 |


Генеральная и выборочная совокупности.
|
|
|
|
Закон распределения Пуассона
Дискретная случайная величина X имеет закон распределения Пуассона с параметром, если она принимает значения 0, 1,...,m, ... (т.е. бесконечное, но счетное множество значений) с вероятностями (8.2)
где
Математическое ожидание и дисперсия случайной величины, распределенной по закону Пуассона, совпадают и равны параметру этого закона, т.е.: и
Равномерный закон распределения
Непрерывная случайная величина X имеет равномерный закон распределения на отрезке [a,b] если ее плотность вероятностипостоянна на этом отрезке и равна нулю вне его:

Кривая распределения имеет вид

ункция распределения случайной величины X, распределенной по равномерному закону, есть функция вида: 
(8.6)
График функции распределения имеет вид: 
Математическое ожидание случайной величины X, распределенной по равномерному закону, равно: 
(8.7)
Дисперсия случайной величины X, распределенной по равномерному закону, равна: 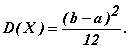
(8.8)
Нормальный закон распределения
Нормальный закон распределения встречается на практике наиболее часто. Нормальный закон распределения является предельным законом для многих других законов распределения при определенных условиях.
Непрерывная случайная величина X имеет нормальный закон распределения (или закон Гаусса) с параметрами и, если ее плотность вероятности имеет вид:

Математическое ожидание случайной величины X, распределенной по нормальному закону, равно (воспользуемся выражением (4.11), т.к. возможные значения случайной величины X принадлежат всей числовой оси): 
Дисперсия случайной величины X, распределенной по нормальному закону, равна (воспользуемся выражением (7.6), т.к. возможные значения случайной величины X принадлежат всей числовой оси) 
Среднее квадратическое отклонение случайной величины X, распределенной по нормальному закону, равно (согласно (5.6)) 
Правило трех сигм:
Вероятность того, что случайная величина отклонится от своего математического ожидания на большую величину, чем утроенное среднее квадратичное отклонение, практически равна нулю. Правило справедливо только для случайных величин, распределенных по нормальному закону.
30. Установление закономерностей, которым подчинены массовые случайные явления, основано на изучении методами теории вероятностей статистических данных — результатов наблюдений.
|
|
|
 Первая задача математической статистики — указать способы сбора и группировки статистических сведений, полученных в результате наблюдений или в результате специально поставленных экспериментов.
Первая задача математической статистики — указать способы сбора и группировки статистических сведений, полученных в результате наблюдений или в результате специально поставленных экспериментов.
Вторая задача математической статистики—разработать методы анализа статистических данных в зависимости от целей исследования. Сюда относятся:
а) оценка неизвестной вероятности события; оценка неизвестной функции распределения; оценка параметров распределения, вид которого известен; оценка зависимости случайной величины от одной или нескольких случайных величин и др.;
б) проверка статистических гипотез о виде неизвестного распределения или о величине параметров распределения, вид которого известен.
Современная математическая статистика разрабатывает способы определения числа необходимых испытаний до начала исследования (планирование эксперимента), в ходе исследования (последовательный анализ) и решает многие другие задачи. Современную математическую статистику определяют как науку о принятии решений в условиях неопределенности.
Генеральная и выборочная совокупности.
Пусть требуется изучить совокупность однородных объектов относительно некоторого качественного или количественного признака, характеризующего эти объекты. Например, если имеется партия деталей, то качественным признаком может служить стандартность детали, а количественным—контролируемый размер детали.
|
|
|
Иногда проводят сплошное обследование, т. е. обследуют каждый из объектов совокупности относительно признака, которым интересуются. На практике, однако, сплошное обследование применяют сравнительно редко. Например, если совокупность содержит очень большое число объектов, то провести сплошное обследование физически невозможно. Если обследование объекта связано с его уничтожением или требует больших материальных затрат, то проводить сплошное обследование практически не имеет смысла. В таких случаях случайно отбирают из всей совокупности ограниченное число объектов и подвергаютих изучению. Различают генеральную и выборочную совокупности:
Генеральной совокупностью называют совокупность всех мысленно возможных объектов данного вида, над которыми проводятся наблюдения с целью получения конкретных значений случайной величины, или совокупность результатов всех мыслимых наблюдений, проводимых в неизменных условиях над одной из случайных величин, связанных с данным видом объектов.
Замечание: Часто генеральная совокупность содержит конечное число объектов. Однако если это число достаточно велико, то иногда в целях упрощения вычислений допускают, что генеральная совокупность состоит из бесчисленного множества объектов. Такое допущение оправдывается тем, что увеличение объема генеральной совокупности (достаточно большого объема) практически не сказывается на результатах обработки данных выборки.
Выборочной совокупностью называют часть отобранных объектов из генеральной совокупности.
Объемом совокупности (выборочной или генеральной) называют число объектов этой совокупности. Например, если из 1000 деталей отобрано для обследования 100 деталей, то объем генеральной совокупности N = 1000, а объем выборки п =100.
Число объектов генеральной совокупности N значительно превосходит объем выборки n.
Дискретным вариационным рядом распределения называют ранжированную совокупность вариантов xi с соответствующими им частотами ni или относительными частотами wi.
Интервальным вариационным рядом называют упорядоченную совокупность интервалов варьирования значений случайной величины с соответствующими частотами или относительными частотами попаданий в каждый из них значений величины.
|
|
|
Для построения интервального ряда необходимо:
1. определить величину частичных интервалов;
2. определить ширину интервалов;
3. установить для каждого интервала его верхнюю и нижнюю границы;
4. сгруппировать результаты наблюдении.
Приблизительно число интервалов k можно оценить исходя только из объема выборки n одним из следующих способов:
- по формуле Стержеса: k = 1 + 3,32·lg n;
31. Полигон (для дискретной случайной величины) - ломаная, соединяющая точки (х i, n i — полигон
частот или точки (х i, w i) — полигон относительных частот
Гистограмма — ступенчатая фигура, состоящая из прямоугольников, основаниями которых являются отрезки длиной x i -x i-1, а их высоты равны:
| ni | ||
| n(xi-xi-1) |
Если объем выборки из генеральной совокупности случайной непрерывной величины велик, то прибегают к предварительной группировке данных: размах выборки разбивают на k частичных интервалов J i. Количество интервалов подсчитывается по формуле:
k=log 2 n+1
Подсчитывается, сколько значений из n 1, n 2,...,n m попало в каждый из к интервалов. Вариантами для выборки считают середины этих интервалов.
Эмпирической плотностью распределения выборки:

Эмпирической функцией распределения, построенной по выборке 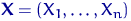 объема
объема 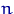 , называется случайная функция
, называется случайная функция  , при каждом
, при каждом  равная
равная

Формула дисперсии в теории вероятностей имеет вид:

То есть дисперсия - это математическое ожидание отклонений от математического ожидания.
На практике при анализе выборок математическое ожидание, как правило, не известно. Поэтому вместо него используют оценку – среднее арифметическое.

где
s2 – выборочная дисперсия, рассчитанная по данным наблюдений,
X – отдельные значения,
X̅ – среднее арифметическое по выборке.
|
|
|
Дабы вернуть дисперсию в реальность, то есть использовать в более приземленных целей, из нее извлекают квадратный корень. Получается так называемое среднеквадратичное отклонение (СКО). Встречаются названия «стандартное отклонение» или «сигма» (от названия греческой буквы). Формула стандартного отклонения имеет вид:

Для получения этого показателя по выборке используют формулу:

Мода — это наиболее часто встречающийся вариант ряда. Мода применяется, например, при определении размера одежды, обуви, пользующейся наибольшим спросом у покупателей. Модой для дискретного ряда является варианта, обладающая наибольшей частотой. При вычислении моды для интервального вариационного ряда необходимо сначала определить модальный интервал (по максимальной частоте), а затем — значение модальной величины признака по формуле:
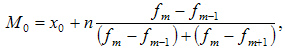
где:
§  — значение моды
— значение моды
§  — нижняя граница модального интервала
— нижняя граница модального интервала
§  — величина интервала
— величина интервала
§  — частота модального интервала
— частота модального интервала
§  — частота интервала, предшествующего модальному
— частота интервала, предшествующего модальному
§ 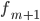 — частота интервала, следующего за модальным
— частота интервала, следующего за модальным
Медиана — это значение признака, которое лежит в основе ранжированного ряда и делит этот ряд на две равные по численности части.
Для определения медианы в дискретном ряду при наличии частот сначала вычисляют полусумму частот  , а затем определяют, какое значение варианта приходится на нее. (Если отсортированный ряд содержит нечетное число признаков, то номер медианы вычисляют по формуле:
, а затем определяют, какое значение варианта приходится на нее. (Если отсортированный ряд содержит нечетное число признаков, то номер медианы вычисляют по формуле:
Ме = (n(число признаков в совокупности) + 1)/2,
в случае четного числа признаков медиана будет равна средней из двух признаков находящихся в середине ряда).
При вычислении медианы для интервального вариационного ряда сначала определяют медианный интервал, в пределах которого находится медиана, а затем — значение медианы по формуле:

32. Нулевая гипотеза — гипотеза, которая проверяется на согласованность с имеющимися выборочными (эмпирическими) данными. Часто в качестве нулевой гипотезы выступают гипотезы об отсутствии взаимосвязи или корреляции между исследуемыми переменными, об отсутствии различий (однородности) в распределениях (параметрах распределений) двух и/или более выборках. В стандартном научном подходе проверки гипотез исследователь пытается показать несостоятельность нулевой гипотезы, несогласованность её с имеющимися опытными данными, то есть отвергнуть гипотезу. При этом подразумевается, что должна быть принята другая, альтернативная (конкурирующая), исключающая нулевую, гипотеза. Используется при статистической проверке
Конкурирующей (альтернативной) называют гипотезу  , которая противоречит нулевой.
, которая противоречит нулевой.
Уровень значимости – это вероятность того, что мы сочли различия существенными, в то время как они на самом деле случайны.
|
|
|
Итак, уровень значимости имеет дело с вероятностью.
Уровень значимости показывает степень достоверности выявленных различий между выборками, т.е. показывает, насколько мы можем доверять тому, что различия действительно есть.
|
|
|
