 |


Нормально распределенного диагностического параметра X
|
|
|
|
Операции по анализу распределения тестовых баллов, построению тестовых норм и проверке их репрезентативности. Завершая этот раздел, кратко перечислим действия, которые последовательно должен произвести психолог при построении тестовых норм.
1. Сформировать выборку стандартизации (случайную или стратифицированную по какому-либо параметру) из той популяции, на которой предполагается применять тест. Провести на каждом испытуемом из выборки тест в сжатые сроки (чтобы устранить иррелевантный разброс, вызванный внешними событиями, происшедшими за время обследования).
2. Произвести группировку сырых баллов с учетом выбранного интервала квантования (интервала равнозначности). Интервал определяется величиной W/m, где W=x max — х max; m - количество интервалов равнозначности (градаций шкалы).
3. Построить распределение частот тестовых баллов (для заданных интервалов равнозначности) в виде таблицы и в виде соответствующих графиков гистограммы и кумуляты.
4. Произвести расчет среднего арифметического значения и стандартного отклонения, а также асимметрии и эксцесса с помощью компьютера. Проверить гипотезы о значимости асимметрии и эксцесса. Сравнить результаты проверки с визуальным анализом кривых распределения.
5. Произвести проверку нормальности одного из распределений с помощью критерия Колмогорова (при n < 200 с помощью более мощных критериев) или произвести процентильную нормализацию с переводом в стандартную шкалу, а также линейную стандартизацию и сравнить их результаты (с точностью до целых значений стандартных баллов).
6. Если совпадения не будет - нормальность отвергается; в этом случае произвести проверку устойчивости распределения расщеплением выборки на две случайные половины. При совпадении нормализованных баллов для половины и для целой выборки можно считать нормализованную шкалу устойчивой.
|
|
|
7. Проверить однородность распределения по отношению к варьированию заданного популяционного признака (пол, профессия и т. п.) с помощью критерия Колмогорова. Построить в совмещенных координатах графики гистограммы и кумуляты для полной и частной выборок. При значимых различиях разбить выборку на разнородные подвыборки.
8. Построить таблицы процентильных и нормализованных тестовых норм (для каждого интервала равнозначности сырого балла). При наличии разнородных подвыборок для каждой из них должна быть своя таблица.
9. Определить критические точки (верхнюю и нижнюю) для доверительных интервалов (на уровне Р < 0,01) с учетом стандартной ошибки в определении среднего значения.
10. Обсудить конфигурацию полученных распределений с учетом предполагаемого механизма выполнения того или иного теста.
11. В случае негативного результата: отсутствия устойчивых норм для шкалы с заданным числом градаций (с заданной точностью прогноза критериальной деятельности) - осуществить обследование более широкой выборки или отказаться от использования, данного теста.
НАДЕЖНОСТЬ ТЕСТА
В дифференциальной психометрике проблемы валидности и надежности тесно взаимосвязаны, тем не менее мы последуем традиции раздельного изложения методов проверки этих важнейших психометрических свойств теста.
Надежность и точность. Как уже отмечалось в разделе 3.1, общий разброс (дисперсию) результатов произведенных измерений можно представить как результат действия двух источников разнообразия: самого измеряемого свойства и нестабильности измерительной процедуры, обусловливающей наличие ошибки измерения. Это представление выражено в формуле, описывающей надежность теста и виде отношения истинной дисперсии к дисперсии эмпирически зарегистрированных баллов:
|
|
|
 (3.2.1)
(3.2.1)
Так как истинная дисперсия и дисперсия ошибки связаны очевидным соотношением, формула (3.2.1) легко преобразуется в формулу Рюлона:
 (3.2.2)
(3.2.2)
где а - надежность теста;  . -дисперсия ошибки.
. -дисперсия ошибки.
Величина ошибки измерения - обратный индикатор точности измерения. Чем больше ошибка, тем шире диапазон неопределенности на шкале (доверительный интервал индивидуального балла), внутри которого оказывается статистически возможной локализация истинного балла данного испытуемого. Таким образом, для проверки гипотезы о значимости отличия балла испытуемого от среднего значения оказывается недостаточным только оценить ошибку среднего, нужно еще оценить ошибку измерения, обусловливающую разброс в положении индивидуального балла (рис. 7).
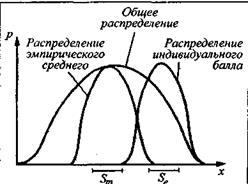
Рис. 7. Соотношение распределений Sm – стандартное отклонение эмпирического среднего, St – стандартное отклонение ошибки
Как же определить ошибку измерения? На помощь приходят корреляционные методы, позволяющие определить точность (надежность) через устойчивость и согласованность результатов, получаемых как на уровне целого теста, так и на уровне отдельных его пунктов.
Надежность целого теста имеет две разновидности.
1. Надежность-устойчивость (ретестовая надежность). Измеряется с помощью повторного проведения теста на той же выборке испытуемых, обычно через две недели после первого тестирования. Для интервальных шкал подсчитывается хорошо известный коэффициент корреляции произведения моментов Пирсона:

где х1i. - тестовый балл i -го испытуемого при первом измерении;
х2i. - тестовый балл того же испытуемого при повторном измерении;
n - количество испытуемых.
Оценка значимости этого коэффициента основывается на несколько иной логике, чем это обычно делается при проверке нулевой гипотезы - о равенстве корреляций нулю. Высокая надежность достигается тогда, когда дисперсия ошибки оказывается пренебрежительно малой. 'Относительную долю дисперсии ошибки легко определить по формуле
 (3.2.4)
(3.2.4)
Таким образом, для нас существеннее близость к единице, а не отдаленность от нуля. Обычно в тестологической практике редко удается достичь коэффициентов, превышающих 0,8. При г = 0,75 относительная доля стандартной ошибки равна 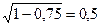 . Этой ошибкой, очевидно, нельзя пренебречь. При такой ошибке эмпирически полученное отклонение индивидуального тестового балла от среднего по выборке оказывается, как правило, завышенным. Для того чтобы выяснить «истинное» значение тестового балла индивида, применяется формула
. Этой ошибкой, очевидно, нельзя пренебречь. При такой ошибке эмпирически полученное отклонение индивидуального тестового балла от среднего по выборке оказывается, как правило, завышенным. Для того чтобы выяснить «истинное» значение тестового балла индивида, применяется формула
|
|
|
 (3.2.5)
(3.2.5)
где  - истинный балл; '
- истинный балл; '
хi — эмпирический балл i -го испытуемого;
r - эмпирически измеренная надежность теста;
 - среднее для теста.
- среднее для теста.
Предположим, испытуемый получил балл IQ по шкале Стэнфорда.-Бине, равный 120 нормализованным очкам, М = 100, г = 0,9. Тогда истинный балл 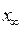 = 0,9
= 0,9  120 + 0,1 100 =118.
120 + 0,1 100 =118.
Конечно, требование ретестовой надежности является корректным лишь по отношению к таким психическим характеристикам индивидов, которые сами являются устойчивыми во времени. Если мы создаем тест для измерения эмоциональных состояний (бодрости, тревоги и т. д.), то, очевидно, требовать от него ретестовой надежности бессмысленно: у испытуемых быстрее изменится состояние, чем они забудут свои ответы по первому тестированию.
Для шкал порядка в качестве меры устойчивости к перетестированию используется коэффициент ранговой корреляции Спирмена:
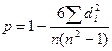 , (3.2.6)
, (3.2.6)
где di — разность рангов /-го испытуемого в первом и втором ранговом ряду.
С помощью компьютера определяется более надежный коэффициент ранговой корреляции Кендалла (1975).
2. Надежность- согласованность (одномоментная надежность).
Эта разновидность надежности не зависит от устойчивости, имеет особую содержательную и операциональную природу. Простейшим способ ее измерения состоите коррелировании параллельных форм теста (Анастази Д., 1982, кн. 1,с. 106). Чаще всего параллельные формы теста получают расщеплением составного теста на «четную» и «нечетную» половины: к первой относятся четные пункты, ко второй - нечетные. По каждой половине рассчитываются суммарные баллы и между двумя рядами баллов по испытуемым определяются допустимые (с учетом уровня измерения) коэффициенты корреляции. Если параллельные тесты не нормализованы, то предпочтительнее использовать ранговую корреляцию. При таком расщеплении получается коэффициент, относящийся к половинам теста. Для того чтобы найти надежность целого теста пользуются формулой Спирмена - Брауна:
|
|
|
 (3.2.7)
(3.2.7)
где rx - эмпирически рассчитанная корреляция для половин.
Делить тест на две половины можно разными способами, и каждый раз получаются несколько разные коэффициенты (Аванесов В. С., 1982, с. 122), поэтому в психометрике существует способ оценки синхронной надежности, который соответствует разбиению теста на такое количество частей, сколько в нем отдельных пунктов. Такова формула Кронбаха:
 (3.2.8)
(3.2.8)
где а - коэффициент Кронбаха;
k- количество пунктов теста;
 - дисперсия по j -му пункту теста;
- дисперсия по j -му пункту теста;
 - дисперсия суммарных баллов по всему тесту.
- дисперсия суммарных баллов по всему тесту.
Обратите внимание на структурное подобие формулы Кронбаха (3.2.2) и формулы Рюлона (3.2.8).
Несколько раньше была получена формула Кьюдера - Ричардсона, аналогичная формуле Кронбаха для частного случая - когда ответы на каждый пункт теста интерпретируются как дихотомические переменные с двумя значениями (1 и 0):

 (3.2.9)
(3.2.9)
где KR20 - традиционное обозначение получаемого коэффициента;
 -дисперсия i -и дихотомической переменной, какой является
-дисперсия i -и дихотомической переменной, какой является
i -й пункт теста; р = 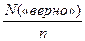 , q = 1 - p
, q = 1 - p
В 1957 г. Дж. Ките предложил следующий критерий для оценки статистической значимости коэффициента a:
 (3.2.10)
(3.2.10)
где  - эмпирическое значение статистики % квадрат с п-1 степенью свободы;
- эмпирическое значение статистики % квадрат с п-1 степенью свободы;
k - количество пунктов теста;
n - количество испытуемых;.
a - надежность.
Формулы (3.2.8) и (3.2.9) позволяют оценить взаимную согласованность пунктов теста, используя при этом только подсчет дисперсий. Однако коэффициенты а и KR2I> позволяют оценить и среднюю корреляцию между i -м и j -м произвольными пунктами теста, так как связаны с этой средней корреляцией следующей формулой:
 11)
11)
где  - средняя корреляция между пунктами теста. Легко увидеть идентичность формулы (3.2.11) обобщенной формуле Спирмена - Брауна, позволяющей прогнозировать повышения синхронной надежности теста с увеличением количества пунктов теста в k раз (Аванесов В. С., 1982, с. 121). Из этой формулы видно, что при больших k малое значение
- средняя корреляция между пунктами теста. Легко увидеть идентичность формулы (3.2.11) обобщенной формуле Спирмена - Брауна, позволяющей прогнозировать повышения синхронной надежности теста с увеличением количества пунктов теста в k раз (Аванесов В. С., 1982, с. 121). Из этой формулы видно, что при больших k малое значение  может сочетаться с высокой надежностью. Пусть = 0,1, a k =100, тогда по формуле (3.2.11)
может сочетаться с высокой надежностью. Пусть = 0,1, a k =100, тогда по формуле (3.2.11)

Широкое распространение компьютерных программ факторного анализа для исследования взаимоотношений между пунктами теста (по одномоментным данным) привело к обоснованию еще одной достаточно эффективной формулы надежности теста, которой легко воспользоваться, получив стандартную распечатку компьютерных результатов факторного анализа по методу главных компонент:
|
|
|
 (3.2.12)
(3.2.12)
где θ - коэффициент, получивший название тета-надежности теста;
k - количество пунктов теста;
λ1 - наибольшее значение характеристического корня матрицы
интеркорреляций пунктов (наибольшее собственное значение, или абсолютный вес первой главной компоненты).
Как и предыдущие формулы, формула (3.2.12) также относится к оценке надежности теста, направленного на измерение одной характеристики. Но, кроме того, она применима и для многофакторного теста, хотя и нуждается в пересчете после первоначального отбора пунктов, релевантных фактору (после того, как на основании многофакторного анализа отобраны пункты по одному фактору, снова проводится факторный анализ - только для этих отобранных пунктов).
Надежность отдельных пунктов теста. Надежность теста обеспечивается надежностью пунктов, из которых он состоит. Чтобы повысить ретестовую надежность теста в целом, надо отобрать из исходного набора пунктов, апробируемых в пилотажных психометрических экспериментах, такие пункты, на которые испытуемые дают устойчивые ответы. Для дихотомических пунктов (типа «решил - не решил», «да - нет») устойчивость удобно измерять с использованием четырехклеточной матрицы сопряженности:
Тест 1
Да Нет
| a | B |
| c | D |
Да Тест 2
Нет
Здесь в клеточке а суммируются ответы «Да», данные испытуемым при первом и втором тестировании, в клеточке b - число случаев, когда испытуемый при первом тестировании отвечал «Да», а при втором - «Нет» и т. д. В качестве меры корреляции вычисляется фи-коэффициент:
 (3.2.13)
(3.2.13)
Как известно, значимость фи-коэффициента определяется с по мощью критерия хи-квадрат:
 (3.2.14)
(3.2.14)
Если вычисленное значение хи-квадрат выше табличного с одной степенью свободы, то нулевая гипотеза (о нулевой устойчивости) отвергается. Удобство использования фи-коэффициента состоит в том, что он одновременно оценивает степень оптимальности данного пункта теста по силе (трудности): фи-коэффициент оказывается тем меньшим, чем сильнее частота ответов «да» отличается от частоты ответа «нет».
Кроме того, сама четырехклеточная матрица позволяет проследить возможную несимметричность в устойчивости ответов «да» и «нет» (это важнее для задач, чем для вопросов: например, может оказаться, что все испытуемые, уже решившие однажды данную задачу, решают ее при повторном тестировании; это наводит на мысль о том, что при втором тестировании происходит сбережение опыта, приобретенного при первом тестировании). Выявленные в результате такого анализа неустойчивые и неинформативные (слишком сильные или слишком слабые) пункты должны быть исключены из теста. Пункты следует считать недостаточно устойчивыми, если на репрезентативной выборке величина  превышает 0,71. При этом φ< 0,5.
превышает 0,71. При этом φ< 0,5.
Для т<?го чтобы повысить одномоментную (синхронную) надежность теста, следует из исходной пилотажной батареи пунктов отбросить те, которые плохо согласованы с остальными[12]. В отсутствие компьютера согласованность для пунктов также очень просто определяется с помощью четырехклеточной матрицы. В этом случае в первом столбце суммируются ответы испытуемых из «высокой».группы (пр величине суммарного балла), во втором столбце - из «низкой».
Высокая Низкая
| A | B |
| C | D |
Да
Нет
При нормальном распределении частот суммарных баллов «высокая» и «низкая» группы отсекаются справа и слева 27%-ными маргинальными квантилями (рис. 8).
Для оценки согласованности с суммарным баллом применяется полная[13] или упрощенная формула фи-коэффициента:
 (3.2.15)[14]
(3.2.15)[14]
где  - количество ответов «верно» («да») на i -й пункт теста;
- количество ответов «верно» («да») на i -й пункт теста;
N* - сумма всех элементов матрицы;
N* = n • 0,54 где n - объём выборки;
Pi = а + b - При включении в эстремальную группу 1/3 выборки
N* = 0,66 • n.

Рис. 8. Квантили «высокой» и «низкой» группы на графике распределения тестовых баллов
В некоторых случаях подобный анализ позволяет уточнить ключ для пункта: если пункт получает значимый положительный фи-коэффициент, то ключ определяется значением «+1», если пункт получает значимый отрицательный фи-коэффициент значением «-1». Если пункт получает незначимый фи-коэфф.ициент, то его целесообразно исключить из теста.
При ручных вычислениях фи-коэффициента удобно вначале с помощью формул (3.2.14) и (3.2.15) определить граничное значение значимого (по модулю) фи-коэффициента. Например, при объеме выборки в 100 человек и уровне значимости р < 0,01 пороговое значение вычисляется так:
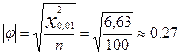 (3.2.16)
(3.2.16)
При постоянном использовании компьютера при подсчете суммарных баллов ключ для каждого пункта Q целесообразно определить в виде самого фи-коэффициента (или другого коэффициента корреляции), определенного при коррелировании ответов на пункт с суммарным баллом. Тогда тестовый балл подсчитывается по формуле
 (3.2.17)
(3.2.17)
где хi — суммарный балл i -го испытуемого;
 - ответ «верно» (+1) или «неверно» (-1) i -го испытуемого на i -й пункт;
- ответ «верно» (+1) или «неверно» (-1) i -го испытуемого на i -й пункт;
Сi- ключ для i -го пункта: С = +1 для прямого, С= -1 для обратного.
Более чувствительный коэффициент, который также применяется для дихотомических пунктов, - это точечный бисериальный коэффициент корреляции, учитывающий амплитуду отклонения индивидуальных суммарных баллов от среднего балла:
 3.2.18)
3.2.18)
где  x* - сумма финальных баллов тех индивидов, которые дали утвердительный ответ на i -й пункт теста (решили i -ю задачу);
x* - сумма финальных баллов тех индивидов, которые дали утвердительный ответ на i -й пункт теста (решили i -ю задачу);
Sx - стандартное отклонение для суммарных баллов всех индивидов из выборки;
 - стандартное отклонение по i -му пункту;
- стандартное отклонение по i -му пункту;
- средний балл по всем пунктам.
А. Анастази относит критерий внутренней согласованности теста к валидности (Анастази А., 1982, кн. 1, с. 143), однако если и можно в данном случае говорить о валидности, то только в смысле особой внутренней валидности теста. Как правило, слишком высокая согласованность снижает внешнюю валидность теста по критерию (см. раздел 3.3). Если проверяется согласованность пунктов, составленных одним автором (одним коллективом по стандартной инструкции), то выявление достаточного набора согласованных пунктов свидетельствует о внутренней валидности (согласованности) разработанного диагностического понятия (конструкта).
В компьютерных данных факторного анализа аналогом корреляции пункта с суммарным баллом является нагрузка пункта на ведущий фактор («факторная валидность» в терминах А. Анастази). Если прибегать к геометрическому изображению нагрузки как проекции вектора-пункта на ось-фактор, то структура пунктов хорошо согласованного теста предстанет в виде пучка векторов, плотно прилегающих к фактору и вытянувшихся вдоль его оси (рис. 9).

Рис. 9. Векторная модель соотношения «прямых» и «обратных» эмпирических пунктов с релевантным (измеряемым) фактором и иррелевантными («шумовыми») факторами
Последовательность действий при проверке надежности:
1. Узнать, существуют ли данные о надежности теста, предполагаемого к использованию, на какой популяции и в какой диагностической ситуации проводилась проверка. Если проверки не было или признаки новых популяции и ситуации явно специфичны, провести заново проверку надежности с учетом указанных ниже возможностей.
2. Произвести повторное тестирование на всей выборке стандартизации и подсчитать все коэффициенты, как для целого теста, так и для его отдельных пунктов. Анализ полученных коэффициентов позволит понять, насколько пренебрежима ошибка измерения, дает ли данный тест интервальную шкалу (высокий r) или только диагностичен для крайних групп (высокий φ), насколько устойчиво измеряемое свойство во времени (возможен ли статистический прогноз - проекция тестового балла на будущее), в каких своих пунктах тест менее надежен (анализ этих пунктов позволяет психологически осмыслить содержательный механизм взаимодействия пунктов с испытуемыми).
3. Если возможности обследования испытуемых ограниченны, произвести повторное тестирование только на части выборки (не менее 30 испытуемых), подсчитать (вручную) ранговую или четырех-клеточную корреляцию для оценки внутренней согласованности и стабильности теста в целом.
ВАЛИДНОСТЬ ТЕСТОВ
Проблемы валидизации психологических тестов являются центральными для дифференциальной психометрики, но, к сожалению, до сих пор решенными не до конца. Решение этой проблемы зависит не от статистического аппарата, а от уровня развития теоретического аппарата дифференциальной психологии.
Валидность и надежность. Валидность (или обоснованность) всякой процедуры измерения состоит в однозначности (устойчивости) получаемых результатов относительно измеряемых свойств объектов, т, е. относительно предмета измерения. Отличие понятия валидности от надежности измерения удобно раскрывать с помощью различения «объекта» и «предмета» измерения. Надежность - это устойчивость процедуры относительно объектов. Надежность не обязательно предполагает валидность. В психологии довольно часто возникает такая ситуация, когда исследователь вначале предлагает определенную процедуру измерения, показывает ее надежность -способность устойчиво различать объекты, но вопрос о валидности остается открытым.
Если в сенсорной психофизике вопрос о валидности измерений оказывается в значительной степени затушеванным тем обстоятельством, что простейшие физические стимулы достаточно однозначно детерминируют измеряемые свойства ощущений, то в дифференциальной психометрике значимость проблемы валидности резко возрастает. Здесь ситуация подобна той, когда в психофизическом опыте испытуемому не указывают, по какому именно параметру следует сравнивать стимулы. Пусть испытуемый А понял инструкцию так, что стимульные объекты надо сравнивать по весу, а испытуемый Б - по размеру. Если процедура измерения будет повторена по отношению к тем же объектам, то она даст вполне устойчивые данные относительно объектов, но не даст валидной информации ни о шкале ощущений «веса», ни о шкале ощущений «размера».
При измерении способностей предъявляемый тест отнюдь не обязательно актуализирует именно тот психический процесс, который предполагается измерить. Например, столкнувшись с уже встречавшейся однажды задачей (например, с анаграммой «дзиканпр»), испытуемый может начать запоминать просто то решение, к которому он уже однажды пришел (слово «праздник»), чем заново решать эту задачу. Здесь будет измеряться скорее уровень словесной памяти, чем уровень вербального интеллекта. Точно так же реальная валидность некоторых тестов раскрывается только в результате значительного опыта работы с ними. Например, доказано, что ряд тестов, внешне вы глядящих интеллектуальными, на деле измеряют скорее личностно-стилевые особенности индивида, чем операциональные возможности интеллекта, например, методика «креативного поля» Д. Б. Богоявленской.
Устойчивость теста относительно объектов (испытуемых) является необходимым, но не достаточным условием его устойчивости относительно измеряемых атрибутов (свойств) объектов. Надежность является необходимым, но не достаточным условием валидности. Отсюда вытекает основное соотношение психометрики:
валидность ≤ надежность.
Это означает, что валидность теста не может превышать его надежность.
Данное соотношение, однако, неверно трактовать как указание на прямую пропорциональную связь валидности и надежности. Повышение надежности отнюдь не обязательно приводит к повышению валидности[15]. В терминах А. Анастази валидность определяется репрезентативностью теста относительно измеряемой области поведения. Если эта область поведения складывается из разнообразных феноменов, то содержательная валидность теста автоматически требует представленности в нем моделей всех этих разнообразных феноменов. Возьмем глобальное понятие «речевая способность» (этому психолингвистическому термину в традиционной тестологии соответствует термин «вербальный интеллект»). Сюда относятся такие относительно независимые друг от друга навыки, как навыки письма и чтения. Если заботиться о содержательной валидности соответствующего теста, то нужно ввести в него группы заданий на проверку этих довольно разных по своему операциональному составу компонентов вербального интеллекта. Вводя разнородные пункты и субшкалы (субтесты), мы обязательно сокращаем внутреннюю согласованность, одномоментную надежность теста, но зато добиваемся существенного повышения валидности. Таким образом, для расширения области применения теста психодиагност должен избегать излишнего повышения внутренней согласованности. Одновременно с этим снижением внутренних корреляций между различными пунктами теста (об этом уже говорилось в разделе 3.1) обязательно исчезает отрицательный эксцесс на кривой распределения тестовых баллов, и она все более приближается по форме к нормальной кривой.
Эмпирическая валидность. Если в случае с содержательной ва-лидностью оценка теста производится за счет экспертов (устанавливающих соответствие заданий теста содержанию предмета измерения), то эмпирическая валидность измеряется всегда с помощью статистического коррелирования: подсчитывается корреляция двух рядов значений - баллов по тесту и показателей по внешнему параметру, избранному в качестве критерия валидности.
Прагматические традиции западной тестологии привязывали эмпирическую валидность теста к внешним для психологии социально-прагматическим критериям. Эти критерии являются показателями, обладающими непосредственной ценностью для определенных областей практики. Практика всегда имеет целью либо повысить, либо понизить эти показатели. Например, в области педагогической психологии это «успеваемость» (которую надо повысить), в психологии труда это «производительность труда» и «текучесть кадров», в медицине - «состояние здоровья пациента», в психологии управления -«совместимость», «срабатываемость» коллектива, в юридической психологии - «преступность» (которую надо понизить) и т. п.
Ориентируясь непосредственно на эти категории, психолог, пытающийся скоррелировать результаты теста с этими показателями, фактически решает сразу две задачи: задачу измерения валидности и задачу измерения практической эффективности своей психодиагностической программы. Если получен значимый коэффициент корреляции, то можно считать, что решены с позитивным результатом сразу обе эти задачи. Но если корреляции не обнаружено, то остается неопределенность: либо невалидна сама процедура (тестовый балл не отражает, например, стрессоустойчивость оператора), либо неверна гипотеза о наличии причинно-следственной связи между психическим свойством и социально значимым показателем (стрессоустойчивость не влияет на процент аварийных ситуаций).
Таким образом, социально-прагматические критерии являются комплексными: они позволяют измерить валидность-эффективность, но не каждое из этих двух свойств теста отдельно. На практике психолога часто ожидает и еще более сложная ситуация, когда заказчик требует от психолога на основании полученного диагноза сразу же определенных мер по вмешательству в ситуацию (отбор, консультирование, обучение и т. п.). В этом случае повышение показателей (достоверное по сравнению с контрольной группой) доказывает одновременно и валидность-эффективность диагностики, и эффективность самого вмешательства. А отрицательный результат дает еще большую неопределенность, так как оказывается невозможным отделить неэффективность вмешательства от низкой валидности диагностики.
Ориентация на социально-прагматические критерии, приводящие к склейке понятий «валидности измерения» и «причинного прогноза по результатам измерения», бесспорно, сдерживала и продолжает сдерживать развитие концептуального аппарата дифференциальной психологии. При этом суть самого предмета измерения: измеряемого психического свойства - оказывается вне фокуса внимания не только заказчика, но и самого психолога, превращающегося в этом случае в тестолога, которого не интересует, что именно он измеряет, главное лишь, чтобы от этого «нечто» перекидывался мостик к полезному эффекту, обеспечивающему психологу социальное признание.
Процедура эмпирической валидизации. Организация выборки при эмпирической валидизации зависит от временного статуса критерия. Если этот критерий - событие в прошлом (ретроспективная валидизация), то к участию в психодиагностическом обследовании достаточно привлечь только тех испытуемых, которые оказались на экстремальных полюсах по этому критерию[16]. В результате применяется метод экстремальных (контрастных) групп. Коррелирование с суммарным баллом по тесту оценивается с помощью бисериального коэффициента по формуле (3.2.17). При этом в статусе дихотомической переменной (на месте отдельного пункта) оказывается сам критерий валидности: x— сумма баллов по тесту, полученных «высокой» группой по критерию;  - стандартная ошибка критерия, связанная с численностью «высокой» (р) и «низкой» (q) групп.
- стандартная ошибка критерия, связанная с численностью «высокой» (р) и «низкой» (q) групп.
Если критерий - будущее событие (проспективная валидизация), то выборка должна быть составлена с запасом - с учетом вероятного объема экстремальных групп в будущем. Например, нужно выяснить, позволяет ли диагностика темперамента прогнозировать повышенный риск психосоматических заболеваний (гипертония, язва, астма и т. п.). Пусть на основании эпидемиологических исследований известно, что в течение трех лет из. 1000 здоровых людей этими болезнями заболевают 57 человек. Это означает, что превентивной (предупреждающей) диагностикой должно быть охвачено около 2000 человек, чтобы получить численность «высокой» группы (заболевших) порядка 100 человек. Проспективная валидизация выявляет прогностическую эффективность диагностической процедуры. Высокая прогностическая валидность доказывает как валидность самого измерения, так и наличие предполагаемой причинной связи.
Ретроспективная валидизация позволяет в лучшем случае решить только первую из двух задач. Например, если для исследования личностной предрасположенности к совершению краж проведено обследование лиц, находящихся под следствием (т. е. уже совершивших преступление), то выявление акцентированных черт «тревожности», «агрессивности» и т. п. еще не может интерпретироваться как свидетельство причинных факторов преступности - эти черты могут быть лишь следствием сложившихся обстоятельств: лишение свободы, угрызения совести и т. п. (Ратинов А. Р., 1979). Во многих медико-психологических исследованиях был выделен особый диагностический синдром «госпитализации», который обнаруживается у любой категории госпитализированных больных (обычно он выражается в повышении шкал «депрессии» и «ипохондрии» по MMPI – Шхвацабая, 1980). Очевидно, что подобные личностные сдвиги никак нельзя интерпретировать в смысле симптомов предрасположенности к определенным психогенным заболеваниям, ибо они относятся к следствиям, а не к причинам этих заболеваний.
Конструктная валидность. В отличие от прагматической валидизации собственно психологическую валидизацию порой оказывается провести гораздо труднее в силу отсутствия какого-либо более объективного внутрипсихологического критерия, чем сам тест.
Наиболее благополучная ситуация имеется тогда, когда для измерения данного свойства в психологии уже имеется процедура с известной валидностью. В этом случае корреляция между баллами двух тестов - линейная (см. формулу 3.2.3) или ранговая (см. формулу 3.2.5)- указывает на то, обладает ли новый тест конвергентной валидностью по отношению к старому. Если новый тест обнаруживает высокую конвергентность результатов со старым и одновременно оказывается более компактным и экономичным 'в проведении и подсчете, то психодиагносты получают возможность использовать новый тест вместо старого.
Однако во многих случаях для измеряемого свойства психодиагност не может найти в литературе ни одного уже апробированного теста с известной валидностью. В этом случае он может сформулировать ряд предсказательных гипотез о том, как будет коррелировать его новый тест с другими тестами, измеряющими родственные характеристики испытуемых. Эти гипотезы выдвигаются на основе теоретических представлений об измеряемом свойстве. Их подтверждение указывает на валидность выдвигаемого конструкта, т. е. на конструктную валидность теста. В западной литературе это операциональное определение конструктяой валыидности называется предполагаемой валидностью (assumed validity).
Представления о конструктной валидности тестов постоянно развиваются с пополнением репертуара методик. Эмпирические исследования взаимосвязей результатов, получаемых с помощью разных методик, обогащают теоретические представления об измеряемых свойствах.
С другой стороны, понятие конструктной валидности указывает на высокую зависимость эмпирических связей теста от теоретических представлений его автора об измеряемом свойстве. Для иллюстрации приведен пример взаимоотношений между двумя популярными тест-опросниками: MAS Ж. Тейлор и EPI Г. Айзенка. Многочисленные корреляционные исследования, проведенные на репрезентативных выборках, показали, что шкала MAS (тревожность) Ж. Тейлор положительно коррелирует со шкалой «нейротизм» и отрицательно со шкалой «экстраверсия» Айзенка. Эти соотношения можно проиллюстрировать графически (рис. 10): вектор MAS оказывается расположенным в квадранте «Нейротизм - Интроверсия», образованном системой из ортогональных (статистически независимых) факторов EPL С точки зрения концепции Г. Айзенка, эти данные можно рассматривать как свидетельства низкой валидности шкалы Ж. Тейлор: MAS коррелирует не только с релевантным фактором «нейротизм», но и с иррелевантным фактором «интроверсия». С этой точки зрения, опросник EPI оказывается просто нечувствительным к особой разновидности «нейротизма» - к нейротизму (тревожности) экстравертов; в перечне пунктов MAS отсутствуют высказывания, в которых могла бы проявиться тревожность экстраверта. Однако с точки зрения тоготеоретического смысла, который приписывают показателям MAS К. Спенс и Ж. Тейлор, эта ситуация вполне закономерна, желательна и никак не является артефактом - следствием дефекта их диагностического средства. Согласно К. Спенсу, пытавшемуся пе
|
|
|
