 |


Простая линейная регрессия
|
|
|
|
Лабораторная работа №6
Анализ двумерных данных включает в себя три основных цели:
1. Описание и понимание взаимосвязи.
2. Прогнозирование и предсказание нового наблюдения.
3. Корректировка и управление процессом.
Существует два вида анализа двумерных данных, представленных переменными X и Y: корреляционный анализ, позволяющий оценить степень взаимосвязи между переменными X и Y, и регрессионный анализ, определяющий форму связи между этими переменными. Таким образом, регрессионный анализ всегда проводится после корреляционного анализа, когда между переменными установлена взаимосвязь. Регрессионный анализ используется для прогнозирования одной переменной на основании другой (как правило, Y на основании X), или показывает, как можно управлять одной переменной с помощью другой.
Определение формы зависимости между переменными X и Y является одной из главных задач регрессионного анализа. Для этого необходимо построить уравнение регрессионной связи между Y и X (уравнение регрессии) следующего вида:
Y = f (x) + e,
в котором f (x) называется функцией регрессии, а e – величина, учитывающая случайные воздействия. Для выборочных данных уравнение регрессионной связи удобно представить следующим образом:
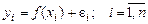
При наличии случайной составляющей e i значения yi имеют определенный разброс. Поэтому нет смысла подбирать функцию регрессии, проходящую через все точки. Основное правило подбора вида функции регрессии заключается в том, чтобы все точки диаграммы рассеяния были сконцентрированы около графика этой функции.
На практике, поскольку мы располагаем выборочными данными, невозможно точно построить функцию регрессии, можно только получить ее оценку, которую обозначим как 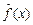 . Уравнение, включающее оценку для функции регрессии, называется выборочным уравнением регрессии и имеет вид:
. Уравнение, включающее оценку для функции регрессии, называется выборочным уравнением регрессии и имеет вид: 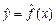 . Построив «выборочную» функцию регрессии далее необходимо проверить достоверность функции и ее параметров, а также провести оценку неизвестных значений (прогноз) зависимой переменной Y.
. Построив «выборочную» функцию регрессии далее необходимо проверить достоверность функции и ее параметров, а также провести оценку неизвестных значений (прогноз) зависимой переменной Y.
|
|
|
Простейшей, с точки зрения анализа, является линейная взаимосвязь между X и Y, которая выражается в том, что точки на диаграмме рассеяния случайным образом группируются вдоль прямой линии, имеющей наклон (вверх или вниз). По выборке можно построить выборочную линейную функцию регрессии вида 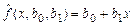 , которая является оценкой линейной функции регрессии f (x, b0, b1). Таким образом, выборочное уравнение линейной регрессии имеет вид:
, которая является оценкой линейной функции регрессии f (x, b0, b1). Таким образом, выборочное уравнение линейной регрессии имеет вид:
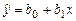 .
.
Коэффициенты b 0, b 1 являются оценками параметров b0, b1. Для вычисления коэффициентов b 0, b 1 используется метод наименьших квадратов (МНК), который характеризуется наименьшей суммой квадратов отклонений значений переменной Y от прямой. Это означает, что прямая на диаграмме рассеяния будет проходить «достаточно близко» к точкам (xi, yi). Коэффициент b 1 определяет наклон прямой (его часто называют коэффициентом регрессии). При увеличении значения переменной X ровно на единицу значение переменной Y в среднем увеличивается (если b 1>0) или уменьшается (если b 1<0) на b 1 единиц. Коэффициент b 0 (постоянный член, или константа регрессии) определяет сдвиг прямой, т.е. такое значение Y, когда значение X равно нулю. При использовании МНК сдвиг определяется таким образом, чтобы прямая проходила через точку ( ), где
), где 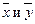 – средние значения переменных X и Y соответственно. В тех случаях, когда нулевое значение X лишено смысла, сдвиг рассматривается как необходимая характеристика для построения функции регрессии и его не следует интерпретировать.
– средние значения переменных X и Y соответственно. В тех случаях, когда нулевое значение X лишено смысла, сдвиг рассматривается как необходимая характеристика для построения функции регрессии и его не следует интерпретировать.
В Excel используются три метода построения функции линейной регрессии: команда Добавить линию тренда, инструмент анализа Регрессия и соответствующие статистические функции.
|
|
|
|
|
|
