 |


В. 9. Структурные информационные модели.
|
|
|
|
Структурные информационные модели определяют построение таких важных средств, как базы данных (структурированные хранилища информации) и, соответственно, системы управления базами данных (СУБД).
В тех случаях, когда необходимо переработать большой объем информации, ее нужно структурировать, т.е. выделить в ней элементарные составляющие и их взаимосвязи.
Информационная структура представляет собой упорядоченную систему данных. Наиболее простыми информационными структурами являются списки, таблицы, схемы, графы.
Пример табличного структурирования информации — школьное расписание уроков.
Основными структурными моделями являются иерархическая, сетевая и табличная.
Иерархическая модель представляется в виде дерева, где отдельные элементы объекта являются узлами, а стрелочки показывают связи между этими элементами (рис. 1).

Такая модель обладает следующими свойствами:
1. Иерархия начинается с верхнего узла. Каждый узел имеет характеристики (атрибуты), которые описывают моделируемый объект в данном узле.
2. Чем ниже уровень, тем выше зависимость» узла.
3. Каждый узел имеет только одну связь с более высоким уровнем. Каждый узел может иметь несколько связей с «зависимыми» (более низкими) уровнями.
4. Доступ к любому элементу структуры осуществляется только черед верхний узел по принципу «сверху-вниз».
5. Количество узлов не имеет ограничений.
Например, в биологии весь животный мир рассматривается как иерархическая система (тип, класс, отряд, семейство, род, вид). В информатике используется иерархическая файловая система.
В сетевой модели каждый узел может иметь любое количество связей с другими узлами без соблюдения какой бы то ни было иерархии (рис. 2).
|
|
|
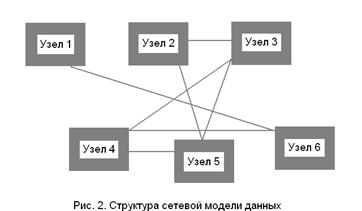
Сетевые информационные модели применяются для отражения таких систем, в которых связь между элементами имеет сложную структуру. Например, различные части сети Интернет (американская, европейская, российская и т.д.) связаны между собой высокоскоростными линиями связи. При этом какие-то части (американская) имеют прямые связи со всеми региональными частями, в то время как другие могут обмениваться информацией между собой только через американскую часть (например, российская и японская).
В табличной модели каждой объект моделируемой системы описывается в виде таблицы с набором атрибутов. Атрибуты, или поля, — это построчные ячейки таблицы. Взаимосвязь между таблицами описывается отношениям между полями.

Взаимосвязь между полями разных таблиц может иметь три вида:
1. «Один к одному». Одному элементу первого объекта соответствует только один элемент второго объекта. Например, конкретному человеку может соответствовать не более одного номера паспорта, а одному номеру паспорта — не более одного конкретною человека.
2. «Один ко многим». Одному элементу первого объекта может соответствовать несколько элементов второго объекта, а одному элементу второго объекта может соответствовать только один элемент первого объекта. Например, в 11 «А» классе школы № 5 может учиться несколько учеников, а конкретный ученик школы № 5 может учиться не более чем в одном классе.
3. «Многие ко многим». Каждому элементу первого объекта может соответствовать множество элементов второго, и каждому элементу второго - множество элементов первого. Например, один предмет школьной программы могут изучать многие ученики, и один ученик может изучать многие предметы школьной программы.



В.10. Кодирование текстовой информации.
Любые числа в памяти компьютера кодируются числами двоичной системы счисления. Для этого существуют правила перевода.
|
|
|
Однако в памяти ЭВМ хранятся и другие виды информации. Компьютер работает с разными видами информации, такими как: текстовая, числовая, графическая, звуковая.
С точки зрения ЭВМ текст состоит из отдельных символов. К числу символов принадлежат не только буквы (заглавные или строчные, латинские или русские), но и цифры, знаки препинания, спецсимволы типа "=", "(", "&" и т.п. и даже пробелы между словами.
Итак, любое математическое выражение или слово состоит из отдельных элементов – символов.
Символы на экране компьютера формируются на основе двух вещей — наборов векторных форм всевозможных символов (они находятся в файлах со шрифтами) и кода, который позволяет выбрать из этого набора векторных форм именно тот символ, который нужно будет использовать.
Кодирование текстовой информации заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111.
Таким образом, человек различает символы по их начертанию, а компьютер - по их коду.
• Формула определения количества информации: N = 2b,
• где N – мощность алфавита (количество символов),
• b – количество бит (информационный вес символа).
В алфавит мощностью 256 символов можно поместить практически все необходимые символы. Такой алфавит называется достаточным.
|
|
|
