 |


Характеристики физического лица. Структура данных
|
|
|
|
Кредиты физических лиц описываются 20 признаками, каждый их которых имеет градации (Таблица 1.)
Таблица 1. Описание кредита физического лица
| Номер признака | Наименование признака | Обозначение | Число градаций |
| 0 | Успешность кредита | Y | 2 |
| 1 | Сумма счета в банке | Z1 | 4 |
| 2 | Срок займа | Z2 | 10 |
| 3 | Кредитная история | Z3 | 5 |
| 4 | Назначение займа | Z4 | 11 |
| 5 | Сумма займа | Z5 | 10 |
| 6 | Счета по ценным бумагам | Z6 | 5 |
| 7 | Продолжительность работы | Z7 | 5 |
| 8 | Взнос в частичное погашение | Z8 | 4 |
| 9 | Семейное положение и пол | Z9 | 4 |
| 10 | Совместные обязательства или поручитель | Z10 | 3 |
| 11 | Время проживания в данной местности | Z11 | 4 |
| 12 | Вид гарантии | Z12 | 4 |
| 13 | Возраст | Z13 | 5 |
| 14 | Наличие других займов | Z14 | 3 |
| 15 | Наличие жилой площади | Z15 | 3 |
| 16 | Количество займов с банком | Z16 | 4 |
| 17 | Профессия | Z17 | 4 |
| 18 | Число родственников на иждивении | Z18 | 2 |
| 19 | Наличие телефона | Z19 | 2 |
| 20 | Иностранный или местный житель | Z20 | 2 |
Таблица данных имеет вид
Таблица2. Структура статистических данных

В работе используются реальные данные. Всего 1000 наблюдений. 700 заемщиков не вернули кредит «1», 300 – вернули «0».
Глава 2. Статистические и эконометрические методы оценки риска
В банках используются, главным образом, следующие методики:
· Скоринговые методики;
· Кластерный анализ;
· Дискриминантный анализ;
· Дерево классификаций;
· Нейронные сети;
· Технологии Data mining;
· Линейная вероятностная регрессионная модель;
· Logit-анализ;
Приступим к описанию этих методик.
Скоринговые методики
Скоринг кредитов физических лиц представляет собой методику оценки качества заемщика, основанную на различных характеристиках клиентов, таких как доход, возраст, семейное положение, профессия и др. В результате анализа переменных получают интегрированный показатель, который оценивает степень кредитоспособности заемщика по ранговой шкале: «хороший» или «плохой». Дается ответ на вопрос, вернет заемщик кредит или нет? Качество заемщика оценивается определенными баллами, отражающими степень его кредитоспособности. В зависимости от балльной оценки принимается решение о выдаче кредита и его лимитах [4].
|
|
|
Привлечение банками для оценки кредитоспособности квалифицированных специалистов имеет несколько недостатков: во-первых, их мнение все же субъективно; во-вторых, люди не могут оперативно обрабатывать большие объемы информации; в-третьих, оплата хороших специалистов требует значительных расходов. Поэтому банки все больше интересуются такими системами оценки риска, которые позволили бы минимизировать участие экспертов и влияние человеческого фактора на принятие решений.
Для оценки кредитного риска производится анализ кредитоспособности заемщика, под которой понимается его способность полностью и в срок рассчитаться по своим долговым обязательствам. В соответствии с таким определением основная задача скоринга заключается не только в том, чтобы выяснить, в состоянии клиент выплатить кредит или нет, но и в степени надежности и обязательности клиента.
Скоринг представляет собой математическую или статистическую модель, с помощью которой на основе кредитной истории «прошлых» клиентов банк пытается определить, насколько велика вероятность, что потенциальный заемщик вернет кредит в срок. Скоринг является методом классификации всей интересующей нас популяции на различные группы, когда нам неизвестна характеристика, которая разделяет эти группы, но зато известны другие характеристики.
|
|
|
В западной банковской системе, когда человек обращается за кредитом, банк располагает следующей информацией для анализа: анкетой, которую заполняет заемщик; информацией на данного заемщика из кредитного бюро, в котором хранится кредитная история взрослого населения страны; данными движения по счетам, если речь идет о клиенте банка.
Кредитные аналитики оперируют следующими понятиями: «характеристики-признаки» клиентов и «градации-значения», которые принимает признак. В анкете клиента характеристиками-признаками являются вопросы анкеты (возраст, семейное положение, профессия), а градациями-значениями— ответы на эти вопросы. В упрощенном виде скоринговая модель дает взвешенную сумму определенных характеристик. В результате получают интегральный показатель (score); чем он выше, тем выше надежность клиента (табл.3.). Интегральный показатель каждого клиента сравнивается с неким заданным уровнем показателя. Если показатель выше этого уровня, то выдается кредит, если ниже этой линии, — нет.
Сложность в том, какие характеристики-признаки следует включать в модель и какие весовые коэффициенты должны им соответствовать. Философия скоринга заключается не в поиске объяснений, почему этот человек не платит. Скоринг использует характеристики, которые наиболее тесно связаны с ненадежностью клиента. Неизвестно, вернет ли данный заемщик кредит, но известно, что в прошлом люди этого возраста, этой профессии, с таким уровнем образования и числом иждивенцев кредит не возвращали (или возвращали).
Таблица 3. Скоринговая карта
| Показатель | Значение | Баллы |
| Возраст | 20 - 25 | 100 |
| 26 - 30 | 107 | |
| 31 - 40 | 123 | |
| ………… | ………….. | |
| Доход | 1000 - 3000 | 130 |
| 3001 - 5000 | 145 | |
| 5001 - 6000 | 160 | |
| ………… | ………….. |
Среди преимуществ скоринговых систем западные банкиры указывают в первую очередь снижение уровня невозврата кредита. Далее отмечаются быстрота и беспристрастность в принятии решений, возможность эффективного управления кредитным портфелем, определение оптимального соотношения между доходностью кредитных операций и уровнем риска.
Кластерный анализ
Методы кластерного анализа позволяют разбить изучаемую совокупность объектов на группы однородных в некотором смысле объектов, называемых кластерами или классами. Иерархические и параллельные кластер-процедуры практически реализуемы лишь в задачах классификации не более нескольких десятков наблюдений. К решению задач с большим числом наблюдений (как в наших целях) применяют последовательные кластер-процедуры - это итерационные алгоритмы, на каждом шаге которых используется одно наблюдение (или небольшая часть исходных наблюдений) и результаты разбиения на предыдущем шаге. Идею этих процедур реализована в «SPSS» методе  средних («K-Means Clustering») с заранее заданным числом
средних («K-Means Clustering») с заранее заданным числом 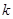 классов.
классов.
|
|
|
Алгоритм заключается в следующем: выбирается заданное число k- точек и на первом шаге эти точки рассматриваются как "центры" кластеров. Каждому кластеру соответствует один центр. Объекты распределяются по кластерам по такому принципу: каждый объект относится к кластеру с ближайшим к этому объекту центром. Таким образом, все объекты распределились по k кластерам. Затем заново вычисляются центры этих кластеров, которыми после этого момента считаются покоординатные средние кластеров. После этого опять перераспределяются объекты. Вычисление центров и перераспределение объектов происходит до тех пор, пока не стабилизируются центры.
Если данные понимать как точки в признаковом пространстве, то задача кластерного анализа формулируется как выделение "сгущений точек", разбиение совокупности на однородные подмножества объектов.
При проведении кластерного анализа обычно определяют расстояние на множестве объектов; алгоритмы кластерного анализа формулируют в терминах этих расстояний. Мер близости и расстояний между объектами существует великое множество. Их выбирают в зависимости от цели исследования. В частности, евклидово расстояние лучше использовать для количественных переменных, расстояние хи-квадрат - для исследования частотных таблиц, имеется множество мер для бинарных переменных.
Меры близости отличаются от расстояний тем, что они тем больше, чем более похожи объекты.
|
|
|

Пусть имеются два объекта X=(X1,…,Xm) и Y=(Y1,…,Ym). (табл.4.) Используя эту запись для объектов, определить основные виды расстояний, используемых процедуре CLUSTER:
· Евклидово расстояние  (Euclidian distance).
(Euclidian distance).
· Квадрат евклидова расстояния 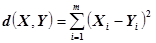 (Squared Euclidian distance)
(Squared Euclidian distance)
· Эвклидово расстояние и его квадрат целесообразно использовать для анализа количественных данных.
· Мера близости - коэффициент корреляции 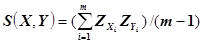 , где
, где 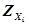 и
и  компоненты стандартизованных векторов X и Y. Эту меру целесообразно использовать для выявления кластеров переменных, а не объектов. Расстояние хи-квадрат получается на основе таблицы сопряженности, составленной из объектов X и Y (таблица 4.), которые, предположительно, являются векторами частот. Здесь рассматриваются ожидаемые значения элементов, равные E(Xi)=X.*(Xi+Yi)/(X.+Y.) и E(Yi)=Y.*(Xi+Yi)/(X.+Y.), а расстояние хи-квадрят имеет вид корня из соответствующего показателя
компоненты стандартизованных векторов X и Y. Эту меру целесообразно использовать для выявления кластеров переменных, а не объектов. Расстояние хи-квадрат получается на основе таблицы сопряженности, составленной из объектов X и Y (таблица 4.), которые, предположительно, являются векторами частот. Здесь рассматриваются ожидаемые значения элементов, равные E(Xi)=X.*(Xi+Yi)/(X.+Y.) и E(Yi)=Y.*(Xi+Yi)/(X.+Y.), а расстояние хи-квадрят имеет вид корня из соответствующего показателя
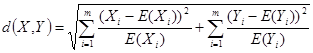 .
.
· Расстояние Фи-квадрат является расстоянием хи-квадрат, нормированным "число объектов" в таблице сопряженности, представляемой строками X и Y, т.е. на корень квадратный из N=X.+Y..
Кластерный анализ является описательной процедурой, он не позволяет сделать никаких статистических выводов, но дает возможность провести своеобразную разведку - изучить "структуру совокупности".
Проведем кластеризацию по всем 20 признакам и всем наблюдениям. В результате работы программы выводится таблица 5. (показана лишь ее часть)
Таблица 5. Cluster Membership
| Case Number | Y | Cluster | Distance |
| ………… | … | …… | ………… |
| 822 | 0 | 0 | 2985,732 |
| 823 | 1 | 0 | 2996,715 |
| 824 | 0 | 0 | 3040,706 |
| 825 | 1 | 0 | 3054,689 |
| 826 | 0 | 0 | 3099,727 |
| 827 | 1 | 0 | 3108,674 |
| 828 | 1 | 1 | 3100,310 |
| 829 | 1 | 1 | 3053,258 |
| 830 | 1 | 1 | 3043,285 |
| 831 | 1 | 1 | 2991,286 |
| ………… | …… | ……… | ………… |
Столбец Y показывает, относится ли наблюдение к группе вернувших кредит “0” или навернувших “1”, столбец «Cluster» показывает принадлежность к той или иной группе наблюдения на основе кластеризации.
Таблица 6 указывает число наблюдений в том или ином кластере.
Таблица 6. Number of Cases in each Cluster
| Cluster | 1 | 822,000 | ||
|
| 0 | 178,000 | ||
| Valid | 1000,000 | |||
| Missing | ,000 | |||
Проанализируем качество классификации.
Таблица 7. Expectation-Predictable Table
|
| Y=0 | Y=1 | всего |
| всего по выборке | 300 | 700 | 1000 |
| прогноз | 178 | 822 | 1000 |
| правильно | 65 | 587 | 652 |
| неправильно | 235 | 113 | 348 |
| % правильно | 21,7% | 83,9% | 65,2% |
| % неправильно | 78,3% | 16,1% | 34,8% |
Из таблицы можно видеть, что видеть, что метод позволяет хорошо предугадывать плохие заемы на уровне 83,9%, но плохо предугадывает хорошие заемы – 21,7%. Обычно к методикам выдвигается требование распознавать лучше плохие заемы, т.к. потеря невозврата кредита больше потери неполучения процентов по кредиту.
|
|
|
Дискриминантный анализ
Кластерный анализ решает задачу классификации объектов при практически отсутствующей априорной информации о наблюдениях внутри классов; в дискриминантном анализе предполагается наличие такой информации. С помощью дискриминантного анализа на основании некоторых признаков (независимых переменных) индивидуум может быть причислен к одной из двух (или к одной из нескольких) заданных заранее групп. Ядром дискриминантного анализа является построение так называемой дискриминантной функция [2]
D=b1*x1+b2*x2+…+bn*xn+a
где х1 и х2 — значения переменных, соответствующих рассматриваемым случаям, константы x1 - xn и а — коэффициенты, которые и предстоит оценить с помощью дискриминантного анализа. Целью является определение таких коэффициентов, чтобы по значению дискриминантной функции можно было с максимальной четкостью провести разделение по группам.
Дискриминантный анализ является разделом многомерного статистического анализа, который позволяет изучать различия между двумя и более группами объектов по нескольким переменным одновременно. Цели ДА – интерпретация межгрупповых различий - дискриминация и методы классификации наблюдений по группам.
При интерпретации мы отвечаем на вопросы: возможно ли, используя данный набор переменных, отличить одну группу от другой, насколько хорошо эти переменные помогают провести дискриминацию, и какие из них наиболее информативны.
Методы классификации связаны с получением одной или нескольких функций, обеспечивающих возможность отнесения данного объекта к одной из групп. Эти функции называются классифицирующими.
Реализуем метод дискриминантного анализа в SPSS. Существует 2 алгоритма классификации:
1. Одновременный учет всех независимых переменных. Результаты представлены в таблице 8
Таблица 8. Classification Results(a)
| Y | Predicted Group Membership | Total | ||||
|
| 0 | 1 | ||||
| Original | Count | 0 | 218 | 82 | 300 | |
|
| 1 | 188 | 512 | 700 | ||
|
| % | 0 | 72,7 | 27,3 | 100,0 | |
|
| 1 | 26,9 | 73,1 | 100,0 | ||
a 73,0% of original grouped cases correctly classified.
В таблице 9 приведены коэффициенты дискриминантной функции
Таблица 9. Canonical Discriminant Function Coefficients
|
| Function | |
| 1 | ||
| Z1 | ,503 | |
| Z2 | -,127 | |
| Z3 | ,338 | |
| Z4 | ,024 | |
| Z5 | -,150 | |
| Z6 | ,174 | |
| Z7 | ,134 | |
| Z8 | -,242 | |
| Z9 | ,225 | |
| Z10 | ,314 | |
| Z11 | -,006 | |
| Z12 | -,172 | |
| Z13 | ,035 | |
| Z14 | ,242 | |
| Z15 | ,272 | |
| Z16 | -,210 | |
| Z17 | ,023 | |
| Z18 | -,135 | |
| Z19 | ,271 | |
| Z20 | ,611 | |
| (Constant) | -3,977 | |
Лямбда Уилкса показывает на значимое различие групп (p < 0,001).
Таблица 10. Wilks' Lambda
| Test of Function(s) | Wilks' Lambda | Chi-square | df | Sig. |
| 1 | ,760 | 271,399 | 20 | ,000 |
2. Пошаговый метод. При выполнении дискриминантного анализа можно применить пошаговый образ действий, который рекомендуется при наличии большого количества независимых переменных.
Таблица 11. Classification Results(a)
|
|
| Y | Predicted Group Membership | Total | |
| 0 | 1 | ||||
| Original | Count | 0 | 219 | 81 | 300 |
| 1 | 203 | 497 | 700 | ||
| % | 0 | 73,0 | 27,0 | 100,0 | |
| 1 | 29,0 | 71,0 | 100,0 | ||
a 71,6% of original grouped cases correctly classified.
Лямбда Уилкса показывает на значимое различие групп (p < 0,001).
Таблица 12. Wilks' Lambda
| Test of Function(s) | Wilks' Lambda | Chi-square | df | Sig. |
| 1 | ,774 | 254,126 | 10 | ,000 |
В таблице 13 приведены коэффициенты дискриминантной функции
Таблица 13. Canonical Discriminant Function Coefficients
|
| Function | |
| 1 | ||
| SCHET | ,528 | |
| SROK | -,140 | |
| HISTOR | ,315 | |
| ZAIM | -,145 | |
| CHARES | ,186 | |
| TIMRAB | ,133 | |
| VZNOS | -,240 | |
| FAMIL | ,248 | |
| PORUCHIT | ,372 | |
| INIZAIMI | ,262 | |
| (Constant) | -3,288 | |
Точность распознавания дискриминантным анализом выше, чем кластерным. Но результаты по-прежнему остаются неудовлетворительными.
Дерево классификаций
Дерево классификаций является более общим алгоритмом сегментации обучающей выборки прецедентов. В методе дерева классификаций сегментация прецедентов задается не с помощью n-мерной сетки, а путем последовательного дробления факторного пространства на вложенные прямоугольные области (рис.1).
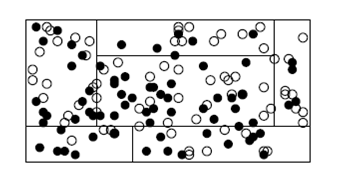
Рис.1. Дерево классификации
На первом шаге разделение выборки прецедентов на сегменты производится по самому значимому фактору. На втором и последующих шагах в отношении каждого из полученных ранее сегментов процедура повторяется до тех пор, пока никакой вариант последующего дробления не приводит к существенному различию между соотношением положительных и отрицательных прецедентов в новых сегментах. Количество ветвлений (сегментов) выбирается автоматически.
В рассмотренной методике также не дается ответ, насколько кредит хорош или плох. Метод не позволяют получить точную количественную оценку риска и установить допустимый риск.
Нейронные сети
Нейронные сети NN используются при определении кредитоспособности юридических лиц, где анализируются выборки меньшего размера, чем в потребительском кредите. Наиболее успешной областью их применения стало выявление мошенничества с кредитными карточками. Нейронные сети выявляют нелинейные связи между переменными, которые могут привести к ошибке в линейных моделях. NN позволяют обрабатывать прецеденты обучающей выборки с более сложным (чем прямоугольники) видом сегментов (рис. 2). Форма сегментов зависит от внутренней структуры NN Формулы и коэффициенты модели риска на основе NN лишены физического и логического смысла.
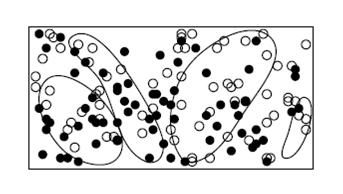
Рис.2. Сегменты разделения «хороших» и «плохих» объектов в NN
Нейросеть — это «черный ящик», внутреннее содержание которого (так называемые веса нейронов) не имеет смысла в терминах оценки риска. Такие методики не позволяют объяснить, почему данному заемщику следует отказать в кредите. NN-модели классификации обладают низкой стабильностью (робастностью).
Технологии Data mining
В основе технологии data mining лежат алгоритмы поиска закономерностей между различными факторами в больших объемах данных. При этом анализируются зависимости между всеми факторами; но, поскольку даже при небольшом числе факторов количество их всевозможных комбинаций растет экспоненциально, в data mining применяются алгоритмы априорного отсечения слабых зависимостей [1]. Говоря терминами анализа кредитоспособности, data mining на основе данных о выданных кредитах выявляет те факторы, которые существенно влияют на кредитоспособность заемщика, и вычисляет силу этого влияния. Соответственно, чем сильнее определенный фактор влияет на кредитоспособность, тем больший балл ему присваивается в методике скоринга. Чем больше данные держателя кредитной карты похожи на данные «кредитоспособного гражданина», тем больший лимит по кредиту он может получить, тем лучшие условия ему могут быть предоставлены
Главное преимущество методик на основе data mining заключается в том, что они могут работать на малых выборках. При больших выборках их точность, робастность и прозрачность недостаточны В них также не дается ответ, насколько кредит хорош или плох Метод не позволяет получить количественную оценку риска, установить допустимый риск, назначить цену за риск и выявить вклады факторов и их градаций в риск
|
|
|
