, что отношение вероятности P выполнить упражнение (успеха) к вероятности Q=1-P его не выполнить пропорционально уровню знаний s испытуемого и обратно пропорционально уровню t трудности выполняемых упражнений, т.е. функция успешности – шанс
), равна нулю (шансов нет), когда равна нулю вероятность и шанс бесконечно велик при вероятности Р=1, т.е. наступления события. Это отвечает интуитивному представлению о шансах на успех. Модель Раша исходит из естественного предположения, что отношение вероятности P выполнить упражнение (успеха) к вероятности Q=1-P его не выполнить пропорционально уровню знаний s испытуемого и обратно пропорционально уровню t трудности выполняемых упражнений, т.е. функция успешности – шанс
|
|
|
P/Q=s/t (*)
Коэффициент пропорциональности в модели принят равным единице, хотя в более общем случае, в числитель и знаменатель можно было бы ввести дополнительно свои коэффициенты пропорциональности. В формуле величины s  [0- ), t [0- ) – некоторые безразмерные рациональные числа, характеризующие соответственно знания и трудность упражнения из произвольного набора упражнений. По самому смыслу это положительные числа. Других ограничений на область их существования не накладывается. Понятно, что знания и трудность не должны быть отрицательными. Правда, не совсем ясно, что означает, выражение: знания или трудность равны числу, например 4,2. Много это или мало, с каким эталонным значением это сравнивать. Обращение к сравнению шансев в какой-то степени преодолевает эти трудности. Обсуждение вопросов о том, как измерять успешность и трудность, используя результаты реальных применений набора тестовых заданий (будем условно его называть тестом), рассмотрено ниже.
[0- ), t [0- ) – некоторые безразмерные рациональные числа, характеризующие соответственно знания и трудность упражнения из произвольного набора упражнений. По самому смыслу это положительные числа. Других ограничений на область их существования не накладывается. Понятно, что знания и трудность не должны быть отрицательными. Правда, не совсем ясно, что означает, выражение: знания или трудность равны числу, например 4,2. Много это или мало, с каким эталонным значением это сравнивать. Обращение к сравнению шансев в какой-то степени преодолевает эти трудности. Обсуждение вопросов о том, как измерять успешность и трудность, используя результаты реальных применений набора тестовых заданий (будем условно его называть тестом), рассмотрено ниже.
Не следует обольщаться простотой приведенной формулы (*). Действительно, как можно подсчитать входящие в нее вероятности? Это можно сделать так. Нужно иметь достаточно обширный набор равнотрудных заданий (одинаковой трудностью t), который можно назвать однородной генеральной совокупностью. Затем случайным образом многократно выбирать из них по одному заданию и предъявлять одному и тому же испытуемому (т.е. обладающему одними и теми же знаниями). Каждый раз регистрировать успех или неуспех выполнения задания. Затем подсчитать число успехов nу и неуспехов nн из полного количества заданий n и взять их отношение. Тогда можно ожидать, что отношение nу /n с ростом n будет стремиться к вероятности Р и приближенно это отношение можно отождествить с этой вероятностью: Р~nу/n, входящей в основную формулу (*). Но те же рассуждения приводят к тому, что приближенно можно считать вероятность неуспеха отношением числа невыполненных заданий к общему числу, т.е. Q ~ nн/(n-nу), где nн – число невыполненных заданий. Отсюда получается приближенное соотношение Ш~nу/nн. Таким образом, если число заданий достаточно велико, то шанс их выполнения каждым испытуемым подсчитывается достаточно просто, как отношение числа успешно выполненных к числу невыполненных равнотрудных заданий. В дальнейшем будем всегда отождествлять вероятность с частотой. В результате подобных испытаний становится известной левая часть равенства (*), которое можно распространить на любое лицо и упражнения любой (но одинаковой) трудности. Обратим внимание на слова: «равнотрудные задания», ибо, если упражнения не одинаковы по трудности, подсчет частоты будет некорректным. Пока оставляем в стороне вопрос о том, как создавать такие однородные по трудности генеральные совокупности и как вычислять значения трудности t и знания s.
|
|
|
Поскольку повторные предъявления одного и того же упражнения должны быть исключены, выборки из гипотетической генеральной совокупности должны являться безвозвратными. Исключаются и повторные предъявления заданий одному испытуемому. Пока оставляем в стороне вопрос о том, как создавать такие однородные по трудности совокупности и как вычислять значения трудности t и знания s. Само по себе определение шанса не представляется задачей интересной, поскольку если даже Ш найдено, для определения знаний s нужно знать еще априори неизвестную величину трудности t или обратно, для определения t нужно знать s.
Простая и естественная формула (*) влечет очень важные последствия и является весьма «сильным» предположением. Ее значимость становится понятной при рассмотрении вопроса о сравнении знаний испытуемых.
Пусть имеются два испытуемых с уровнями знаний s1 и s2, которым предъявляются упражнения трудности t1 и t2 соответственно.
Тогда отношение шансов для них будет
Ш1/Ш2=P1 Q2/P2 Q1=s1 t2 / s2 t1
Предположим, что этими двумя испытуемыми выполняются два задания одинаковой трудности, т.е. при условии t1 = t2. Тогда отношение шансов составит
Ш1/Ш2= s1 / s2.
Для сравнения знаний двух испытуемых им нужно выполнить одни и те же наборы, содержащие упражнения одинаковой трудности (т.е. полученных выборками из одной однородной генеральной совокупности). Далее сравнить шансы двух учащихся, т.е. вычислить отношение Ш1/Ш2. Тогда станет известным искомое отношение знаний s1 / s2
Отсюда следует первый важный вывод: при выполнении заданий одинаковой трудности отношение шансов зависит только от отношения знаний, но не зависит от абсолютного значения трудностей выполняемых заданий. Следовательно, сравнивать знания двух испытуемых можно, предложив им упражнения одинаковой трудности, причем абсолютная трудность не имеет значения: лишь бы задания имели одинаковую трудность. Подчеркну, что генеральные совокупности, из которых делаются выборки, должны быть однородными, хотя сами по себе совокупности могут различаться по трудности.
Итак, последнее отношение отвечает различию в уровне знаний, которое оценивается путем сравнения вероятностей при предъявлении двух одинаковых серий равнотрудных заданий (теста) каждому испытуемому. Попарным сопоставлением можно сравнивать знания нескольких (всех) участников теста, т.е. выполнить ранжирование в группе. Это первый вывод.
Из того же отношения шансов Ш1/Ш2=P1 Q2/P2 Q1=s1 t2 / s2 t1 следует второй важный вывод. Если знания двух испытуемых одинаковы, т.е. s1 = s2, то отношение шансов Ш1/Ш2= t2/ t1, т.е. обратно пропорционально трудностям этих заданий. Значит, чтобы сравнить между собой два задания по трудности нужно предложить выполнить их о дному и тому же лицу (или двум лицам с одинаковыми знаниями). Таким образом, получен рецепт сравнения знаний по трудности. Она одинакова, если отношение шансов для одного испытуемого равно единице. И их отношение равно отношению шансов, найденных из описанного выше мысленного статистического эксперимента.
Однако практические следствия полученных выводов не столь значительны, как это представляется с первого взгляда. Если стоит задача сравнить знания двух учащихся или трудности двух заданий, то нужно знать отношение шансов. А их можно определить только после описанного выше мысленного эксперимента, связанного с вычислением вероятностей успеха или неуспеха. Такие эксперименты должны проводиться с наборами упражнений одинаковой трудности, т.е. требуется предварительный отбор упражнений с одинаковой трудностью или составление однородных (равнотрудных) генеральных совокупностей. Получается нечто вроде замкнутого круга. Это во многом обесценивает важность полученных выводов. Тем не менее, они остаются значимыми, а вместе с тем имеется некоторая практическая ценность модели Раша. Это станет ясным из следующих рассуждений.
Обсудим второй вывод более подробно. Будем считать, что генеральные совокупности, из которых производятся выборки, однородны, т.е. содержат задания одинаковых трудностей. Полученные результаты показывают, что модель Раша может быть использована для сравнения этих трудностей.
Предположим, есть две однородные выборки трудностей tА и tВ. Подвергнем испытаниям на этих выборках одного испытуемого, в результате которого получит шансы ША=РА/QА, и ШВ=РВ/QВ, где частоты отождествлены с вероятностями, т.е. отношениями числа успехов и неуспехов к полному числу выполненных упражнений в каждой выборке. Теперь вычислим отношение ША/ШВ = tВ /tА, поскольку знания одного и того же испытуемого одинаковы (т.е. sА = sВ). Выполнив такой эксперимент со многими испытуемыми или многими выборками из двух генеральных совокупностей, получим ряд значений отношения tВ /tА. Поскольку каждый испытуемый выполняет один и тот же набор одинаковых по трудности упражнений, это отношение должно быть близким к единице, и различия от одного испытуемого к другому могут объясняться случайными ошибками или неоднородностью генеральных совокупностей. Иначе говоря, разброс величин объективно характеризует однородность двух выборок по трудности. Более того, если испытуемых достаточно много, то можно вычислить статистические характеристики неоднородности отношений в выборках по трудности: среднеквадратическое отклонение и даже (при большом числе испытаний) распределение вероятностей. Замечу, что «равнотрудность» упражнений в работе Ю.М.Неймана специально не оговаривается, вследствие чего может быть неправильно понят сделанный там вывод «Она (имеется в виду модель Раша) позволяет объективно измерять соотношения между испытуемым и тестовыми заданиями произвольных уровней трудности» (с. 45 работы [Королев М.Ф., Пашков В.А., 1991]).
Повторюсь: можно для оценки однородности генеральной совокупности провести эксперимент с одним испытуемым, но многими выборками из одной и той же генеральной совокупности. Поскольку знания одинаковы, то отличие отношения трудностей от единицы, характеризует неоднородность совокупности. И здесь можно вычислить различные статистические характеристики неоднородности.
Это важный результат. Если упражнения взяты из одной и той же почти однородной по трудности генеральной совокупности, то получен инструмент, позволяющий устанавливать, насколько эта совокупность действительно однородна. Тем не менее, выполнять отбор однородности с помощью модели Раша трудно, поскольку подсчет шансов требует проведения довольно громоздких статистических испытаний, которые трудно (если не сказать невозможно) провести в сходных условиях. Для выбраковки (чистки) наборов упражнений с целью придания им однородности, следует использовать рассмотренные выше методы традиционного подхода. Еще раз: нельзя с определенностью утверждать, что эксперименты обладают статистической устойчивостью. Впрочем, этим грешат практически все психолого-педагогические эксперименты.
Если стоит задача сравнения шансов участников некоторой группы испытуемых, то модель Раша должна давать одинаковый результат для испытаний независимо от того, какой трудности задания им предъявляются, лишь бы каждый раз они были выборками из однородных по трудности генеральных совокупностей. Иначе говоря, он должен быть одинаков как для упражнений одной трудности, так и любой другой. Но каждый раз всем участникам следует предъявлять задания одинаковых трудностей. Это следует из того, что в сравнительные данные шансов испытуемых трудность не входит.
Практика и интуиция преподавателей подсказывает, что если предложить двум учащимся одинаковое число упражнений вначале простых (легких), а затем трудных, то отношение шансов выполнить их не будет одинаковым: знающий во втором случае покажет лучший результат, чем мало знающий. Однако модель Раша говорит об обратном. Видимо, она дает «разумный» результат, если трудности упражнений, равно как и знаний учащихся различаются не очень сильно. Получен несколько парадоксальный вывод, поскольку почти очевидно (и это показывает практика), что результат сравнения не может не зависеть от того, наборы трудных или легких заданий предлагаются для выполнения. Но это вывод есть следствие самой модели Раша.
Формула шансов означает измерение в шкале отношений. Удобно преобразовать переменные так чтобы перейти к интервальной шкале.
Это делается заменой отношений их логарифмами, причем предпочтительно натуральными. Тогда отношения преобразуются в разность, т.е. ln s/t = lns – ln t.
Вводится в рассмотрение единица измерений на этой шкале. Пусть отношение s/t=e (основанию натуральных логарифмов). Тогда разность lns – ln t= ln s/t= ln e=1. Такая единица называется логитом. При отношении двух величин, равном е, их различие составит 1 логит. Таким образом, получается шкала, в которой можно говорить, что знания двух испытуемых или трудности двух упражнений различаются на столько-то логит (а не во столько-то раз).
Для рассматриваемого случая модели Раша переход к новой интервальной шкале производится введением новых переменных формулами:
 = ln s,
= ln s, 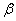 =ln t или s=exp(), t=exp(). Далее все приведенные выше формулы шансов могут быть записаны в переменных и (как это и сделано в статье [Нейман Ю.М., 2001] и в работе [Аванесов В.С., 1989]), но ни к каким новым выводам это не приведет.
=ln t или s=exp(), t=exp(). Далее все приведенные выше формулы шансов могут быть записаны в переменных и (как это и сделано в статье [Нейман Ю.М., 2001] и в работе [Аванесов В.С., 1989]), но ни к каким новым выводам это не приведет.
Поскольку модель Раша направлена на попарное сравнение шансов, удобно ввести сравнение всех с некоторым гипотетическим «эталонным» проверяемым. В качестве такового целесообразно выбрать того, у которого шанс равен 0,5, т.е. вероятность успеха равна половине. Действительно, нелогично сравнивать всех с теми, у кого шансы очень велики и малы. По сравнению с этим проверяемым
Ш/Шэт=(t/s):0,5=2 (t/s).
В соотношении Ш=P/Q=P/(1-P)=s/t введем новую переменную  =s/t.
=s/t.
Тогда
P(s,t)=s/(s+t)= /(1+ ).
Это зависимость вероятности выполнения заданий испытуемым от отношения знаний к трудности =s/t. Она показана на рис. 1. Сравнение производится с испытуемым, для которого Р=0,5 или =1 т.е. когда уровень его знаний равен трудности s=t.

Рис. 1. Зависимость вероятности выполнения заданий испытуемым от отношения знаний к трудности
В) Модель с учетом неоднородности трудности заданий в наборе
Исключить требования, связанные с необходимостью составления наборов заданий одинаковой трудности можно в описываемой (предлагаемой) ниже модели контроля знаний. Ее суть состоит в том, что результаты выполнения задания учитывается не нулями и единицами, а начислением и сбросом баллов, равных (или пропорциональных) априори назначенной трудности заданий с последующим вычислением среднего набранного балла. Результат усреднения переводится (пересчитывается) в оценку в любой выбранной шкале отметок.
Для пояснения способа предположим, что имеется база заданий, охватывающая проверку знаний в рамках темы (курса). Каждому из заданий приписывается та или иная трудность в принятой шкале, например 0 –100 баллов, разбитой для простоты равномерно на 10 участков: 0-10, 10-20 и т.д. Положим вначале, что задания распределены равномерно на шкале трудности, симметрично относительно центрального значения Х (здесь Х= 50 баллов) и заполняют шкалу протяженностью 2А, а учет трудности производится с точностью до 10. Равномерно означает, что число упражнений в пределах каждого участка примерно одинаково. За каждое правильно выполненное задание испытуемому начисляется число баллов, равное трудности задания. За неверное решение – сбрасывается число, дополняющее трудность до 100 баллов. Таким способом учитывается положение: ошибка штрафуется тем выше, чем легче задание и, напротив, тем меньше, чем задание труднее. На рис. 2 показаны две утолщенные перекрещивающиеся опорные прямые, одна из которых соответствует правильным ответам (Верно), другая – неверным (Неверно). Для рассматриваемого частного случая уравнения прямых таковы:
а) для правильных ответов у=х
б) для неверных ответов у= - х+2Х
Задания предъявляются контролируемому лицу в следующем порядке. На каждом нечетном шаге участке А, расположенным, например, справа от значения Х датчиком случайных чисел задания выбирается задание с некоторой случайной трудностью. На каждом четном шаге трудность задания выбирается автоматически симметрично (зеркально) относительно значения Х (рис. 3), т.е. в соответствии с уравнением хk+1= 2Х - хk = 100-хk, где хk трудность нечетного задания (k=1,3,5,…). Использованные задания выбывают из числа предъявлемых в текущем сеансе испытаний.
После каждой пары выполненных заданий подсчитывается среднее значение накопленных баллов, которое в конце сеанса испытаний представляет собой отметку в шкале 100.

Рис. 2
При безошибочном выполнении испытуемым среднее число накопленных баллов равно Х = 50. Для испытуемых, совершающих ошибки, это число всегда меньше значения 50. Результат подсчитанных так многократных предъявлений пар пересчитывается в зачетную отметку в любой удобной шкале, например 100-балльной. Вопрос о переводе баллов в отметку определяется удобством и подробно не обсуждается.
Принятое в описании значение Х=50 определяет среднюю трудность набора заданий, симметрично расположенных на шкале трудностей относительно этого значения. Смещая это значение по шкале трудности, можно составлять наборы разных средних трудностей.
Требование симметрии может быть заменено более простым, а именно, число заданий на четной стороне должно быть не меньше числа заданий на нечетной при равномерном «заселении» сторон. Это всегда можно выполнить добавлением или удалением некоторых заданий. Желательно всегда иметь избыточное число заданий относительно предъявляемых, т.е. базу данных, большую чем число заданий. Если задания для некоторых участков трудности отсутствуют, то при выборе трудности датчиком случайных чисел на очередном нечетном шаге, выбирается задание с трудностью, ближайшей к значению Х.
Понятно, что всякие погрешности в назначении трудностей усредняются, и по мере увеличения числа выполненных заданий значимость в неравенстве трудностей ослабляется.
Описанный способ обладает известной гибкостью. Так, уменьшая наклон опорных прямых (по абсолютному значению), можно регулировать как бы «селективность» системы контроля (на рис. 2? тонкие опорные прямые). Меняя положение Х на шкале трудностей («центра трудности»), можно регулировать (устанавливать) среднюю трудность набора заданий. Меняя наклон прямых – «селективные» свойства – ослаблять зависимость начисляемых и сбрасываемых баллов от трудности заданий. Протяженность участка 2А соответствуют изменению диапазона заселения базы данных заданиями различной трудности. Его можно сделать как узким, так и достаточно протяженным.

Рис. 3
Удобно (хотя не обязательно) иметь общее число заданий в базе значительно превышающем число предъявляемых в сеансе испытаний. В этом случае не составляет труда автоматически задавать среднюю трудность Х испытания и передать требование реализации симметрии самой программе отбора заданий в каждом сеансе испытаний. Число вариантов конкретной реализации описанного алгоритма можно задавать заранее. Если число отобранных для предъявления заданий велико, то вместо описанного выше чередования четных и нечетных номеров, каждое очередное задание можно предъявлять простым случайным выбором. Таким образом, чем больше база данных, тем вся система получается более гибкой и удобной для программирования в виде оболочки, реализующей описанный способ.
Хотя ошибки в назначении трудностей упражнений вследствие самого принципа выбора заданий усредняются и не имеют решающего значения, существуют простые и не очень трудоемкие приемы снижения ошибок изначального назначения трудности каждого задания. Например, можно предложить нескольким преподавателям, ведущим занятия по одному и тому же курсу, расставить упражнения по трудности и затем сопоставлением выбрать наиболее подходящий вариант. Наконец, можно предложить это сделать группе студентов и соответствующим образом обработать результаты. Если данных много, то для корректировки набора применимы методы кластерного анализа.
Описанный метод достаточно гибок в том отношении, что здесь легко корректировать число начисляемых и сбрасываемых баллов на концах диапазона шкалы трудностей. Например, можно ввести корректировочные поправки, заменив близкие к границам отрезки перекрещивающихся прямых некоторыми плавными кривыми для изменения начисляемых и сбрасываемых баллов для очень трудных и очень легких заданий.
|
|
|
