 |


Прогнозирование и распознавание образов
|
|
|
|
Кардинальное значение для психодиагностики имеет проблема прогнозирования. Существует точка зрения, разделяющая психодиагностику и так называемую психопрогностику (Забродин Ю. М., 1984). Это указывает на самостоятельное значение проблемы прогнозирования.
В действительности, любая психодиагностика служит прогнозированию - на больших или меньших отрезках времени. То, что называется диагностикой текущего состояния объекта, имеет следующий смысл. В технике сконструированный агрегат подвергают стендовым испытаниям. Полученные результаты приписывают текущему состоянию объекта, имея в виду, что выключенный агрегат до его эксплуатации в реальных условиях уже не будет изменяться сколь-нибудь существенным образом. При этом подразумевается, что именно при работе включенного агрегата может измениться его состояние, в частности, выход из допустимого режима.
В психологии дело, конечно же, обстоит по-другому. И перенос подразумеваемых, имплицитных представлений из технической диагностики в психодиагностику неправомерен, как, впрочем, неправомерен такой перенос уже и по отношению к медико-биологической диагностике человеческого организма. Организм человека, его психика - это не агрегат, который произвольно можно выключить на период от тестирования до реального испытания. Все это время человек продолжает жить, активно взаимодействовать со средой. Даже в изоляции, даже во сне мозг человека проделывает большую работу, переводя полученную информацию из одних отделов памяти в другие (Касаткин В. Н., 1967). Все это означает, что принцип статистической экстраполяции результатов психодиагностического измерения нельзя считать оправданным без проведения специальных проверок.
|
|
|
Когда психолог по результатам тестирования регистрирует у некоторого индивида А показатель Ха, а у некоторого индивида В показатель Хb, так что Хa> Хb, то из этого вовсе не следует автоматически, что соотношение Хa> Хb сохранится в течение следующей недели, месяца, года. Для принятия стратегии экстраполяционного статистического прогноза требуется предварительно произвести эмпирическое измерение надежности - устойчивости (ретестовой надежности) на заданном промежутке времени.
При этом важна не только длина отрезка времени между двумя измерениями, но и его заполненность теми или иными значимыми для индивида событиями. Приведем простой пример. Организовано психологическое обследование абитуриентов вуза. Психологи пытаются измерить уровень интереса поступающих к избранной специальности Однако они применяют «лобовые» методики опроса, не защищенные от преднамеренной фальсификации (абитуриенты сознательно, или даже бессознательно, будут искажать результаты в сторону повышенного интереса - чтобы произвести благоприятное впечатление). Фальсификация здесь - только один из возможных источников некорректности статистического прогноза. Для эмпирического измерения силы этого артефакта не обязательно проводить повторное измерение через несколько лет. Имеет смысл провести повторное обследование по той же методике всех студентов, сразу же после их зачисления на первый курс. Если возникнет слишком много перестановок типа Ха < Хb, то ранговая корреляция «тест -ретест» окажется слишком слабой, и это доказывает неправомерность использования «лобовой» методики для статического прогноза. Другой возможный источник нестабильности ранговой шкалы (порядковой шкалы теста) обусловлен в данном примере зависимостью уровня интереса к предметной области от уровня знаний о предмете. В ходе обучения в вузе студенты приобретают более детальные знания о предмете, о своей успешности в освоении специальности, и от этого уровень интереса может существенно изменяться. Конечно, этот фактор - в отличие от фактора фальсификации - действует на более длительных промежутках времени. И здесь опять же требуются специальные измерения ретестовой устойчивости для применения статического прогноза.
|
|
|
Приведенный выше пример показывает, что в некоторых случаях целесообразно начинать решать проблемы психопрогностики без всякого привлечения внешней по отношению к тесту критериальной информации, т. е. средствами проверки надежности, но не средствами проверки валидности. Если уже таким способом будет получен отрицательный результат, то заведомо будет получен и для измерения валидности статического прогноза (вспомним основной принцип: валидность методики не превышает ее надежность).
Однако надежность лишь необходимое, но, естественно, недостаточное условие прогностической валидности. Можно убедиться в высокой устойчивости тестового показателя на длительных промежутках времени, но из этого вовсе не следует, что будут получены значимые линейные корреляции этого показателя с требуемым критерием валидности -эффективности.- корреляции, оправдывающие статический прогноз.
Как правило, на основе диагностики принимаются решения, которые соотносятся между собой как события на шкале наименований или на шкале порядка. Каким образом учитываются сегодня при приеме в вуз показатели школьной успеваемости абитуриентов? Существуют три варианта, три градации, соотносимые друг с другом по шкале порядка: выпускникам школы - медалистам предоставляются льготные условия (при успехе на первом экзамене от остальных вступительных экзаменов медалист освобождается), лица с удовлетворительным средним баллом допускаются к конкурсным вступительным экзаменам и сдают все экзамены; наконец, лица с неудовлетворительным средним баллом могут вообще не допускаться к вступительным экзаменам. На этом примере видно, что средний балл аттестата используется как некоторый показатель «теста», в соответствии с которым абитуриентов разделяют на три категории, по отношению к которым неявно применяется «порядковый» прогноз: предполагается, что медалисты будут успешнее обычных выпускников школ, а обычные выпускники - успешнее тех, кто учился в школе очень слабо.
|
|
|
«Порядковый» прогноз сохраняет свою эффективность не только в статических условиях, но и в условиях таких динамических изменений объектов прогнозирования, при которых порядковая структура оказывается неизменной. Предположим, что в: ходе обучения в вузе все студенты по мере более глубокого ознакомления с предметом испытывают нарастающий интерес к своей специальности, но если порядковая структура сохраняется (Ха продолжает превышать Xb, несмотря на то что Xb приближается к Ха), то «порядковый» прогноз все равно остается корректным.
Линейные и порядковые прогностические стратегии на практике применяются не к одномерным, а к многомерным данным. Среди математических моделей прогнозирования до сих пор наибольшей популярностью пользуются относительно простые (а иногда и неоправданно упрощенные) регрессионные модели.
При этом для многомерного случая задача психометриста сводится к построению уравнения множественной регрессии:
 Y= ß1X1+ ß2X2…..+ ßiXi+ ßkXk (3.5.1)
Y= ß1X1+ ß2X2…..+ ßiXi+ ßkXk (3.5.1)
где Y- прогнозируемая переменная (критерий прогностической ва-лидности);
Xi - значение i -го тестового показателя из рассматриваемой батареи тестовых показателей;
ßi, - значение весового коэффициента, указывающего, на сколько (в единицах стандартных отклонений) изменяется прогнозируемая переменная при изменении тестового показателя Xi.
Для составления указанного уравнения требуется произвести «упреждающее» измерение тестовых показателей по отношению к критериальному показателю Y, измерение которого производится по истечении некоторого отрезка времени 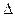 T, называемого в прогнозировании периодом упреждения.
T, называемого в прогнозировании периодом упреждения.
Общая эффективность прогноза на основе регрессионного уравнения оценивается с помощью подсчета коэффициента множественной корреляции R2 (Суходольский Г. В., 1972) и последующей оценки его значимости по критерию Фишера:
|
|
|
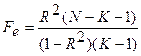 (3.5.2)
(3.5.2)
где  - эмпирическое значение статистики Фишера со степенями свободы V1 = k и У2 = N-k;
- эмпирическое значение статистики Фишера со степенями свободы V1 = k и У2 = N-k;
N— количество индивидов;
k - количество тестовых показателей.
Не следует забывать, что основой применения этой модели прогноза является экстраполяция - предположение о том, что на новом отрезке времени T’ будут действовать те же тенденции связи переменных, что и на отрезке T, на котором прежде измерялись весовые коэффициенты ßi. Не следует также забывать, что корректность прогноза обусловлена периодом упреждения: для больших (или меньших) T использование уравнения (3.5.1) может оказаться некорректным.
Прогностические возможности указанного метода ограничены однократностью измерения тестовых показателей.X1, Х2..., Xk. В силу однократности измерения этот метод оказывается эффективным опять-таки только по отношению к самым универсальным и статическим показателям (таким, например, как интегральные свойства темперамента или нервной системы), обеспечивающим очень грубый, вероятностный, приближенный прогноз.
В некоторых случаях эффективность этого метода может существенно повыситься, если использовать хотя бы двукратное (с небольшим интервалом в две-три недели) измерение системы показателей Х1 Х2,..., Xk. Уже таким способом можно, например, учесть вклад фактора «усвоение знаний» в прогнозирование мотивационной вовлеченности (уровня интереса) студента в свою специальность. Повторное измерение (например, через месяц после начала обучения в вузе) позволяет выявить, в каком направлении действует фактор «усвоение знаний» в своем влиянии на уровень интереса данного студента: может оказаться, что в результате разнонаправленного действия этого фактора немало пар студентов уже через месяц поменяются местами в ранговом ряду по уровню интереса (Ха< Хb). В этом случае в уравнение (3.5.1) целесообразно ввести не статический показатель Xi a простейший динамический показатель Хi, = 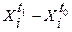 . Кроме того, не исключена возможность одновременного использования в уравнении (3.5.1) и статических Xi. и динамических Хi. показателей; тогда разработанная модель прогноза будет учитывать как достигнутый уровень (экстраполировать статику), так и намечающиеся тенденции (экстраполировать тенденции).
. Кроме того, не исключена возможность одновременного использования в уравнении (3.5.1) и статических Xi. и динамических Хi. показателей; тогда разработанная модель прогноза будет учитывать как достигнутый уровень (экстраполировать статику), так и намечающиеся тенденции (экстраполировать тенденции).
Приведем еще один содержательный пример. Многочисленные эмпирические исследования по прогнозированию супружеской совместимости (Обозов Н. Н., 1979) показали неудовлетворительно низкий уровень надежности прогноза на основе таких показателей, как однократно измеренный уровень сходства (темперамента, мотивов, интересов, ценностных ориентации) или взаимодополнительности психических свойств будущих супругов. Но эту надежность можно существенно повысить, если ввести в уравнение (3.5.1) показатели типа Х.. В данном случае содержательно-психологический смысл этих показателей будет заключаться в следующем: они указывают на то, в каком направлении действует на уровень сходства (совместимости) опыт взаимодействия будущих супругов. Потенциально несовместимые супруги в ходе взаимодействия (за период помолвки), как правило, дивергируют в своих показателях (например, имеющиеся незначительные акцентуации характера взаимно усиливаются). И наоборот, потенциально совместимые супруги могут очень быстро конвергировать: оказывается достаточным проведение одного-двух обсуждений с участием психолога по спорным вопросам, чтобы сблизиться в представлениях о желаемом семейном укладе и образе жизни.
|
|
|
Более сложные математические методы прогнозирования (например, учитывающие циклическую динамику объектов) пока еще редко используются в психодиагностике, так как требуют частых многократных измерений системы тестовых показателей, что оказывается невозможным по чисто практическим причинам. Тем не менее уже сегодня можно твердо констатировать недостаточность линейных моделей прогнозирования. Для ознакомления с рядом других подходов к прогнозированию мы рекомендуем психологам обратиться к руководству «Рабочая книга по прогнозированию» (М., 1982).
Остановимся теперь более подробно на подходе, который ныне представляет собой реальную альтернативу ограниченным линейным статистическим моделям и позволяет строить эффективный прогноз для более сложных зависимостей между прогнозируемыми (зависимыми) и прогнозирующими (независимыми) переменными. Этот подход, по традиции, принято называть распознаванием образов, так как разработка его математического аппарата была во многом стимулирована инженерными задачами конструирования искусственных систем зрения, слуха, других органов чувств (Распознавание образов. М., 1970).
В психодиагностике роль «элементарных сенсорных данных» выполняют первичные тестовые показатели X1 Х2,..., Xk, а роль «образа» (выходного сигнала системы) - соответствующая диагностическая категория. Таким образом, по существу, распознавание образов[19] и есть диагностика в широком смысле.
Поясним специфику подхода на простейшем схематическом примере. Пусть Ру -вероятность такого типового критерия оценки студентов, как успеваемость, Х1 - уровень интереса к специальности, выявленный у абитуриента, Х2 - уровень его знаний о специальности.
На рис. 16 точки X1 = 0 и Х2 = 0 - медианные значения соответствующих тестовых показателей. В данном упрощенном примере в статусе «образа» выступает каждый из четырех квадрантов диагностического пространства. Для предсказания Ру мы не можем построить линейной комбинации Х1 и Х2, какие бы коэффициенты ß1, и ß2 мы ни взяли. Для предсказания Рy мы должны зафиксировать попадание индивида в заданную область пространства параметров. «Образ», или диагностическая категория, и есть на геометрическом языке определенная область в пространстве параметров.

Рис. 16. Зависимость вероятности критериального события р и диагностических параметров X1 и Х2
С точки зрения распознавания образов, предварительная задача диагностики (предваряющая практические задачи) – определить границы диагностических категорий - областей в пространстве параметров, которым эмпирически корректно могут быть приписаны некоторые пороговые (качественно специфичные) значения прогнозируемого критериального показателя. Это задача построения «разделяющего правила» (или «решающего правила»). Точность такого разделения и предопределяет прогностическую валидность методики на данной совокупности испытуемых в данной диагностической ситуации.
Репрезентативность выборки при этом определяется степенью изменения точности разделения при увеличении совокупности обследованных. Влияние того или иного параметра на точность разделения определяет «вес», с которым входит данный параметр в задачу диагностики.
Построение формальной процедуры разделения может производиться по-разному. В простейшем случае - это сравнение тестового показателя с некоторым порогом. В более сложных случаях применяются методы дискриминантного анализа, позволяющие описывать «разделяющие правила» (границы диагностических областей в пространстве параметров) в виде сложных функций сразу от нескольких параметров.
Применение определенного метода для решения задачи построения системы диагностических категорий определяется несколькими факторами: во-первых, это соответствие допущений, положенных в основу алгоритма, содержательным представлениям о психологической типологии индивидов в рамках рассматриваемой системы психодиагностических параметров; во-вторых, это степень полноты имеющейся информации для эффективной «остановки» алгоритма, обеспечивающей оптимальное решение задачи за приемлемое время.
Под полнотой информации здесь, имеется в виду наличие достаточно многочисленных групп индивидов, четко и однозначно классифицированных по заданной системе критериев. В этом случае построение решающего правила сводится к применению какого-либо алгоритма автоматической классификации, приспособленного к работе с заданными классами. Если же критериальные классы представлены неполно - всего несколькими представителями, для которых при этом не всегда известны все значения необходимых параметров, - то возникает ситуация, требующая применения так называемых эвристических алгоритмов (более подробно о применяемых алгоритмах классификации см. кн.: Типология и классификация в социологических исследованиях. М., 1982).
Остановимся на одном из методов распознавания, получившем применение в психодиагностике, — на семействе алгоритмов вычисления оценок (АВО), предложенном Ю. И. Журавлевым и его учениками (1978).
Основную задачу распознавания образов можно сформулировать как задачу отнесения объекта 5 к одному или нескольким классам К1 К2,..., Кi на основе информации о классах I (K1), (К2),..., I (Кi), информации об объекте I (S) и предположения о близости объекта к классу. Другими словами, задачу распознавания можно сформулировать как задачу определения того, обладает ли объект определенными свойствами.
В основе АВО лежит принцип частичной прецедентности: близость объекта к классу тем больше, чем больше частей в его описании «похожи» на соответствующие части в описаниях' объектов, чья принадлежность классу известна. Например, в одном из вариантов АВО (Зеличенко А. И., 1982) функция близости объекта S к классу К определяется так:
 (3.5.3)
(3.5.3)

где  - i -й объект, принадлежность которого к классу К уже известна;
- i -й объект, принадлежность которого к классу К уже известна;
ai (S) - i -й элемент (параметр) в описании объекта;
P1 - его вес;
εj - i -й порог.
После того как вычислены Г(S1 K1,),..., Г(S1 K1,) на основании некоторого решающего правила (зависящего от вектора параметров  , принимается решение о принадлежности объекта к одному или нескольким классам К1,..., К1 В задачах психодиагностики S- это испытуемый.
, принимается решение о принадлежности объекта к одному или нескольким классам К1,..., К1 В задачах психодиагностики S- это испытуемый.
Таким образом, каждый вариант АВО определяется набором значений параметров. В нашем случае- это векторы  ,
,  . Если информация об объекте S представлена в виде I(S) = (а1,..., а2), то элемент вектора опорных множеств ωj(S) = аi, a εj - j -й порог.
. Если информация об объекте S представлена в виде I(S) = (а1,..., а2), то элемент вектора опорных множеств ωj(S) = аi, a εj - j -й порог.
В качестве примера решающего правила можно привести следующее (линейное пороговое решающее правило):
объект S принадлежит к классу Kt если
 (3.5.4)
(3.5.4)
объект S не принадлежит к классу Kt если
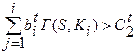 (3.5.5)
(3.5.5)
в остальных случаях -отказ от распознавания принадлежности объекта S к классу Kt.
В работе алгоритмов распознавания вообще и АВО в частности можно выделить два этапа: обучение и собственно распознавание. На этапе обучения, как уже говорилось, происходит настройка алгоритма, т. е. выбор таких его параметров, которые обеспечивают оптимальное в нег котором смысле распознавание объектов обучающей выборки (объектов, принадлежность которых к классам К1,...,Ki, известна). На этапе собственно распознавания происходит отнесение к классам K1,..., Кi, тех объектов, принадлежность которых к классам априорно неизвестна.
Точность распознавания на этапе обучения измеряется полнотой и адекватностью распознавания эталонных объектов. Наряду с понятием «точность» (абсолютная отделимость) иногда удобно использовать понятие относительной отделимости объектов обучающей выборки, принадлежащих к различным классам. В случае, когда распознавание ведется для двух классов (например, в профориентации - для дифференциального прогноза успешности оптанта в одной из двух профессиональных областей), относительную отделимость можно определить как
 (3.5.6)
(3.5.6)
где X - точность при обучении (выраженная в процентах), a  -минимальная возможная точность обучения (совпадает с долей объектов в наибольшем классе от общего объема обучающей выборки). На этапе собственно распознавания точность характеризует главным образом репрезентативность обучающей выборки (выборки валидизации). Чем выше репрезентативность, тем больше совпадают показателе точности на этапах обучения и собственно распознавания.
-минимальная возможная точность обучения (совпадает с долей объектов в наибольшем классе от общего объема обучающей выборки). На этапе собственно распознавания точность характеризует главным образом репрезентативность обучающей выборки (выборки валидизации). Чем выше репрезентативность, тем больше совпадают показателе точности на этапах обучения и собственно распознавания.
Использование АВО кроме решения задачи распознавания позволяет получить следующую информацию:
1. Информационные веса отдельных элементов (параметров) описания объектов. Эти веса измеряются через изменение точности распознавания при исключении соответствующих параметров из описания эталонных объектов:
 (3.5.7)
(3.5.7)
где X - точность распознавания при Рj = 1; X ( ) - точность распознавания при Р. = 0, а а - нормирующий множитель. Информационные веса интерпретируются как мера прогностической важности параметров.
) - точность распознавания при Р. = 0, а а - нормирующий множитель. Информационные веса интерпретируются как мера прогностической важности параметров.
2. Оптимальные значения порогов  , т. е. значения , обеспечивающие наивысшую точность распознавания. Эти значения порогов в нашем случае можно.интерпретировать как чувствительность методики; εj - своего рода дифференциальный порог на шкале тестового показателя a j определяющий переход индивида из одной диагностической категории в другую. Пусть на этапе разработки теста (тестовой батареи) была обследована группа из К человек, про которых известно, что k1 из них относится к одному классу, а К2 - к другому, К = К1 + К2. Выбрав случайным образом из этой группы М (М<<К) многомерных описаний, проводим на них процедуру обучения алгоритма. Точность обучения характеризует валидность теста. После этого применяем процедуру собственно распознавания (по выработанному решающему правилу) для остальных К-М описаний. В результате этой процедуры мы определяем принадлежность респондентов (испытуемых) к этим классам. Сравнивая полученные результаты с эталонными данными о принадлежности испытуемых к классам, мы определяем точность самого распознавания. Если эта точность близка к точности обучения, то наша пилотажная выборка объемом М может быть признана репрезентативной для обучения. Теперь можно переходить к задаче определения информационных весов.
, т. е. значения , обеспечивающие наивысшую точность распознавания. Эти значения порогов в нашем случае можно.интерпретировать как чувствительность методики; εj - своего рода дифференциальный порог на шкале тестового показателя a j определяющий переход индивида из одной диагностической категории в другую. Пусть на этапе разработки теста (тестовой батареи) была обследована группа из К человек, про которых известно, что k1 из них относится к одному классу, а К2 - к другому, К = К1 + К2. Выбрав случайным образом из этой группы М (М<<К) многомерных описаний, проводим на них процедуру обучения алгоритма. Точность обучения характеризует валидность теста. После этого применяем процедуру собственно распознавания (по выработанному решающему правилу) для остальных К-М описаний. В результате этой процедуры мы определяем принадлежность респондентов (испытуемых) к этим классам. Сравнивая полученные результаты с эталонными данными о принадлежности испытуемых к классам, мы определяем точность самого распознавания. Если эта точность близка к точности обучения, то наша пилотажная выборка объемом М может быть признана репрезентативной для обучения. Теперь можно переходить к задаче определения информационных весов.
* * *
Для эффективного использования алгоритмов распознавания по отношению к многомерным тестовым системам (при K >3), как правило, требуется использование компьютера.
При решении задач небольших размерностей (по количеству параметров) иногда психолог может быстрее найти решающее правило, применяя собственные способности зрительной системы (очень мощные) к визуально-геометрической группировке объектов. В пространстве параметров диагностические, классы выглядят как «сгущения», некие «облака» из точек, изображающих испытуемых. В этом случае при наличии априорной информации о принадлежности индивидов к классам удобно изображать точки из различных классов разными цветами (хуже - квадратиками, кружками, треугольниками). В этом случае «решающее правило» легко «увидеть» как некую воображаемую линию (прямую или кривую), разделяющую точки разного цвета (рис. 17). Точность диагностики в данном случае можно оценить по количеству точек, попавших при данном решающем правиле в «чужую» половину пространства параметров.
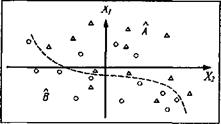
Рис.17. Разделение двух классов объектов (изображены кружками и треугольниками) в пространстве двух параметров X1, и Х2
Точность правила, изображенного на рис. 17, равна:

A
B

Здесь в четырехклеточной матрице сопряженности по строкам задано попадание объекта в один из априорных классов А (треугольники на рис. 17) или В (кружочки на рис. 17), а по столбцам - попадание объектов в один из апостериорных классов, образованных применением решающего правила, - (слева от критериальной линии) или (справа от критериальной линии). Как указано выше, для статистической оценки точности может быть использован фи-коэффициент, связанный по известной формуле с критерием хи-квадрат.
|
|
|
