 |


Пример: слой домена с преобразователями данных (Java)
|
|
|
|
Вообще говоря, чтобы продемонстрировать применение оптимистической автономной блокировки, мне бы вполне хватило одной таблицы базы данных со столбцом, содержащим номер версии, и операторов update и delete, использующих номер версии как часть критерия для выполнения обновлений. Тем не менее я думаю, что вы разрабатываете более сложные приложения, поэтому приведу пример реализации оптимистической автономной блокировки с использованием модели предметной области (Domain Model) и преобразователей данных (Data Mapper). Эта схема позволит затронуть больше типичных моментов, возникающих при внедрении в жизнь оптимистической автономной блокировки.
Вначале следует убедиться, что супертип слоя (Layer Supertype) предметной области может содержать в себе все данные, необходимые для реализации оптимистической автономной блокировки, а именно: сведения о времени изменения, лице, выполнившем изменение, и номере версии.
class DomainObject... private Timestamp modified; private String modifiedBy; private int version;
Все данные хранятся в реляционной базе данных, поэтому каждая таблица также должна содержать в себе эти сведения. Ниже приведена схема таблицы customer, а также реализация стандартного набора SQL-операций CRUD (Create Read Update Delete — создание, чтение, обновление, удаление), необходимых для поддержки оптимистической автономной блокировки.
table customer... create table customer(id bigint primary key, name varchar, createdby varchar, created datetime, modifiedby varchar, modified datetime, version int) SQL customer CRUD... INSERT INTO customer VALUES (?,?,?,?,?,?,?) SELECT * FROM customer WHERE id =? UPDATE customer SET name =?, modifiedBy =?, modified =?, version =? WHERE id =? and version =? DELETE FROM customer WHERE id =? and version =?
При наличии хотя бы нескольких таблиц и объектов домена, несомненно, понадобится создать супертип слоя преобразователей данных и вынести в него все рутинные, повторяющиеся фрагменты объектно-реляционного отображения. Это не только сократит объем работы при написании преобразователей данных, но и позволит применить неявную блокировку (Implicit Lock) для нейтрализации наиболее рассеянных разработчиков, которые могут забыть описать несколько случаев блокировки и тем самым разрушить весь механизм блокирования.
|
|
|
Первое, что необходимо вынести в абстрактный класс преобразователя, — это построение SQL-выражений. Для реализации подобной схемы преобразователям понадобится предоставить определенные метаданные об имеющихся таблицах. Вместо того чтобы конструировать SQL-выражения во время выполнения, их можно создавать путем автоматической генерации кода. Впрочем, я оставлю построение SQL-выражений в качестве домашнего задания для читателей. Как видно из приведенного ниже кода, я сделал несколько предположений относительно имен и расположения столбцов, содержащих данные о последних изменениях строк. Такой прием не совсем подходит для уже существующих таблиц баз данных. В этом случае каждый конкретный преобразователь должен предоставить абстрактному преобразователю определенную порцию метаданных столбцов.
Когда у абстрактного преобразователя появятся SQL-выражения, он сможет управлять выполнением операций CRUD. Покажем, как выглядит метод поиска.
class AbstractMapper... public AbstractMapper(String table, String[] columns) { this.table = table; this.columns = columns; buildStatements(); } public DomainObject find(Long id) { DomainObject obj = AppSessionManager.getSession().getIdentityMap().get(id); if (obj == null) { Connection conn = null; PreparedStatement stmt = null; ResultSet rs = null; try { conn = ConnectionManager.INSTANCE.getConnection(); stmt = conn.prepareStatement(loadSQL); stmt.setLong(1, id.longValue()); rs = stmt.executeQuery(); if (rs.next()) { obj = load(id, rs); String modifiedBy = rs.getString(columns.length + 2); Timestamp modified = rs.getTimestamp(columns.length + 3); int version = rs.getInt(columns.length + 4); obj.setSystemFields(modified, modifiedBy, version); AppSessionManager.getSession().getIdentityMap().put(obj); } else { throw new SystemException(table + " " + id + " does not exist"); } } catch (SQLException sqlEx) { throw new SystemException("unexpected error finding " + table + " " + id); } finally { cleanupDBResources(rs, conn, stmt); } } return obj; } protected abstract DomainObject load(Long id, ResultSet rs) throws SQLException;
|
|
|
Приведу несколько пояснений. Вначале преобразователь проверяет коллекцию объектов (Identity Map), чтобы убедиться, что искомый объект еще не был загружен. Невыполнение этой операции может привести к тому, что в разные моменты бизнес-транзакции пользователь загрузит несколько версий одного и того же объекта. В этом случае приложение поведет себя совершенно непредсказуемым образом, а выполнение всех проверок номеров версий будет окончательно спутано. После получения результирующего множества данных преобразователь передает управление абстрактному методу загрузки, реализованному в каждом конкретном преобразователе, для извлечения значений соответствующих полей и возвращения активизированного объекта. По завершении этой операции преобразователь вызывает метод setSystemFields(), чтобы установить значения номера версии и параметров последних изменений в полях абстрактного объекта домена. Конечно, для заполнения объекта можно было использовать и конструктор, однако это потребовало бы перенести часть логики по сохранению номеров версий в конкретные преобразователи и объекты домена, тем самым ослабив неявную блокировку.
Приведем реализацию метода load() в конкретном классе преобразователя.
class CustomerMapper extends AbstractMapper... protected DomainObject load(Long id, ResultSet rs) throws SQLException { String name = rs.getString(2); return Customer.activate(id, name, addresses); }
Операции обновления и удаления имеют схожую структуру. В каждом из этих случаев для успешного завершения транзакции преобразователю необходимо убедиться, что в результате применения операции к базе данных возвращается количество измененных строк, равное 1. Если строка не была обновлена, пользователь не сможет получить право на применение оптимистической блокировки и преобразователь будет вынужден сгенерировать исключение ConcurrencyException. Как выглядит операция удаления, показано ниже.
class class AbstractMapper... public void delete(DomainObject object) { AppSessionManager.getSession().getIdentityMap().remove(object.getId()); Connection conn = null; PreparedStatement stmt = null; try { conn = ConnectionManager.INSTANCE.getConnection(); stmt = conn.prepareStatement(deleteSQL); stmt.setLong(1, object.getId().longValue()); int rowCount = stmt.executeUpdate(); if (rowCount == 0) { throwConcurrencyException(object); } } catch (SQLException e) { throw new SystemException("unexpected error deleting"); } finally { cleanupDBResources(conn, stmt); } } protected void throwConcurrencyException(DomainObject object) throws SQLException { Connection conn = null; PreparedStatement stmt = null; ResultSet rs = null; try { conn = ConnectionManager.INSTANCE.getConnection(); stmt = conn.prepareStatement(checkVersionSQL); stmt.setInt(1, (int) object.getId().longValue()); rs = stmt.executeQuery(); if (rs.next()) { int version = rs.getInt(1); String modifiedBy = rs.getString(2); Timestamp modified = rs.getTimestamp(3); if (version > object.getVersion()) { String when = DateFormat.getDateTimeInstance().format(modified); throw new ConcurrencyException(table + " " + object.getId() + " modified by " + modifiedBy + " at " + when); } else { throw new SystemException("unexpected error checking timestamp"); } } else { throw new ConcurrencyException(table + " " + object.getId() + " has been deleted"); } } finally { cleanupDBResources(rs, conn, stmt); } }
|
|
|
SQL-оператор, применяемый для проверки номера версии В методе throwConcurrencyException, должен быть известен и абстрактному преобразователю. Последний будет конструировать его вместе с выражениями CRUD. Данное выражение выглядит примерно так, как показано ниже.
checkVersionSQL... SELECT version, modifiedBy, modified FROM customer WHERE id =?
Приведенный код не вполне отражает тот факт, что выполнение бизнес-транзакции охватывает несколько системных транзакций. Важно помнить, что для поддержания согласованности данных применение оптимистической автономной блокировки должно осуществляться в рамках той же системной транзакции, что и сама фиксация изменений. В нашем примере проверка номера версии вставлена в операторы update или delete, поэтому данное условие выполняется автоматически.
Взгляните на пример совместно используемого объекта версии в разделе, посвященном блокировке с низкой степенью детализации (Coarse-Grained Lock). Подобная блокировка достаточно хорошо справляется с некоторыми проблемами несогласованного чтения. Впрочем, обнаружить проблемы несогласованного чтения можно и с помощью простого объекта версии, поскольку он очень удобен для реализации логики оптимистических проверок, например методов increment() или checkVersionlsLatest(). Ниже приведен пример единицы работы (Unit of Work), содержащей проверку на согласованность чтения. Нам пришлось применить довольно строгие меры в виде увеличения номера версии, поскольку не известен уровень изоляции транзакций.
|
|
|
class UnitOfWork... private List reads = new ArrayList(); public void registerRead(DomainObject object) { reads.add(object); } public void commit() { try { checkConsistentReads(); insertNew(); deleteRemoved(); updateDirty(); } catch (ConcurrencyException e) { rollbackSystemTransaction(); throw e; } } public void checkConsistentReads() { for (Iterator iterator = reads.iterator(); iterator.hasNext();) { DomainObject dependent = (DomainObject) iterator.next(); dependent.getVersion().increment(); } }
Обратите внимание, что единица работы выполняет откат системной транзакции, когда обнаруживает нарушение параллелизма (ConcurrencyException). Скорее всего, подобное действие понадобится предусмотреть и для всех остальных исключений, которые могут возникнуть в процессе фиксации изменений. Не забывайте об этом шаге! Вместо использования специальных объектов версий проверку номеров версий можно добавить в интерфейс преобразователя.
Пессимистическая автономная блокировка (Pessimistic Offline Lock)
Дейвид Райе
Предотвращает возникновение конфликтов между параллельными бизнес-транзакциями, предоставляя доступ к данным в конкретный момент времени только одной бизнес-транзакции
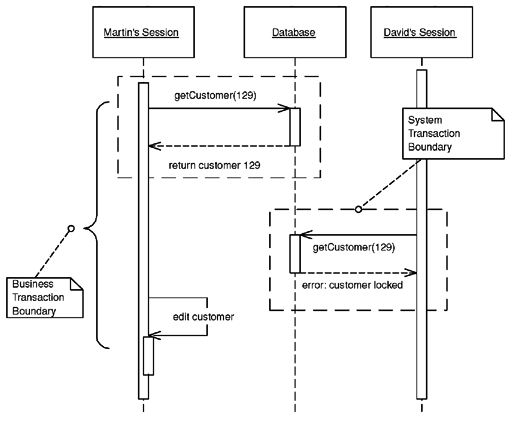
Управление параллельными заданиями в автономном режиме предполагает, что одна бизнес-транзакция может совершать несколько обращений к базе данных. Наиболее простое и очевидное решение — оставить системную транзакцию открытой на все время выполнения бизнес-транзакции. К сожалению, зачастую этот подход неприменим, так как системы транзакций не приспособлены к работе с длинными транзакциями. Поэтому выполнение бизнес-транзакции приходится разбивать на несколько системных транзакций, что требует реализации собственных средств для управления параллельным доступом к данным.
Разумеется, можно попробовать применить оптимистическую автономную блокировку (Optimistic Offline Lock). Однако данное типовое решение имеет ряд недостатков.
Если к одним и тем же данным одновременно осуществляют доступ несколько пользователей, один из них сможет легко зафиксировать выполнение транзакции, а вот другим в сохранении результатов будет отказано. Поскольку наличие конфликта обнаруживается только в конце выполнения бизнес-транзакции, "жертвам" подобной схемы блокирования придется нелегко. Представьте себе, каково тщательно выполнять свою работу только затем, чтобы по ее окончании тебе сообщили, что все пропало. Если подобные неприятности случаются сплошь и рядом, с системой просто откажутся работать.
Пессимистическая автономная блокировка помогает предотвратить возникновение конфликта самым радикальным способом — просто не допускает его. В пессимистической схеме блокирования бизнес-транзакция накладывает блокировку на данные прежде, чем начинает с ними работать, поэтому пользователь может быть уверен, что завершит транзакцию без негативных последствий со стороны параллельных процессов.
|
|
|
Принцип действия
Пессимистическая автономная блокировка реализуется в три этапа: определение необходимого типа блокировок, построение диспетчера блокировки и составление правил применения блокировок. Кроме того, если пессимистическая автономная блокировка используется в качестве дополнения к оптимистической автономной блокировке, понадобится определить типы записей, которые необходимо блокировать.
Первый возможный тип блокировки — это монопольная блокировка записи (exclusive write lock), которая требует наложения блокировки только для редактирования данных. Это дает возможность избежать конфликта, не позволяя двум бизнес-транзакциям одновременно вносить изменения в одну и ту же строку. Данная схема блокирования полностью игнорирует операции чтения, поэтому вполне подходит в том случае, если параллельный сеанс допускает считывание несколько устаревших данных.
Если бизнес-транзакции обязательно нужны самые свежие данные вне зависимости от того, собирается она их редактировать или нет, используйте монопольную блокировку чтения (exclusive read lock). В этом случае бизнес-транзакция накладывает блокировку на данные уже при загрузке последних. Разумеется, применение подобной стратегии жестко ограничивает возможность параллельного доступа к данным. В большинстве корпоративных систем монопольная блокировка записи обеспечивает более высокую степень параллелизма, чем монопольная блокировка чтения.
Третья стратегия сочетает в себе первые два типа блокировки, что ведет к жесткому ограничению доступа, свойственному монопольной блокировке чтения, и одновременному повышению степени параллелизма системы, присущему монопольной блокировке записи. Она называется блокировкой чтения/записи (read/write lock) и имеет немного более сложную схему, чем первые два типа. Данная схема подразумевает определенные отношения между блокировками чтения и записи.
• Блокировки чтения и записи являются взаимоисключающими. Строка базы данных не может быть заблокирована для записи, если другая бизнес-транзакция уже заблокировала ее для чтения. Точно так же строка не может быть заблокирована для чтения, если другая бизнес-транзакция уже установила блокировку на запись.
• Допускаются параллельные блокировки чтения. Наличие хотя бы одной блокировки чтения делает невозможным редактирование строки всеми другими бизнес-транзакциями, поэтому выполнение других параллельных процессов, просматривающих эту строку, вреда не принесет.
Как можно догадаться, последний фактор повышает степень параллелизма системы. Недостатками приведенной стратегии являются сложность ее реализации и большое количество "подводных камней", которые могут заставить экспертов изрядно поломать голову при моделировании системы.
Выбирая необходимый тип блокировки, ориентируйтесь на максимизацию степени параллелизма системы, удовлетворение бизнес-требований и минимизацию сложности кода. Не забывайте также, что выбранная стратегия блокирования должна быть понятна системным аналитикам и проектировщикам предметной области. Блокировка — это не только техническая проблема. Неправильный тип блокировки или блокирование неправильных типов записей могут свести на нет эффективность всей пессимистической автономной блокировки. Неэффективная стратегия блокировки не сможет сдержать натиск бизнес-транзакций или, наоборот, опустит возможность параллельного доступа до уровня однопользовательской системы. Подобную стратегию не спасет даже гениальная техническая реализация. В действительности было бы отнюдь не лишним включить пессимистическую автономную блокировку в модель предметной области.
Определившись с типом блокировок, необходимо создать диспетчер блокировки, работа которого заключается в удовлетворении или отклонении запроса бизнес-транзакции на получение или снятие блокировки. Для этого диспетчеру необходимо знать, что блокируется, а также иметь представление о предполагаемом владельце блокировки, а именно о бизнес-транзакции. Здесь и начинаются первые сложности. Бизнес-транзакция — это не вещь, которая может быть однозначно идентифицирована, поэтому передать бизнес-транзакцию диспетчеру блокировки довольно сложно. Между тем в вашем распоряжении почти наверняка окажется объект сеанса, поэтому концепцию бизнес-транзакции можно подменить концепцией сеанса. Вообще говоря, термины "сеанс" и "бизнес-транзакция" в какой-то степени взаимозаменяемы. Поскольку бизнес-транзакция представляет собой последовательность системных транзакций, выполняемых в пределах одного сеанса, последний может с успехом выполнять роль владельца пессимистической автономной блокировки. Более подробно этот вопрос рассматривается несколько ниже.
В основе диспетчера блокировки лежит обыкновенная таблица, которая отображает блокировки на их владельцев. Простейший вариант диспетчера блокировки может представлять собой оболочку для хэш-таблицы, расположенной в оперативной памяти, или же быть таблицей базы данных. В любом случае в системе должна быть одна и только одна таблица блокировки, поэтому, если она расположена в оперативной памяти, обязательно воспользуйтесь типовым решением единственный элемент (Singleton) [20], которое гарантирует, что в системе будет существовать только один экземпляр соответствующего класса. Если сервер приложений разбит на несколько кластеров, таблица блокировки, расположенная в оперативной памяти, будет работать только в том случае, когда она прикреплена к одному экземпляру сервера. Поэтому в кластеризованных окружениях лучше использовать таблицы блокировки, расположенные в базе данных.
Вне зависимости от реализации (в виде объекта или SQL-оператора, применяемого к таблице базы данных), блокировка должна быть доступна только диспетчеру блокировки. Бизнес-транзакции должны взаимодействовать только с диспетчером, а не с самим объектом блокировки.
Пришло время определить протокол, согласно которому бизнес-транзакции будут взаимодействовать с диспетчером блокировки. В этом протоколе должно быть указано, что и когда блокировать, когда снимать блокировку и как действовать в том случае, если в предоставлении блокировки будет отказано.
Вопрос "что блокировать?" зависит от вопроса "когда блокировать?", поэтому вначале займемся последним. Как правило, бизнес-транзакции накладывают блокировку перед загрузкой данных. В противном случае применение блокировки не сможет гарантировать, что бизнес-транзакция использует последнюю версию необходимых данных. Впрочем, поскольку применение блокировки происходит в рамках системной транзакции, существуют обстоятельства, при которых последовательность загрузки и наложения блокировки не играет роли. В качестве подобных обстоятельств можно рассматривать использование уровня изоляции с поддержкой упорядочиваемых транзакций или уровня изоляции "повторяемое чтение" при наличии определенных типов блокировки. Возможной альтернативой является применение пессимистической автономной блокировки и последующая проверка номера версии объекта по оптимистической схеме. Тем не менее необходимо быть полностью уверенным в наличии последней версии данных, что обычно предполагает наложение блокировки перед их загрузкой.
Так что же все-таки нужно блокировать? Нам кажется, что мы блокируем записи или объекты (или нечто наподобие этого), однако на самом деле блокировка накладывается на идентификатор или первичный ключ, применяемый для обнаружения этих записей или объектов. Данная схема позволяет применять блокировку еще до загрузки самих объектов. Блокирование отдельных объектов хорошо всегда, когда не требует нарушать правило о наличии последней версии объекта после применения блокировки.
В большинстве случаев снятие блокировки осуществляется по окончании бизнес-транзакции. Иногда снимать блокировку допустимо и до окончания транзакции, в зависимости от типа блокировки и вашего намерения повторно использовать тот же объект в рамках текущей транзакции. Тем не менее, если у вас нет особых причин снимать блокировку как можно раньше (например, для обслуживания особенно большого количества параллельных сеансов), придерживайтесь принципа снятия блокировки по окончании бизнес-транзакции.
А что же делать, если в предоставлении блокировки будет отказано? Наиболее простой выход — аварийное завершение бизнес-транзакции. Подобная схема должна удовлетворить пользователя, поскольку об отказе в предоставлении блокировки сообщается довольно рано, когда основная работа еще не сделана. Проектировщик и разработчик должны тщательно следить за тем, чтобы отказ в получении особенно "дефицитных" блокировок осуществлялся как можно раньше. Вообще говоря, по возможности все блокировки следует запрашивать еще до того, как пользователь начнет работу.
Доступ к каждому блокируемому элементу должен быть упорядочен. Если таблица блокировки расположена в оперативной памяти, самый простой способ решения этой проблемы — упорядочить доступ ко всему диспетчеру блокировки с помощью конструкций используемого языка программирования. Все остальные схемы слишком сложны и обсуждаться не будут.
Если таблица блокировки расположена в базе данных, доступ к ней (первое правило!) должен осуществляться в рамках одной системной транзакции. В этом случае вы можете воспользоваться всеми средствами упорядочения доступа, имеющимися в базе данных. При наличии монопольных блокировок чтения или записи упорядочение доступа сводится к простому наложению ограничения уникальности на столбец, содержащий идентификатор блокируемого элемента. Хранение в базе данных блокировок чтения/записи более сложно. Такая стратегия блокирования подразумевает предоставление доступа к таблице блокировки не только для вставки, но и для чтения, а потому требует специальной обработки несогласованного чтения. Полную защиту от подобных ситуаций может гарантировать уровень изоляции с поддержкой упорядочиваемых транзакций. Разумеется, использование таких транзакций по всей системе значительно снизит ее производительность. Впрочем, вы можете применять упорядочиваемые транзакции только для наложения блокировок, а в остальных ситуациях использовать менее строгие уровни изоляции. Кроме того, для управления блокировками можно воспользоваться хранимыми процедурами. Обработка параллельных заданий — занятие далеко не простое, поэтому в спорных моментах не бойтесь полагаться на средства базы данных.
Необходимость упорядочения доступа к таблице блокировки не может не отразиться на скорости работы приложения. В связи с этим стоит подумать о снижении детализации блокирования, поскольку меньшее количество блокировок позволит снизить нехватку производительности. В частности, для устранения соперничества за право доступа к таблице блокировки можно воспользоваться блокировкой с низкой степенью детализации (Coarse-Grained Lock).
Если необходимые данные окажутся заблокированными кем-то другим, пессимистические схемы блокирования системных транзакций наподобие оператора "SELECT FOR UPDATE…" или компонентов сущностей EJB предполагают ожидание до тех пор, пока блокировка не будет снята, а следовательно, допускают возникновение взаимоблокировок. Для большей наглядности механизм возникновения взаимоблокировки можно представить следующим образом. Пусть двум пользователям одновременно понадобились ресурсы А и Б. Если первый пользователь заблокирует ресурс А, а второй заблокирует ресурс Б, обе транзакции будут бесконечно ожидать высвобождения второго ресурса. Поскольку бизнес-транзакция охватывает несколько системных транзакций, подобное ожидание теряет всякий смысл, особенно если учесть, что выполнение бизнес-транзакции может занять около 20 минут, а то и больше. Никто не захочет так долго ждать предоставления блокировки. Это и хорошо, поскольку в противном случае разработчику пришлось бы возиться с кодированием механизма времени ожидания, что отнюдь не просто. Рекомендую придерживаться стандартной схемы, при которой в случае отказа предоставления блокировки диспетчер выдает исключение. Это позволит полностью избавиться от неприятностей, связанных с взаимоблокировками.
И наконец, при управлении блокировкой необходимо позаботиться о механизме времени ожидания, необходимом для обработки утраченных транзакций. Если в процессе выполнения транзакции машина клиента выйдет из строя, транзакция никогда не будет завершена, а следовательно, блокировка не будет снята. Данная проблема особенно критична для Web-приложений, которые слишком часто забывают закрывать должным образом. В идеале обработкой времени ожидания должно заниматься не само приложение, а сервер приложений. Для этого серверы Web-приложений применяют HTTP-сеансы. Механизм времени ожидания может быть реализован путем регистрации объекта, который автоматически высвобождает все блокировки, когда НТТР-сеанс станет недействительным. Вместо этого каждой блокировке можно присвоить временную метку и считать недействительными все блокировки, время жизни которых больше определенного значения.
Назначение
Пессимистическая автономная блокировка применяется тогда, когда вероятность возникновения конфликта между параллельными сеансами достаточно высока. Пользователь никогда не должен переделывать свою работу. К пессимистической схеме блокирования следует обращаться и в том случае, когда стоимость ликвидации последствий конфликта слишком велика независимо от природы последнего. Разумеется, блокирование каждой сущности в системе почти наверняка спровоцирует огромную конкуренцию доступа к данным, поэтому пессимистическая автономная блокировка должна рассматриваться как дополнение к оптимистической автономной блокировке и применяться только тогда, когда без нее действительно не обойтись.
Прежде чем окончательно принимать решение в пользу пессимистической автономной блокировки, подумайте о применении длинных транзакций. Хотя они никогда не считались удачным выбором, в некоторых ситуациях они способны нанести приложению не больше вреда, чем пессимистическая автономная блокировка, а программировать их гораздо легче. Рекомендую провести несколько тестов, чтобы посмотреть, какой из этих приемов наносит меньше урона параллельному доступу к данным.
Не используйте упомянутые приемы, если бизнес-транзакция умещается в рамки одной системной транзакции. Большинство серверов приложений и баз данных поставляются с собственными схемами пессимистического блокирования системных транзакций, в числе которых можно назвать SQL-оператор select for update (для баз данных) и компоненты сущностей EJB (для серверов приложений). Зачем же утруждать себя подбором времени ожидания, областью видимости блокировки и другими подобными вещами, если все это уже есть? Понимание перечисленных типов блокировки способно сыграть существенную роль в реализации пессимистической автономной блокировки. Однако обратите внимание на то, что противоположное утверждение в корне неверно! Материал, изложенный в этой главе, никак не научит вас писать диспетчеры баз данных или системы управления транзакциями. Все схемы автономного блокирования, рассматриваемые в этой книге, предназначены исключительно для систем, имеющих собственные средства управления транзакциями.
Пример: простой диспетчер блокировки (Java)
В этом примере создадим диспетчер блокировки для наложения монопольных блокировок чтения (напомню, что эти блокировки применяются для считывания или записи объекта). Затем продемонстрируем, как использовать диспетчер блокировки для управления бизнес-транзакцией, которая охватывает несколько системных транзакций.
Вначале определим интерфейс диспетчера блокировки.
interface ExclusiveReadLockManager... public static final ExclusiveReadLockManager INSTANCE = (ExclusiveReadLockManager) Plugins.getPlugin(ExclusiveReadLockManager.class); public void acquireLock(Long lockable, String owner) throws ConcurrencyException; public void releaseLock(Long lockable, String owner); public void relaseAllLocks(String owner);
Обратите внимание, что параметр lockable ("блокируемый элемент") имеет тип Long, а параметр owner ("владелец") — тип string. Это сделано по двум причинам. Во-первых, каждая таблица нашей базы данных использует первичный ключ типа Long. Этот ключ уникален в пределах базы данных и поэтому прекрасно подходит на роль блокируемого идентификатора (который должен быть уникален для всех объектов, обрабатываемых таблицей блокировки). Во-вторых, мы рассматриваем Web-приложение, а потому в качестве владельца блокировки удобно использовать идентификатор НТТР-сеанса, являющийся строкой.
В нашем примере диспетчер будет взаимодействовать не с объектом блокировки, а непосредственно с таблицей блокировки, расположенной в базе данных. Обратите внимание, что таблица по имени lock, как и все другие таблицы приложения, создана нами и не является частью внутреннего механизма блокирования базы данных. Получение блокировки эквивалентно вставке в таблицу блокировки новой строки, а высвобождение блокировки — удалению соответствующей строки. Ниже приведена схема таблицы lock и часть реализации диспетчера блокировки.
table lock... create table lock(lockableid bigint primary key, ownerid bigint) class ExclusiveReadLockManagerDBImpl implements ExclusiveLockManager... private static final String INSERT_SQL = "insert into lock values(?,?)"; private static final String DELETE_SINGLE_SQL = "delete from lock where lockableid =? and ownerid =?"; private static final String DELETE_ALL_SQL = "delete from lock where ownerid =?"; private static final String CHECK_SQL = "select lockableid from lock where lockableid =? and ownerid =?"; public void acquireLock(Long lockable, String owner) throws ConcurrencyException { if (!hasLock(lockable, owner)) { Connection conn = null; PreparedStatement pstmt = null; try { conn = ConnectionManager.INSTANCE.getConnection(); pstmt = conn.prepareStatement(INSERT_SQL); pstmt.setLong(1, lockable.longValue()); pstmt.setString(2, owner); pstmt.executeUpdate(); } catch (SQLException sqlEx) { throw new ConcurrencyException("unable to lock " + lockable); } finally { closeDBResources(conn, pstmt); } } } public void releaseLock(Long lockable, String owner) { Connection conn = null; PreparedStatement pstmt = null; try { conn = ConnectionManager.INSTANCE.getConnection(); pstmt = conn.prepareStatement(DELETE_SINGLE_SQL); pstmt.setLong(1, lockable.longValue()); pstmt.setString(2, owner); pstmt.executeUpdate(); } catch (SQLException sqlEx) { throw new SystemException("unexpected error releasing lock on " + lockable); } finally { closeDBResources(conn, pstmt); } }
В приведенном фрагменте кода не показана реализация открытого метода геleaseAllLocks() и закрытого метода hasLock(). Суть метода releaseAllLocks() точно отражена в его имени: он снимает все существующие блокировки указанного владельца. Метод hasLock() обращается к базе данных с запросом о том, не существует ли у владельца блокировки на указанный элемент. При выполнении транзакций нередки ситуации, когда сеанс запрашивает блокировку, которая у него уже есть. Поэтому перед вставкой в таблицу блокировки новой строки метод acquireLock() должен обратиться к таблице и посмотреть, нет ли в ней этой же блокировки. Поскольку таблица блокировки обычно является точкой соперничества за право обладания ресурсами, подобные обращения могут негативно сказаться на производительности приложения. Таким образом, для выполнения проверки на наличие блокировок может понадобиться кэшировать их на уровне сеанса. Будьте очень внимательны, кэшируя блокировки!
Перейдем к созданию простенького Web-приложения, которое будет предоставлять записи о покупателях. Вначале создадим некоторое подобие инфраструктуры для обработки бизнес-транзакций. Слоям, находящимся под уровнем Web-компонентов, необходим объект пользовательского сеанса, поэтому одного лишь HTTP-сеанса будет недостаточно. Чтобы отличить новый объект сеанса от HTTP-сеанса, назовем его сеансом приложения. Класс сеанса приложения будет содержать идентификатор сеанса, имя пользователя и коллекцию объектов (Identity Map) для кэширования объектов, загруженных или созданных во время бизнес-транзакции. Объекты сеанса будут ассоциированы с текущим потоком выполнения в порядке их обнаружения этим потоком.
class AppSession... private String user; private String id; private IdentityMap imap; public AppSession(String user, String id, IdentityMap imap) { this.user = user; this.imap = imap; this.id = id; } class AppSessionManager... private static ThreadLocal current = new ThreadLocal(); public static AppSession getSession() { return (AppSession) current.get(); } public static void setSession(AppSession session) { current.set(session); }
Для обработки запросов к Web-приложению будет применяться контроллер запросов (Front Controller), поэтому нам понадобится определить объект команды. Первое, что должен выполнять объект команды, — указывать на необходимость начала новой бизнес-транзакции или продолжения текущей. Для этого следует соответственно установить новый сеанс приложения или возвратить текущий. Ниже приведено описание абстрактного класса команды, содержащего общие методы по установке контекста бизнес-транзакций.
interface Command... public void init(HttpServletRequest req, HttpServletResponse rsp); public void process() throws Exception; abstract class BusinessTransactionCommand implements Command... public void init(HttpServletRequest req, HttpServletResponse rsp) { this.req = req; this.rsp = rsp; } protected void startNewBusinessTransaction() { HttpSession httpSession = getReq().getSession(true); AppSession appSession = (AppSession) httpSession.getAttribute(APP_SESSION); if (appSession!= null) { ExclusiveReadLockManager.INSTANCE.relaseAllLocks(appSession.getId()); } appSession = new AppSession(getReq().getRemoteUser(), httpSession.getId(), new IdentityMap()); AppSessionManager.setSession(appSession); httpSession.setAttribute(APP_SESSION, appSession); httpSession.setAttribute(LOCK_REMOVER, new LockRemover(appSession.getId())); } protected void continueBusinessTransaction() { HttpSession httpSession = getReq().getSession(); AppSession appSession = (AppSession) httpSession.getAttribute(APP_SESSION); AppSessionManager.setSession(appSession); } protected HttpServletRequest getReq() { return req; } protected HttpServletResponse getRsp() { return rsp; }
Обратите внимание, что при установке нового сеанса приложения мы снимаем все блокировки существующего сеанса. Мы также добавляем класс LockRemover, реализующий интерфейс HttpSessionBindingListener, который будет удалять Все блокировки, принадлежащие сеансу приложения, по истечении срока жизни соответствующего НТТР-сеанса.
class LockRemover implements HttpSessionBindingListener... private String sessionId; public LockRemover(String sessionId) { this.sessionId = sessionId; } public void valueUnbound(HttpSessionBindingEvent event) { try { beginSystemTransaction(); ExclusiveReadLockManager.INSTANCE.relaseAllLocks(this.sessionId); commitSystemTransaction(); } catch (Exception e) { handleSeriousError(e); } }
В нашем примере объекты команд содержат как бизнес-логику, так и логику управления блокировками. Кроме того, каждая команда должна выполняться в рамках одной системной транзакции. Для этого можно модифицировать поведение команды с помощью декоратора [20], представленного объектом TransactionalCommand. Реализуя объекты команд, убедитесь, что все операции по управлению блокировками и вся стандартная бизнес-логика по обработке одного запроса находятся в рамках единой системной транзакции. Методы, определяющие рамки системной транзакции, зависят от контекста развертывания приложения. Откат системной транзакции происходит при генерации исключения ConcurrencyException (а в нашем примере— и всех других исключений). Это позволит предотвратить внесение каких-либо постоянных изменений при возникновении конфликта.
class TransactionalComamnd implements Command... public TransactionalCommand(Command impl) { this.impl = impl; } public void process() throws Exception { beginSystemTransaction(); try { impl.process(); commitSystemTransaction(); } catch (Exception e) { rollbackSystemTransaction(); throw e; } }
Теперь нужно написать сервлет, выполняющий роль контроллера, и конкретные классы команд. Сервлет контроллера добавляет к объектам команд методы управления транзакциями; конкретные классы команд необходимы для установки контекста бизнес-транзакции, выполнения логики домена, а также наложения и снятия блокировок там, где это потребуется.
class ControllerServlet extends HttpServlet... protected void doGet(HttpServletRequest req, HttpServletResponse rsp) throws ServletException, IOException { try { String cmdName = req.getParameter("command"); Command cmd = getCommand(cmdName); cmd.init(req, rsp); cmd.process(); } catch (Exception e) { writeException(e, rsp.getWriter()); } } private Command getCommand(String name) { try { String className = (String) commands.get(name); Command cmd = (Command) Class.forName(className).newInstance(); return new TransactionalCommand(cmd); } catch (Exception e) { e.printStackTrace(); throw new SystemException("unable to create command object for " + name); } } class EditCustomerCommand implements Command... public void process() throws Exception { startNewBusinessTransaction(); Long customerId = new Long(getReq().getParameter("customer_id")); ExclusiveReadLockManager.INSTANCE.acquireLock(customerId, AppSessionManager.getSession().getId()); Mapper customerMapper = MapperRegistry.INSTANCE.getMapper(Customer.class); Customer customer = (Customer) customerMapper.find(customerId); getReq().getSession().setAttribute("customer", customer); forward("/editCustomer.jsp"); } class SaveCustomerCommand implements Command... public void process() throws Exception { continueBusinessTransaction(); Customer customer = (Customer) getReq().getSession().getAttribute("customer"); String name = getReq().getParameter("customerName"); customer.setName(name); Mapper customerMapper = MapperRegistry.INSTANCE.getMapper(Customer.class); customerMapper.update(customer); ExclusiveReadLockManager.INSTANCE.releaseLock(customer.getId(), AppSessionManager.getSession().getId()); forward("/customerSaved.jsp"); }
Описанные команды предотвращают одновременный доступ двух сеансов к одномуи тому же объекту покупателя. Любая другая команда приложения, работающая с объектом покупателя, должна либо применить блокировку, либо работать только с тем объектом, который был заблокирован предыдущей командой в рамках текущей бизнес-транзакции. Поскольку диспетчер блокировки выполняет проверку на наличие существующей блокировки с помощью метода hasLock(), мы могли бы не усложнять свою задачу и применять блокировку для каждой команды. Это бы немного снизило производительность, однако гарантировало наличие блокировки. Более подробно механизмы защиты от неправильного использования блокировок рассматриваются далее в главе.
Как видите, для описания инфраструктуры понадобилось гораздо большее количество кода, чем для реализации самой логики домена. Действительно, внедрение в жизнь пессимистической авт
