 |


Ошибка, состоящая в том, что мы приняли нулевую гипотезу, в то время как она неверна, называется ошибкой II рода.
|
|
|
|
Вероятность такой ошибки обозначается как β. Мощность критерия - это его способность не допустить ошибку II рода, поэтому:
Мощность=1—β
Мощность критерия определяется эмпирическим путем. Одни и те же задачи могут быть решены с помощью разных критериев, при этом обнаруживается, что некоторые критерии позволяют выявить различия там, где другие оказываются неспособными это сделать, или выявляют более высокий уровень значимости различий. Возникает вопрос: а зачем же тогда использовать менее мощные критерии? Дело в том, что основанием для выбора критерия может быть не только мощность, но и другие его характеристики, а именно:
а) простота;
б) более широкий диапазон использования (например, по отношению к данным, определенным по номинативной шкале, или по отношению к большим n);
в) применимость по отношению к неравным по объему выборкам;
г) большая информативность результатов.
Классификация задач и методов их решения
Множество задач психологического исследования предполагает те или иные сопоставления. Мы сопоставляем группы испытуемых по какому-либо признаку, чтобы выявить различия между ними по этому признаку. Мы сопоставляем то, что было "до" с тем, что стало "после" наших экспериментальных или любых иных воздействий, чтобы определить эффективность этих воздействий. Мы сопоставляем эмпирическое распределение значений признака с каким-либо теоретическим законом распределения или два эмпирических распределения между собой, с тем, чтобы доказать неслучайность выбора альтернатив или различия в форме распределений.
Мы, далее, можем сопоставлять два признака, измеренные на одной и той же выборке испытуемых, для того, чтобы установить степень согласованности их изменений, их сопряженность, корреляцию между ними.
|
|
|
Наконец, мы можем сопоставлять индивидуальные значения, полученные при разных комбинациях каких-либо существенных условий, с тем чтобы выявить характер взаимодействия этих условий в их влиянии на индивидуальные значения признака.
Именно эти задачи позволяет решить тот набор методов, который предлагается настоящим руководством. Все эти методы могут быть использованы при так называемой "ручной" обработке данных.
Краткая классификация задач и методов дана в Таблице 1.2.
Таблица 1.2
| Классификация задач | и методов их решения | |
| Задачи | Условия | Методы |
| 1.Выявление различий в уровне исследуемого признака | а) 2 выборки испытуемых | Q- критерий Розенбаума; U - критерий Манна-Уитни; φ* - критерий (угловое преобразование Фишера) |
| б) 3 и более выборок испытуемых | S - критерий тенденций Джонкира; Н - критерий Крускала-Уоллиса. | |
| 2. Оценка сдвига значений исследуемого признака | а) 2 замера на одной и той же выборке испытуемых | Т - критерий Вилкоксона; G - критерий знаков; φ* - критерий (угловое преобразование Фишера). |
| б) 3 и более замеров на одной и той же выборке испытуемых | χл2 - критерий Фридмана; L - критерий тенденций Пейджа. | |
| 3. Выявление различий в распределении | а) при сопоставлении эмпирического признака распределения с теоретическим | χ2 - критерий Пирсона; λ - критерий Колмогорова-Смирнова; m - биномиальный критерий. |
| б) при сопоставлении двух эмпирических распределений | χ2 - критерий Пирсона; λ - критерий Колмогорова-Смирнова; φ* - критерий (угловое преобразование Фишера). | |
| 4.Выявление степени согласованности изменений | а) двух признаков | rs - коэффициент ранговой корреляции Спирмена. |
| б) двух иерархий или профилей | rs - коэффициент ранговой корреляции Спирмена. | |
| 5. Анализ изменений признака под влиянием контролируемых условий | а) под влиянием одного фактора | S- критерий тенденций Джонкира; L - критерий тенденций Пейджа; однофакторный дисперсионный анализ Фишера. |
| б) под влиянием двух факторов одновременно | Двухфакторный дисперсионный анализ Фишера. |
1.9. Принятие решения о выборе метода математической обработки
|
|
|
Если данные уже получены, то вам предлагается следующий алгоритм определения задачи и метода.
АЛГОРИТМ 1
Принятие решения о задаче и методе обработки на стадии, когда данные уже получены
1. По первому столбцу Табл. 1.2 определить, какая из задач стоит в вашем исследовании.
2. По второму столбцу Табл. 1.2 определить, каковы условия решения вашей задачи, например, сколько выборок обследовано или на какое количество групп вы можете разделить обследованную выборку.
3. Обратиться к соответствующей главе и по алгоритму принятия решения о выборе критерия, приведенного в конце каждой главы, определить, какой именно метод или критерий вам целесообразно использовать.
Если вы еще находитесь на стадии планирования исследования, то лучшее заранее подобрать математическую модель, которую вы будете в дальнейшем использовать. Особенно необходимо планирование в тех случаях, когда в перспективе предполагается использование критериев тенденций или (в еще большей степени) дисперсионного анализа., В этом случае алгоритм принятия решения таков:
АЛГОРИТМ 2
Принятие решения о задаче и методе обработки на стадии планирования исследования
1. Определите, какая модель вам кажется наиболее подходящей для доказательства] ваших научных предположений.
2. Внимательно ознакомьтесь с описанием метода, примерами и задачами для самостоятельного решения, которые к нему прилагаются.
3. Если вы убедились, что это то, что вам нужно, вернитесь к разделу "Ограничения критерия" и решите, сможете ли вы собрать данные, которые будут отвечать этим ограничениям (большие объемы выборок, наличие нескольких выборок, монотонно различающихся по какому-либо признаку, например, по возрасту и т.п.).
4. Проводите исследование, а затем обрабатывайте полученные данные по заранее! выбранному алгоритму, если вам удалось выполнить ограничения.
|
|
|
5. Если ограничения выполнить не удалось, обратитесь к алгоритму 1.
В описании каждого критерия сохраняется следующая последовательность изложения:
· назначение критерия;
· описание критерия;
· гипотезы, которые он позволяет проверить;
· графическое представление критерия;
· ограничения критерия;
· пример или примеры.
Кроме того, для каждого критерия создан алгоритм расчетов. Если критерий сразу удобнее рассчитывать по алгоритму, то он приводится в разделе "Пример"; если алгоритм легче можно воспринять уже после рассмотрения примера, то он приводится в конце параграфа, соответствующего данному критерию.
Список обозначений
Латинские обозначения:
А - показатель асимметрии распределения
с - количество групп или условий измерения
d - разность между рангами, частотами или частостями
df - число степеней свободы в дисперсионном анализе
Е - показатель эксцесса
F - критерий Фишера для сравнения дисперсий
f - частота
f * - частость, или относительная частота
G - критерий знаков
Н - критерий Крускала-Уоллиса
i - индекс, обозначающий порядковый номер наблюдения
j - индекс, обозначающий порядковый номер разряда, класса, группы
k - количество классов или разрядов признака
L - критерий тенденций Пейджа
М - среднее значение признака или средняя арифметическая; то же, что и х
m - биномиальный критерий
n - количество наблюдений (испытуемых, реакций, выборов и т.п.)
N - общее количество наблюдений в двух или более выборках
Р - вероятность того, что событие произойдет
р - вероятность ошибки 1 рода (то же, что и а), уровень статистической значимости
Q - 1) вероятность того, что событие не произойдет; 2) критерий Розенбаума
rs - коэффициент ранговой корреляции Спирмена
S - критерий Джонкира
S2 - оценка дисперсии
Si - количество значений, которые выше или ниже данного значения
SS - суммы квадратов (в дисперсионном анализе)
Т - критерий Вилкоксона
Тс - суммы рангов по столбцам
Тк - большая сумма рангов в критерии U
|
|
|
U - критерий Манна-Уитни
Wn - размах вариативности, или диапазон значений от наименьшего до
наибольшего
хi - текущее наблюдение; каждое наблюдение по порядку
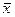 - среднее значение признака (то же, что и М)
- среднее значение признака (то же, что и М)
Греческие обозначения:
α(альфа) - вероятность ошибки I рода (отклонения H0, которая верна)
β (бета) - вероятность ошибки II рода (принятия H0, которая неверна)
λ, (ламбда) - критерий Колмогорова-Смирнова
v (ню) - число степеней свободы в непараметрических критериях
σ (сигма) - стандартное отклонение
φ (фи) - центральный угол, определяемый по процентной доле в критерии φ*
φ* (фи) - критерий Фишера с угловым преобразованием
χ2 (хи-квадрат) - критерий Пирсона
χ2 r (хи-ар-квадрат) - критерий Фридмана.
ГЛАВА 2
|
|
|
