 |


Современные научные исследования требуют обязательных расчётов уровня статистической значимости результатов.
|
|
|
|
Обычно в прикладной статистике используют 3 уровня значимости.
Уровни значимости
1. 1-й уровень значимости: р ≤ 0,05.
Это 5%-ный уровень значимости. До 5% составляет вероятность того, что мы ошибочно сделали вывод о том, что различия достоверны, в то время как они недостоверны на самом деле. Можно сказать и по-другому: мы лишь на 95% уверены в том, что различия действительно достоверны. В данном случае можно написать и так: P>0,95. Общий смысл критерия останется тем же.
2. 2-й уровень значимости: р ≤ 0,01.
Это 1%-ный уровень значимости. Вероятность ошибочного вывода о том, что различия достоверны, составляет не более 1%. Можно сказать и по-другому: мы на 99% уверены в том, что различия действительно достоверны. В данном случае можно написать и так: P>0,99. Смысл останется тем же.
3. 3-й уровень значимости: р ≤ 0,001.
Это 0,1%-ный уровень значимости. Всего 0,1% составляет вероятность того, что мы сделали ошибочный вывод о том, что различия достоверны. Это — самый надёжный вариант вывода о достоверности различий. Можно сказать и по-другому: мы на 99,9% уверены в том, что различия действительно достоверны. В данном случае можно написать и так: P>0,999. Смысл опять-таки останется тем же.
Уровень значимости – это вероятность ошибочного отклонения (отвержения) гипотезы, в то время как она на самом деле верна. Речь идёт об отклонении нулевой гипотезы Но.
Уровень значимости – это допустимая ошибка в нашем утверждении, в нашем выводе.
33. t-критерий Стьюдента — общее название для класса методов статистической проверки гипотез (статистических критериев), основанных на распределении Стьюдента. Наиболее частые случаи применения t-критерия связаны с проверкой равенства средних значений в двух выборках.
|
|
|
t -статистика строится обычно по следующему общему принципу: в числителе случайная величина с нулевым математическим ожиданием (при выполнении нулевой гипотезы), а в знаменателе — выборочное стандартное отклонение этой случайной величины, получаемое как квадратный корень из несмещенной оценки дисперсии.
Для сравнения средних величин t-критерий Стьюдента рассчитывается по следующей формуле:

где М1 - средняя арифметическая первой сравниваемой совокупности (группы), М2 - средняя арифметическая второй сравниваемой совокупности (группы), m1 - средняя ошибка первой средней арифметической, m2 - средняя ошибка второй средней арифметической.
Критерий Фишера применяется для проверки равенства дисперсий двух выборок. Его относят к критериям рассеяния.
При проверке гипотезы положения (гипотезы о равенстве средних значений в двух выборках) с использованием критерия Стьюдента имеет смысл предварительно проверить гипотезу о равенстве дисперсий. Если она верна, то для сравнения средних можно воспользоваться более мощным критерием.
В регрессионном анализе критерий Фишера позволяет оценивать значимость линейных регрессионных моделей. В частности, он используется в шаговой регрессии для проверки целесообразности включения или исключения независимых переменных (признаков) в регрессионную модель.
В дисперсионном анализе критерий Фишера позволяет оценивать значимость факторов и их взаимодействия.
Критерий Фишера основан на дополнительных предположениях о независимости и нормальности выборок данных. Перед его применением рекомендуется выполнить проверку нормальности.
Заданы две выборки  .
.
Обозначим через  и
и  дисперсии выборок
дисперсии выборок  и
и  ,
,  и
и  — выборочные оценки дисперсий и :
— выборочные оценки дисперсий и :
 ;
;
 ,
,
где
 — выборочные средние выборок и .
— выборочные средние выборок и .
Критерий хи-квадрат — любая статистическая проверка гипотезы, в которой выборочное распределение критерия имеет распределение хи-квадрат при условии верности нулевой гипотезы. Считается, что критерий хи-квадрат — это критерий, который асимптотически верен, то есть, выборочное распределение можно сделать как угодно близким к распределению хи-квадрат путём увеличения размера выборки.
34. Критерий  - Пирсона
- Пирсона
|
|
|
Критерий применяют для проверки гипотезы  о том, что случайная величина
о том, что случайная величина  подчинена закону распределения
подчинена закону распределения  , по выборке
, по выборке  ,
,  . По выборке строят функцию распределения случайной величины .
. По выборке строят функцию распределения случайной величины .
Для этого область изменения значений случайной величины разбивают на интервалы  ,
,  , и определяют частоту попадания значений случайной величины в каждый интервал
, и определяют частоту попадания значений случайной величины в каждый интервал  , а также теоретическую вероятность
, а также теоретическую вероятность 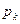 . Затем вычисляют значение случайной величины
. Затем вычисляют значение случайной величины
 ,
,
которая распределена по закону с  степенями свободы.
степенями свободы.
При помощи таблиц находят границу критической области  при уровне значимости
при уровне значимости 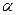 . Если
. Если  , то принимается решение о справедливости основной гипотезы, в противном случае принимается решение о справедливости альтернативы.
, то принимается решение о справедливости основной гипотезы, в противном случае принимается решение о справедливости альтернативы.
35.стр 187
|
|
|
