 |


Дейвид Раис и Мэттью Фоммел
|
|
|
|
Блокирует группу взаимосвязанных объектов как единый элемент

Довольно часто объекты приходится редактировать в составе группы. Предположим, у вас есть объект покупателя и множество его адресов. В этом случае при необходимости блокировки одного из элементов имеет смысл заблокировать и все остальные. Между тем применение к каждому объекту отдельной блокировки связано с определенными проблемами. Во-первых, разработчику придется писать код, который бы обнаруживал все объекты группы, чтобы их заблокировать. Это не слишком сложно для покупателя и его адресов, однако при наличии большего количества групп блокировки реализация подобного механизма может стать затруднительной. А что, если группы будут иметь более сложную структуру? Если стратегия блокирования подразумевает, что для наложения блокировки объект должен быть загружен (принцип оптимистической автономной блокировки (Optimistic Offline Lock)), блокирование большой группы объектов значительно снизит производительность. В свою очередь, при использовании пессимистической автономной блокировки (Pessimistic Online Lock) наличие большой группы объектов крайне запутывает управление блокировками и повышает конкуренцию за получение доступа к таблице блокировки.
Типовое решение блокировка с низкой степенью детализации накладывает блокировку сразу на группу объектов. Это не только упрощает применение блокировки, но и освобождает от необходимости загружать все члены группы, чтобы заблокировать каждый из них.
Принцип действия
Чтобы реализовать блокировку с низкой степенью детализации, необходимо создать единую точку соперничества за право доступа к группе блокируемых элементов. В этом случае для блокирования всей группы объектов потребуется только одна блокировка. После этого вам понадобится предоставить кратчайший путь для обнаружения точки блокировки, чтобы для ее наложения пришлось идентифицировать (и принеобходимости загрузить) как можно меньше объектов группы.
|
|
|
При использовании оптимистической автономной блокировки для создания единой точки доступа к группе объектов необходимо, чтобы они совместно использовали один и тот же (а не такой же) объект версии (рис. 16.2). Увеличение номера версии приведет к наложению на группу объектов общей блокировки (shared lock). В этом случае для минимизации пути к точке блокировки достаточно, чтобы каждый объект группы указывал на общий объект версии.

Рис. 16.2. Совместное использование объекта версии
Применение общей пессимистической автономной блокировки требует, чтобы все члены группы совместно использовали некий объект наподобие маркера, на который будет накладываться блокировка. Поскольку пессимистическая автономная блокировка часто выступает в качестве дополнения к оптимистической автономной блокировке, на роль блокируемого маркера прекрасно подойдет общий объект версии (рис. 16.3).

Рис. 16.3. Блокирование совместно используемого объекта версии
Эрик Эванс (Eric Evans) и Дейвид Сигель (David Siegel) [15] определяют агрегат (aggregate) как совокупность взаимосвязанных объектов, рассматриваемых с точки внесения изменений как единое целое. У каждого агрегата есть корневой элемент (root), являющийся единственной точкой доступа к объектам этого агрегата, а также граница (boundary), определяющая, какие объекты входят в агрегат. Перечисленные свойства агрегата требуют применения блокировки с низкой степенью детализации, потому что для работы с одним из элементов агрегата необходимо заблокировать и все остальные элементы. Блокирование агрегата представляет собой еще одну форму блокировки с низкой степенью детализации, отличную от общей блокировки. Назовем ее блокировкой корневого элемента (root lock) (рис. 16.4). По определению блокирование корневого элемента распространяется на все элементы агрегата. Таким образом, корневой элемент является единственной точкой соперничества за доступ к группе объектов, входящих в агрегат.
|
|
|

Рис. 16.4. Блокирование корневого элемента
Использование блокирования корневого элемента в качестве блокировки с низкой степенью детализации требует наличия механизма перехода к корневому элементу графа объектов. В этом случае при запросе на получение блокировки для одного из объектов графа механизм блокирования сможет перейти к корневому элементу и заблокировать только его. Для реализации механизма перехода можно воспользоваться прямым соединением каждого объекта агрегата с корневым элементом или же последовательностью промежуточных соединений. В качестве примера реализации этих способов можно рассмотреть иерархию наследования. Очевидно, корневым элементом этого агрегата является родитель верхнего уровня, поэтому каждый элемент иерархии может непосредственно ссылаться на вершину графа. Вместо этого каждый узел графа может ссылаться на своего прямого родителя, а корневой элемент будет достигаться путем последовательного перемещения вверх по таким ссылкам. Последняя стратегия требует загрузки каждого следующего родителя, чтобы определить, есть ли у него свой родитель, что может привести к значительному падению производительности в больших графах объектов. Поэтому для перемещения к корневому элементу необходимо применять загрузку по требованию (Lazy Load). Это позволит не только избежать загрузки ненужных объектов, но и справиться с циклическими ссылками. Не забывайте, однако, что применение загрузки по требованию к одному агрегату может растянуться на несколько системных транзакций, поэтому различные части агрегата могут оказаться несогласованными. Разумеется, это очень и очень плохо.
Обратите внимание, что общая блокировка может применяться и для блокирования агрегата, поскольку блокирование любого объекта агрегата автоматически заблокирует корневой элемент.
|
|
|
Обе реализации блокировки с низкой степенью детализации — в виде общей блокировки или же блокировки корневого элемента — имеют как преимущества, так и недостатки. Применение общей блокировки к записям реляционной базы данных требует выполнения соединений с таблицей версий в каждом операторе select. В свою очередь, последовательная загрузка объектов при перемещении к корневому элементу также может привести к падению производительности. Вообще говоря, сочетание блокировки корневого элемента и пессимистической автономной блокировки удачным не назовешь. К тому времени как вы загрузите все необходимые объекты и доберетесь до корневого элемента, вам может понадобиться перезагрузить несколько объектов, чтобы гарантировать наличие последних версий. И наконец, большие ограничения на выбор реализации накладывает построение системы для работы с существующим источником данных. Сколько бы ни было вариантов реализации, тонкостей их применения еще больше. Убедитесь, что выбранная реализация в точности соответствует потребностям вашего приложения.
Назначение
В большинстве случаев блокировка с низкой степенью детализации применяется для удовлетворения бизнес-требований. Это особенно справедливо при блокировании агрегатов. Представьте себе объект, содержащий коллекцию предметов имущества, сдаваемых в аренду. Скорее всего, вам не захочется допускать ситуации, когда один пользователь редактирует объект аренды, а другой — один из предметов имущества, входящих в коллекцию. Поэтому блокирование объекта аренды или одного из предметов имущества должно приводить к блокированию объекта аренды и всех предметов имущества, входящих в его коллекцию.
Огромным преимуществом использования блокировки с низкой степенью детализации является относительная дешевизна наложения и снятия блокировки, что, несомненно, служит серьезным аргументом в пользу данного типового решения. Общая блокировка может быть применена и к концепции агрегата [15]. Следует, однако, быть осторожным, используя данную схему блокирования для удовлетворения нефункциональных требований, например повышения производительности. Кроме того, реализация блокировки с низкой степенью детализации может привести к неестественным отношениям между объектами.
|
|
|
Пример: общая оптимистическая автономная блокировка (Java)
В данном примере воспользуемся моделью домена с супертипом слоя (Layer Supertype) и преобразователями данных (Data Mapper). Вкачестве постоянного хранилища данных будет выступать реляционная база данных.
Вначале нужно создать класс и таблицу для работы с номерами версий. Для простоты создадим достаточно обширный класс Version, который будет содержать в себе не только значение номера версии, но и статический метод поиска. Обратите внимание, что для кэширования объектов версий, применяемых в текущем сеансе, будет использоваться коллекция объектов (Identity Map). Если блокируемые объекты совместно используют объект версии, они обязательно должны указывать на один и тот же экземпляр последнего. Поскольку класс version является частью модели домена, он совершенно не подходит для размещения в нем кода работы с базой данных. Этот код лучше вынести в слой преобразователей, что вы вполне сможете проделать самостоятельно.
table version... create table version(id bigint primary key, value bigint, modifiedBy varchar, modified datetime) class Version... private Long id; private long value; private String modifiedBy; private Timestamp modified; private boolean locked; private boolean isNew; private static final String UPDATE_SQL = "UPDATE version SET VALUE =?, modifiedBy =?, modified =? " + "WHERE id =? and value =?"; private static final String DELETE_SQL = "DELETE FROM version WHERE id =? and value =?"; private static final String INSERT_SQL = "INSERT INTO version VALUES (?,?,?,?)"; private static final String LOAD_SQL = "SELECT id, value, modifiedBy, modified FROM version WHERE id =?"; public static Version find(Long id) { Version version = AppSessionManager.getSession().getIdentityMap().getVersion(id); if (version == null) { version = load(id); } return version; } private static Version load(Long id) { ResultSet rs = null; Connection conn = null; PreparedStatement pstmt = null; Version version = null; try { conn = ConnectionManager.INSTANCE.getConnection(); pstmt = conn.prepareStatement(LOAD_SQL); pstmt.setLong(1, id.longValue()); rs = pstmt.executeQuery(); if (rs.next()) { long value = rs.getLong(2); String modifiedBy = rs.getString(3); Timestamp modified = rs.getTimestamp(4); version = new Version(id, value, modifiedBy, modified); AppSessionManager.getSession().getIdentityMap().putVersion(version); } else { throw new ConcurrencyException("version " + id + " not found."); } } catch (SQLException sqlEx) { throw new SystemException("unexpected sql error loading version", sqlEx); } finally { cleanupDBResources(rs, conn, pstmt); } return version; }
Класс Version содержит метод для создания нового экземпляра объекта версии. Вставка соответствующей строки в базу данных отделена от создания объекта версии, что позволяет отложить выполнение вставки до тех пор, пока в базу данных не будет добавлен хотя бы один владелец указанного объекта версии. Каждый преобразователь данных нашей предметной области может без опасения вызывать метод вставки объекта версии при вставке соответствующего объекта домена. Перед проведением вставки объект версии проверяет, является ли данная версия новой, чтобы убедиться, что она не будет вставлена дважды.
|
|
|
class Version... public static Version create() { Version version = new Version(IdGenerator.INSTANCE.nextId(), 0, AppSessionManager.getSession().getUser(), now()); version.isNew = true; return version; } public void insert() { if (isNew()) { Connection conn = null; PreparedStatement pstmt = null; try { conn = ConnectionManager.INSTANCE.getConnection(); pstmt = conn.prepareStatement(INSERT_SQL); pstmt.setLong(1, this.getId().longValue()); pstmt.setLong(2, this.getValue()); pstmt.setString(3, this.getModifiedBy()); pstmt.setTimestamp(4, this.getModified()); pstmt.executeUpdate(); AppSessionManager.getSession().getIdentityMap().putVersion(this); isNew = false; } catch (SQLException sqlEx) { throw new SystemException("unexpected sql error inserting version", sqlEx); } finally { cleanupDBResources(conn, pstmt); } } }
Теперь нужно реализовать метод increment(), который будет увеличивать номер версии в соответствующей строке базы данных. Довольно часто объект версии совместно используется несколькими объектами из текущего набора изменений, поэтому, прежде чем увеличить свой номер, объект версии должен убедиться, что он еще не был заблокирован. После обращения к базе данных метод increment() проверяет, действительно ли строка с номером версии была обновлена. Если количество измененных строк равно нулю, метод increment() распознает нарушение параллелизма и выдает соответствующее исключение.
class Version... public void increment() throws ConcurrencyException { if (!isLocked()) { Connection conn = null; PreparedStatement pstmt = null; try { conn = ConnectionManager.INSTANCE.getConnection(); pstmt = conn.prepareStatement(UPDATE_SQL); pstmt.setLong(1, value + 1); pstmt.setString(2, getModifiedBy()); pstmt.setTimestamp(3, getModified()); pstmt.setLong(4, id.longValue()); pstmt.setLong(5, value); int rowCount = pstmt.executeUpdate(); if (rowCount == 0) { throwConcurrencyException(); } value++; locked = true; } catch (SQLException sqlEx) { throw new SystemException("unexpected sql error incrementing version", sqlEx); } finally { cleanupDBResources(conn, pstmt); } } } private void throwConcurrencyException() { Version currentVersion = load(this.getId()); throw new ConcurrencyException("version modified by " + currentVersion.modifiedBy + " at " + DateFormat.getDateTimeInstance().format(currentVersion.getModified())); }
Реализованный приведенным способом метод increment () должен вызываться только в той системной транзакции, в которой происходит фиксация результатов бизнес-транзакции. Флаг is Locked срабатывает таким образом, что увеличение номера версии в более ранних транзакциях приводит к ложному наложению блокировки задолго до выполнения фиксации. Это неправильно, поскольку основная идея оптимистического блокирования заключается именно в том, чтобы накладывать блокировку только во время фиксации результатов.
При использовании оптимистической схемы блокирования может понадобиться проверить базу данных на наличие последней версии объекта в более ранних системных транзакциях. Для этого к классу version можно добавить метод checkCurrent(), который будет просто проверять нужный объект на возможность получения оптимистической автономной блокировки без выполнения каких-либо обновлений.
В предыдущих фрагментах кода не показан метод delete, который вызывает SQL-оператор для удаления объекта версии из базы данных. Если в результате выполнения этого оператора возвращается количество измененных строк, равное нулю, метод выдает исключение ConcurrencyException. Это означает, что при удалении последнего из объектов, использующих данный объект версии, оптимистическая автономная блокировка могла быть не получена, чего никогда не следует допускать. Самое сложное в реализации удаления — определить момент, когда общий объект версии может быть уничтожен. Если объект версии совместно используется элементами агрегата, этот объект нужно удалить после удаления корневого элемента агрегата. В других случаях определить корректный момент удаления объекта версии гораздо сложнее. В качестве возможного решения можно предложить хранение объектом версии количества своих владельцев и удаление объекта, когда это количество достигнет нуля. К сожалению, подобная схема требует разработки довольно сложного объекта версии — настолько сложного, что его может понадобиться реализовать в виде полноценного объекта домена. Это, конечно, не так уж плохо, однако учтите, что полученный объект домена будет отличаться от всех остальных отсутствием номера собственной версии.
Теперь рассмотрим совместное использование объекта версии. Супертип слоя домена содержит поле version, значением которого является не номер версии, а целый объект. Преобразователь данных может установить значение поля version при загрузке соответствующего объекта домена.
class DomainObject... private Long id;; private Timestamp modified; private String modifiedBy; private Version version; public void setSystemFields(Version version, Timestamp modified, String modifiedBy) { this.version = version; this.modified = modified; this.modifiedBy = modifiedBy; }
Вначале рассмотрим создание объектов. В качестве примера воспользуемся агрегатом, состоящим из объекта покупателя (корневой элемент) и его адресов. Метод create объекта Customer будет создавать общий объект версии. Кроме того, у объекта Customer есть метод getAddress(), который создает объект адреса, передавая ему соответствующий объект версии. Преобразователь AbstгасtMapper будет вставлять в базу данных запись о новом объекте версии до вставки записей о соответствующих объектах домена. Напомню: методы объекта версии гарантируют, чтоон будет вставлен в базу данных только один раз.
class Customer extends DomainObject... public static Customer create(String name) { return new Customer(IdGenerator.INSTANCE.nextId(), Version.create(), name, new ArrayList()); } class Customer extends DomainObject... public Address addAddress(String line1, String city, String state) { Address address = Address.create(this, getVersion(), line1, city, state); addresses.add(address); return address; } class Address extends DomainObject... public static Address create(Customer customer, Version version, String line1, String city, String state) { return new Address(IdGenerator.INSTANCE.nextId(), version, customer, line1, city, state); } class AbstractMapper... public void insert(DomainObject object) { object.getVersion().insert();
Перед обновлением или удалением объекта домена преобразователь данных должен увеличить номер соответствующей версии.
class AbstractMapper... public void update(DomainObject object) { object.getVersion().increment(); class AbstractMapper... public void delete(DomainObject object) { object.getVersion().increment();
Поскольку речь идет об агрегате, объект покупателя удаляется вместе со всеми объектамиадресов. Это позволит удалить объект версии сразу же после удаления объектапокупателя.
class CustomerMapper extends AbstractMapper... public void delete(DomainObject object) { Customer cust = (Customer) object; for (Iterator iterator = cust.getAddresses().iterator(); iterator.hasNext();) { Address add = (Address) iterator.next(); MapperRegistry.getMapper(Address.class).delete(add); } super.delete(object); cust.getVersion().delete(); }
Пример: общая пессимистическая автономная блокировка (Java)
Для применения общей блокировки в пессимистической схеме блокирования нужно подобрать некий блокируемый маркер, на который будут ссылаться все объекты взаимосвязанного множества. Как уже отмечалось, будем использовать пессимистическую автономную блокировку в качестве дополнения к оптимистической автономной блокировке, поэтому на роль блокируемого маркера прекрасно подойдет общий объект версии. Весь код для получения общего объекта версии остается тем же, что и в предыдущем примере.
Реализация нашей задачи связана с единственным спорным моментом. Как известно, для получения номера версии необходимо загрузить некоторые объекты. Если после загрузки данных применить пессимистическую автономную блокировку, как можно гарантировать, что в нашем распоряжении находятся самые свежие версии объектов? Самое простое, что можно предпринять в данной ситуации, — увеличить номер версии в той же системной транзакции, в которой происходит получение пессимистической автономной блокировки. Как только системная транзакция будет зафиксирована, пессимистическая блокировка вступит в силу. Таким образом, мы можем быть уверены, что используем последние версии объектов агрегата, независимо от того, в какой момент системной транзакции произошла их загрузка.
class LoadCustomerCommand... try { Customer customer = (Customer) MapperRegistry.getMapper(Customer.class).find(id); ExclusiveReadLockManager.INSTANCE.acquireLock (customer.getId(), AppSessionManager.getSession().getId()); customer.getVersion().increment(); TransactionManager.INSTANCE.commit(); } catch (Exception e) { TransactionManager.INSTANCE.rollback(); throw e; }
В реальных приложениях код увеличения номера версии рекомендуется встраивать вдиспетчер блокировки или по крайней мере снабжать последний декоратором [20], который будет выполнять это увеличение. И разумеется, реальное приложение потребует намного более солидной обработки исключений и управления транзакциями, чем было показано в данном примере.
Пример: оптимистическая автономная блокировка корневого элемента (Java)
В данном примере используются почти все те же решения, что и в предыдущих примерах, включая супертип слоя домена и преобразователи данных. Как и раньше, у нас есть объект версии, однако на сей раз он не является совместно используемым. Данный объект просто реализует метод increment (), чтобы облегчить наложение оптимистической автономной блокировки за пределами преобразователя данных. Кроме того, для отслеживания изменений будет применяться единица работы (Unit of Work).
В качестве примера выбран агрегат, объекты которого связаны отношениями типа "родитель-потомок", поэтому для перехода к корневому элементу будем последовательно перемещаться по ссылкам потомков к вышестоящим родителям. Для этого понадобится немного изменить модель данных и модель домена.
class DomainObject... private Long id; private DomainObject parent; public DomainObject(Long id, DomainObject parent) { this.id = id; this.parent = parent; }
Прежде чем зафиксировать изменения агрегата, отслеживаемые единицей работы, необходимо заблокировать корневой элемент.
class UnitOfWork... public void commit() throws SQLException { for (Iterator iterator = _modifiedObjects.iterator(); iterator.hasNext();) { DomainObject object = (DomainObject) iterator.next(); for (DomainObject owner = object; owner!= null; owner = owner.getParent()) { owner.getVersion().increment(); } } for (Iterator iterator = _modifiedObjects.iterator(); iterator.hasNext();) { DomainObject object = (DomainObject) iterator.next(); Mapper mapper = MapperRegistry.getMapper(object.getClass()); mapper.update(object); } }
Неявная блокировка (Implicit Lock)
Дейвид Раис
Предоставляет инфраструктуре приложения или супертипу слоя право накладывать автономные блокировки
Любая схема блокирования будет приносить пользу только тогда, когда в ее реализации нет "проколов". Стоит разработчику забыть вставить какую-нибудь строку кода, относящуюся к применению блокировки, и вся схема блокирования окажется совершенно бесполезной. Применение блокировки записи вместо блокировки чтения может привести к получению устаревших данных, а неправильное использование номера версии — к нежелательной перезаписи изменений, внесенных кем-то другим. Общее правило гласит: если элемент может быть заблокирован где-нибудь, он должен быть заблокирован везде. Игнорирование отдельной бизнес-транзакцией стратегии блокирования, применяемой в приложении, способно привести к появлению несогласованных данных. Несвоевременное снятие блокировки, разумеется, не приведет к порче данных, однако сведет на нет производительность приложения. Поскольку механизмы управления параллельными заданиями в автономном режиме достаточно сложно тестировать, подобные ошибки могут остаться незамеченными для всех используемых пакетов тестирования.
Пожалуй, наиболее очевидное решение этой проблемы состоит в том, чтобы не дать разработчикам совершить перечисленные ошибки. Выполнением наиболее важных процедур блокирования должны заниматься не разработчики, а само приложение. Таким образом, явное блокирование следует заменить неявным. Поскольку большинство корпоративных приложений в той или иной мере используют сочетание инфраструктуры, супертипов слоя (Layer Supertype) и систем автоматической генерации кода, это предоставляет широкие возможности по реализации неявной блокировки.
Принцип действия
Для реализации неявной блокировки необходимо вынести код, который никак нельзя пропустить при описании схемы блокирования, в инфраструктуру приложения. За неимением лучшего термина будем использовать понятие "инфраструктура" для обозначения совокупности супертипов слоя, классов инфраструктуры и всех других конструкций, обеспечивающих жизнедеятельность приложения (подобно тому как водопровод и системы отопления обеспечивают жизнедеятельность в зданиях и городах). Обеспечить корректное блокирование могут также средства автоматической генерации кода. Несомненно, принцип вынесения кода блокировки в инфраструктуру приложения отнюдь не является революционным открытием. Полагаю, о нем задумывались все те, кому пришлось написать хотя бы несколько повторяющихся фрагментов механизма блокирования. Тем не менее, все воплощения этой идеи, встречавшиеся мне на практике, оказывались довольно слабы, поэтому уделим ей еще немного внимания.
Прежде всего для обеспечения неявной блокировки необходимо составить список процедур, которые являются обязательными в рамках конкретной стратегии блокирования. При использовании оптимистической автономной блокировки (Optimistic Offline Lock) этот список будет содержать такие операции, как сохранение номера версии для каждой строки базы данных, включение проверки номера версии в критерии SQL-операторов update и delete и увеличение номера версии при изменении соответствующего объекта. В свою очередь, при использовании пессимистической автономной блокировки (Pessimistic Offline Lock) список необходимых операций будет включать в себя применение блокировки перед загрузкой каждого необходимого объекта (как правило, это касается монопольной блокировки чтения и части блокировки чтения/записи, применяющейся для считывания объекта) и высвобождение всех блокировок по окончании сеанса или бизнес-транзакции.
Вы, должно быть, обратили внимание, что говоря о пессимистической автономной блокировке, я не упомянул ни одного типа блокировки, применяемого исключительно для редактирования данных, а именно: монопольной блокировки записи и части блокировки чтения/записи, предназначенной только для выполнения записи. Да, эти блокировки обязательно применяются в том случае, когда бизнес-транзакции нужно отредактировать данные. Тем не менее неудачные попытки наложения таких блокировок неявным способом могут привести к ряду проблем. Во-первых, те условия, в которых можно применить неявные блокировки записи (например, регистрация измененного объекта в единице работы (Unit of Work)), не гарантируют аварийного завершения транзакции в самом начале работы пользователя. Приложение не сможет само определить, когда именно нужно применить такие блокировки. Несвоевременное прерывание транзакции в том случае, если предоставление блокировки невозможно, противоречит концепции пессимистической автономной блокировки, согласно которой пользователь не должен переделывать свою работу.
Второй, и столь же важный, факт состоит в том, что блокировки записи значительно ограничивают возможность параллельной работы в системе. В этом случае отказ от неявной блокировки принуждает разработчика задуматься о влиянии блокировок записи на степень параллелизма системы, переводя этот вопрос из чисто технической сферы в область бизнес-требований. Тем не менее нам все-таки нужно гарантировать, что все необходимые блокировки записи будут применены перед внесением соответствующих изменений. Эту проверку можно поручить инфраструктуре приложения. Отсутствие блокировки на момент фиксации изменений является ошибкой программирования и, как минимум, должно привести к отказу подтверждения изменений. Впрочем, ярекомендую пропустить этап подтверждения и сразу же сгенерировать исключение о нарушении параллелизма, поскольку в реальных системах подтверждения могут быть отключены.
Говоря о неявной блокировке, следует сделать несколько предостережений. Ее применение позволяет разработчикам не думать о большей части процедур блокирования, однако не освобождает от необходимости предусмотреть все возможные последствия. Например, если разработчики используют неявную блокировку в пессимистической схеме блокирования, предполагающей ожидание блокировок, они все еще должны позаботиться о предотвращении взаимоблокировок. Как только разработчики перестают задумываться о применении блокировок, их бизнес-транзакции могут начать вести себя совершенно неожиданным образом — вот в чем состоит главный недостаток неявной блокировки.
Для того чтобы механизм неявного блокирования действительно приносил пользу, вынесение кода блокирования в инфраструктуру приложения необходимо реализовать оптимальным образом. Примеры неявного управления блокировками в оптимистической схеме приведены в начале главы. Возможностей удачной реализации неявной блокировки слишком много, чтобы их можно было продемонстрировать в рамках одной главы.
Назначение
Неявную блокировку следует применять во всех приложениях (за исключением, пожалуй, самых простых, не имеющих инфраструктуры). Задумайтесь: риск забыть какую-нибудь блокировку слишком велик, чтобы им можно было пренебречь.
Пример: неявная пессимистическая автономная блокировка (Java)
Рассмотрим систему, использующую монопольную блокировку чтения. Архитектура этой системы включает в себя модель предметной области (Domain Model), а для взаимодействия между объектами домена и реляционной базой данных применяются преобразователи данных (Data Mapper). При использовании монопольной блокировки чтения инфраструктура приложения должна блокировать объект домена, прежде чем позволить бизнес-транзакции совершать какие-либо действия над данным объектом.
Все объекты домена, используемые бизнес-транзакцией, определяются с помощью метода findo соответствующего преобразователя. Данная схема справедлива во всех случаях, независимо от того, как выполняется поиск объекта — непосредственным вызовом метода find () или перемещением по графу объекта. Для реализации неявной блокировки можно применить декоратор [20], чтобы добавить к поведению преобразователя требующуюся функциональность блокирования. Для этого напишем преобразователь LockingMapper, который будет применять блокировку перед попыткой найти объект.
interface Mapper... public DomainObject find(Long id); public void insert(DomainObject obj); public void update(DomainObject obj); public void delete(DomainObject obj);class LockingMapper implements Mapper... private Mapper impl; public LockingMapper(Mapper impl) { this.impl = impl; } public DomainObject find(Long id) { ExclusiveReadLockManager.INSTANCE.acquireLock(id, AppSessionManager.getSession().getId()); return impl.find(id); } public void insert(DomainObject obj) { impl.insert(obj); } public void update(DomainObject obj) { impl.update(obj); } public void delete(DomainObject obj) { impl.delete(obj); }
Поскольку в течение сеанса поиск одного и того же объекта может выполняться несколько раз, перед применением метода поиска диспетчер блокировки должен проверить, нет ли у сеанса существующей блокировки на данный объект. Если бы вместо монопольной блокировки чтения использовалась монопольная блокировка записи, пришлось бы снабдить преобразователь декоратором, выполняющим проверку на наличие существующей блокировки вместо фактического применения последней перед обновлением или удалением соответствующего объекта.
Огромным преимуществом декораторов является то, что объект, к которому они применяются, даже не подозревает об изменении своей функциональности. Ниже показано, как изменяется поведение преобразователей, содержащихся в реестре (Registry).
LockingMapperRegistry implements MappingRegistry... private Map mappers = new HashMap(); public void registerMapper(Class cls, Mapper mapper) { mappers.put(cls, new LockingMapper(mapper)); } public Mapper getMapper(Class cls) { return (Mapper) mappers.get(cls); }
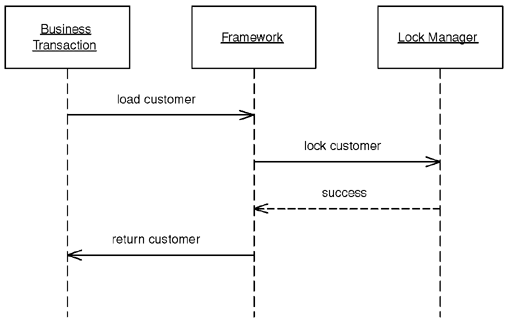
Когда бизнес-транзакция обращается к преобразователю, предполагается, что будет вызван стандартный метод обновления. Фактический же ход событий изображен на рис. 16.5.

Рис. 16.5. Схема работы преобразователя LockingMapper
Глава 17 Типовые решения для хранения состояния сеанса
Сохранение состояния сеанса на стороне клиента (Client Session State)
Сохраняет состояние сеанса на стороне клиента
Принцип действия
Даже если дизайн корпоративной системы полностью ориентирован на использование серверных средств, часть сведений о сеансе (будь то его идентификатор или еще что-нибудь) приходится располагать на стороне клиента. В некоторых приложениях на сторону клиента помещают всю информацию о состоянии сеанса. В этом случае клиент передает серверу все сведения о сеансе вместе с каждым запросом, а сервер возвращает все сведения о сеансе вместе с каждым ответом. Подобная схема позволяет серверу полностью отказаться от сохранения состояний сеанса.
В большинстве случаев для перемещения данных между клиентом и сервером используется объект переноса данных (Data Transfer Object). Он может сериализовать свое содержимое для передачи по сети, тем самым позволяя перемещать весьма сложные структуры данных.
Клиент также нуждается в способе хранения данных. Если речь идет о толстом клиенте, хранение данных может осуществляться за счет собственных структур приложения, например полей его интерфейса (хотя я бы предпочел застрелиться, чем поступать таким образом). Гораздо более удачным решением является хранение состояний сеансов в совокупности невизуализированных объектов, например в модели домена или в самом объекте переноса данных. В любом случае, это не такая уж серьезная проблема.
С HTML-интерфейсами дело обстоит немного сложнее. Существует три основных способа сохранения состояния сеанса на стороне клиента: параметры адреса URL, скрытые поля и файлы cookie.
Использование параметров адреса URL хорошо подходит для работы с небольшим количеством данных. Вообще говоря, для отображения Web-страницы с результатами выполнения запроса все адреса URL принимают то или иное количество параметров сеанса. Разумеется, объем сохраняемой информации существенно ограничен размерами адресов. Тем не менее данный метод прекрасно справляется с двумя-тремя параметрами, поэтому он весьма популярен для хранения на стороне клиента небольших значений наподобие идентификаторов сеансов. Некоторые платформы автоматически перезаписывают адреса URL, добавляя к ним идентификаторы сеансов. Изменение адреса Web-страницы может повлиять на работу закладок, поэтому данную схему хранения не рекомендуется использовать на коммерческих сайтах, связанных с обслуживанием потребителей.
Скрытое поле — это поле, значение которого передается обозревателю, но не отображается на Web-странице. Наличие скрытого поля задается дескриптором вида <input type = "hidden">. Чтобы сохранить данные на стороне клиента, сервер сериализует состояние сеанса, помещает его в скрытое поле при отправке ответа и вновь считывает при получении следующего запроса. Как только что отмечалось, помещаемые в скрытое поле данные должны быть сериализованы. Обычно в качестве формата сериализации применяют XML, хотя, как известно, он слишком "многословен". Вместо этого данные можно сериализовать и в какой-нибудь другой текстовый формат. Не забывайте, однако, что значение скрытого поля скрыто только во время отображения; чтобы добраться к этому значению, достаточно просмотреть исходный код страницы.
Остерегайтесь сайтов, содержащих старые Web-страницы или страницы с фиксированными адресами. Переместившись на них, вы потеряете всю информацию о состоянии сеанса.
Последний, пожалуй наиболее спорный, метод хранения состояний сеанса — это использование файлов cookie, которые автоматически передаются от сервера к клиенту и наоборот. Как и при работе со скрытыми полями, помещаемые в файл cookie данные нужно сериализовать. Объем сохраняемой информации ограничивается размерами файлов — они не должны быть слишком большими. Кроме того, многим пользователям не нравится присутствие файлов cookie, поэтому их отключают, в результате чего сайт перестанет функционировать. Тем не менее в наше время все больше и больше сайтов основаны на использовании файлов cookie, поэтому подобные неприятности случаются нечасто. И конечно, наличие этих файлов не представляет никакой опасности для чисто "домашних" систем.
Не забывайте: файлы cookie безопасны не более чем другие способы хранения информации, а значит, несанкционированное использование данных возможно и здесь. Кроме того, файлы cookie работают только в пределах одного имени домена, поэтому, если ваш сайт разнесен по нескольким доменам, файлы cookie не смогут перемещаться между его частями.
Некоторые платформы автоматически определяют, разрешено ли на стороне клиента использование файлов cookie; если это не так, они применяют перезаписывание адресов URL. Данная схема позволяет легко сохранять на стороне клиента небольшие объемы сведений о сеансе.
Назначение
Типовое решение сохранение состояния сеанса на стороне клиента обладает массой преимуществ. В частности, оно поддерживает использование серверных объектов без состояний, обеспечивая максимальную степень кластеризации и устойчивости к отказам.
Разумеется, при отказе системы клиента все данные будут утеряны, однако в подобных ситуациях большинство клиентов ожидают именно такого исхода.
Количество аргументов против сохранения состояния сеанса на стороне клиента стремительно возрастает с увеличением объема сохраняемой информации. Все перечисленные схемы прекрасно подходят для хранения нескольких полей,
|
|
|
