 |


Увеличение количества ячеек памяти
|
|
|
|
Увеличение адресного пространства ЗУ в 2k раз требует столько же микросхем памяти и "k" дополнительных линий адреса, к уже имеющимся "n"линиям An+k-1,..An+0, An-1, An-2,... A1, A0. Дополнительные адресные линии An+k-1.. An+0 должны разбивать требуемое адрес- ное поле на 2k неперекрывающихся интервалов, покрываемых объемом памяти каждой отдельной микросхемы. Для решения этой задачи требуется дополнительный дешифратор "k в 2k". Например, если нужен блок ПЗУ емкостью 2K*4, то потребуется 8 микросхем 256*4 типа 541РТ1 и один дешифратор "3 в 8", как показано на рис. 7.20
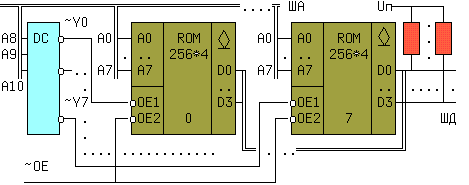
рис. 7.20
Одноименные j- е выходы микросхем с открытым коллектором соединены с общим нагрузочным резистором Rj. Три старших дополнительных бита адреса A10,A9,A8 выбирают одну из восьми микросхем, а восемь младших бит адреса выводят содержимое одной из 256-ти ячеек памяти на шину данных (ШД).Пусть на шину адреса (ША) поступил код A10..A0 = 11000011010 = 61A. На всех выходах дешифратора, кроме шестого (A10..A8 = 110 =6) будет высокий уровень. Нулевой сигнал ~Y6 = 0 на входе ~OE1 шестой микросхемы разрешит прохождение записанной информации на выходы, а код 1 1010 = 1A(HEX) = 26(DEC) на адресных входах A7..A0 извлечет содержимое 26-ой ЯП и поместит его на четыре линии шины данных (ШД).
Особенностью метода является необходимость объединения по ИЛИ(И) одноименных выходов микросхем. Это можно выполнить или подключением одноименных выходов к 2n- входовым схемам ИЛИ(И) для каждого разряда, или выполнять выходные структуры микросхем памяти по схеме допускающей монтажное ИЛИ(И) с открытым коллектором или с третьим состоянием, что целесообразней. По этой причине все микроросхемы памяти выпускаются с такими выходами.
|
|
|
PCI
Высокоскоростной интерфейс: 32-64 разрядный с мультеплексированной ША данных.
Назначение:
Универсальный интерфейс (соединение процессора с переферийными элементами и системой процессора памяти). Имеется встроенная поддержка кэширования (механизм слежения за шиной – интерференция данных).
Скорость: 33,66,133 МГц.
Пересылки: 32 и 64 бит, следовательно ширина ШД: 4-8 байт
Групповые пересылки разрешаются (Burst). Реализован скрытый арбитраж: арбитраж осуществляется в то время когда когда на шину идут пересылки (время не тратится). Низкая стоимость, определяется малым числом выводов (49 для ”мастер” и 47 для Slave). Простота использования: реализована функция авто конфигурирования системы. Высокая надёжность: при пересылки осуществляется контроль чёткости адреса данных.
 |

 AD0-AD7 AD72+AD63
AD0-AD7 AD72+AD63
 |  | |||||
 |  |

 CBE CBE (4-7)
CBE CBE (4-7)
PAR PAR 64
 |  |
FRANE LOCK
| | ||||
 |
TROY INT A
 |  | ||||
 |
IRDY INT B
| | ||||
 |
STOP INT C
| |
DEVSEL INT D
 |
IP SEL SDONE
PERR TDO
SERR TDI
 REQ TCK
REQ TCK
GNT TRAS
|
CLK TRST
|
 RST
RST
RST – сброс
AD – мультиплексированная шина команд и подтверждение байтов
SBE – подтверждение байтов
PAR – чётность контроль: контроллируются все выше указанные разряды
FRAME – уравляется мастером или задатчиком шин; указывает начало и конец пересылок
TRDY – устройство подчинено и готово к обмену
IRDY – мастер (инициатор) готов к обмену
STOP – требование к мастеру прекратить пересылки
hock – сигнал захвата шины
DEVSEL – подчинённое устр-во (slave) распознало свой адрес
IDSEL – сигнал выбора устр-ва при инициализации системы
PERR – ошибка чётности
SERR – системная ошибка
REQ – запрос мастера к арбитру на обладание шины
|
|
|
GNT – подтверждение арбитра мастеру, что шина ему предоставлена
INT A,B,C,D – запрос на преревание
Основные циклы
1.Чтение (система с изолированной шиной и каждое устр-во имеет свой дешефратор адреса)
а) позитивная дешефрация (устр-во опознаёт свой собственный диапазон адресов)
б) вычитательная дешифрация (на шине 1 устр-во, которое отвечает за все остальные не заполненные адреса).
PCI: Реализованный синхронный алгоритм обмена синхронного сигнала – даёт приемушество в быстродействии
 |  | | | | | ||||||





 CLK 1 2 3 4 5
CLK 1 2 3 4 5
 | | ||||
 | |||||
FRAME
CIBE




 WRITE bite enables bite enables BE2
WRITE bite enables bite enables BE2
ADO-
ADN 



 ADDRESS данные D2 D2
ADDRESS данные D2 D2
 IRDY Мастер не готов
IRDY Мастер не готов



 TRDY slave не готов
TRDY slave не готов
IRDY = 1 и FRAME = 1 - обмен завершён.
Такт 1: инициатор (мастер шины выставляет сигнал FRAME, который говорит,что шина захвачена и выставлен сигнал IRDy,следовательно устройство (мастер) готово к обмену.
Такт 2: к момену выставления фронта,мастер выставляет команду WRITE и адрес ADDRESS,по которому осуществляется обращение.
Такт 3: в промежутке между татктом 2 и татктом 3 3slave определяет, что обращение осуществлено к нему и выставлен знак DEVSEV и TRDY.
Такт 3: активное устр-во выставляет данные на ШД и выставляет сигнал Byte Enables, который подтверждает каждый из передоваемых байтов (читакт первую порцию данных адресованное устр-ву D1).
Такт 4: Slave не готов к обмену и выставляет сигнал TRDY и активное устр-во данные ен передаёт.
Такт 5: Мастер не готов и выставляет сигнал об этом и Slave не принимает данные. Т5 –Т6: оба устр-ва готовы к обмену и мастер выставляет порцию данных и Byte Enables Т7: цикл завершается: выыставляетоднавременно пару сигналов в IRDY =1 и FRAME=1 – цикл завешон.
Арбитраж: скрытый в PCI: освмещённый реальный арбитраж с работой др. устр-в. У каждого устр-ва сигналы REQ, GNT свои.
Активное устр-во выдаёт сигнал REQ на арбитр по своей линии. Арбитр определяет какое устр- во имеет наиболее высокий приоритет и по линии выдаёт сигнал GNT этому устр-ву.Активное устр-во выставляет сигнал FRAME,что устр-во захвачено и осуществляет обмен.
Особенности:
1) Групповая пересылка
|
|
|
2) Встроенная поддержка кэширования
Неудобства – существование мостов и необходимость реализовать сопрягающее устройство.
|
|
|
