 |


Реализация ввода/вывода по прерываниям
|
|
|
|
При реализации ввода/вывода по прерываниям необходимо дать ответы на два вопроса. Во-первых, определить, каким образом ЦП может выяснить, какой из МВВ и какое из подключенных к этому модулю внешних устройств выставили запрос. Во-вторых, при множественных прерываниях требуется решить, какое из них должно быть обслужено в первую очередь.
Сначала рассмотрим вопрос идентификации устройства. Здесь возможны три основных метода:
- множественные линии прерывания;
- программная идентификация;
- векторное прерывание.
Наиболее простой подход к решению проблемы определения источника запроса — применение множественных линий прерывания между ЦП и модулями ввода/вывода, хотя выделение слишком большого количества управляющих линий для этих целей нерационально. Более того, даже если присутствует несколько линий прерывания, желательно, чтобы каждая линия использовалась всеми МВБ. при этом для каждой линии действует один из двух остальных методов идентификации устройства.
При программной идентификации, обнаружив запрос прерывания, ЦП переходит к общей программе обработки прерывания, задачей которой является опрос всех МВБ с целью определения источника запроса. Для этого может быть выделена специальная командная линия опроса. ЦП помещает на адресную шину адрес опрашиваемого МВВ и формирует на этой линии сигнал опроса. Реакция модуля зависит от того, выставлял он запрос или нет. Возможен и иной вариант, когда каждый МВВ включает в себя адресуемый регистр состояния. Тогда ЦП считывает содержимое PC каждого модуля, после чего выясняет источник прерывания. Когда источник прерывания установлен, ЦП переходит к программе обработки прерывания, соответствующей этому источнику. Недостаток метода программной идентификации заключается в больших временных потерях.
|
|
|
Наиболее эффективную процедуру идентификации источника прерывания обеспечивают аппаратурные методы, в основе которых лежит идея векторного прерывания. В этом случае, получив подтверждение прерывания от процессора, выставившее запрос устройство выдает на шину данных специальное слово, называемое вектором прерывания. Слово содержит либо адрес МВБ, либо какой-нибудь другой уникальный идентификатор, который ЦП интерпретирует как указатель на соответствующую программу обработки прерывания. Такой подход устраняет необходимость в предварительных действиях с целью определения источника запроса прерывания. Реализуется он с помощью хранящейся в ОП таблицы векторов прерывания (рис. 8,8), где содержатся адреса программ обработки прерываний. Входом в таблицу служит вектор прерывания. Начальный адрес таблицы (база) обычно задается неявно, то есть под таблицу отводится вполне определенная область памяти.
Наиболее распространены два варианта векторной идентификации источника запроса прерывания: цепочечный опрос и арбитраж шины.

Рис. 8.8. Идентификация запроса с помощью вектора прерывания
При цепочечном методе для передачи запроса прерывания модули ввода/вывода совместно используют одну общую линию. Линия подтверждения прерывания последовательно проходит через все МВВ. Когда ЦП обнаруживает запрос прерывания, он посылает сигнал по линии подтверждения прерывания. Этот сигнал движется через цепочку модулей, пока не достигнет того, который выставил запрос. Запросивший модуль реагирует путем выдачи на шину данных своего вектора прерывания.
В варианте арбитража шипы МВБ, прежде чем выставить запрос на линии запроса прерывания, должен получить право на управление шиной. Таким образом, в каждый момент времени активизировать линию запроса прерывания может только один из модулей. Когда ЦП обнаруживает прерывание, он отвечает по линии подтверждения. После этого запросивший модуль помещает на шину данных свой вектор прерывания.
|
|
|
Перечисленные методы служат не только для идентификации запросившего МВВ, но и для назначения приоритетов, когда прерывание запрашивают несколько устройств. При множественных линиях запроса ЦП начинает с линии, имеющей наивысший приоритет. В варианте программной идентификации приоритет модулей определяется очередностью их проверки. Для цепочечного метода приоритет модулей определяется порядком их следования в цепочке.
Прямой доступ к памяти
Хотя ввод/вывод по прерываниям эффективнее программно управляемого, оба этих метода страдают двумя недостатками:
- темп передачи при вводе/выводе ограничен скоростью, с которой ЦП в состоянии опросить и обслужить устройство;
- ЦП вовлечен в управление передачей, для каждой пересылки он должен выполнить определенное количество команд.
Когда пересылаются большие объемы данных, требуется более эффективны;: способ ввода/вывода— прямой доступ к памяти (ПДП). ПДП предполагает наличие на системной шине дополнительного модуля — контроллера прямого доступа к памяти (КПДП), способного брать на себя функции ЦП по управлению системной шиной и обеспечивать прямую пересылку информации между ОП и ВУ. без участия центрального процессора. В сущности, КПДП — это и есть модуль ввода/вывода, реализующий режим прямого доступа к памяти.
Если ЦП желает прочитать или записать блок данных, он прежде всего должен поместить в КПДП (рис. 8.9) информацию, характеризующую предстоящее действие. Этот процесс называется инициализацией КПДП и включает в себя занесение в контроллер следующих четырех параметров:
вида запроса (чтение или запись);
адреса устройства в в од а/вы во да;
адреса начальной ячейки блока памяти, откуда будет извлекаться или куда будет вводиться информация;
количества слов, подлежащих чтению или записи.

Рис. 8.9. Организация прямого доступа к памяти
Первый параметр определяет направление пересылки данных: из ОП в ВУ или наоборот. За исходную точку обычно принимается память, поэтому под чтением понимают считывание данных из ОП и выдачу их на устройство вывода, а под записью — прием данных из устройства ввода и запись в ОП. Вид запроса запоминается в схеме логики управления контроллера.
|
|
|
К КПДП обычно могут быть подключены несколько ВУ, а адрес УВВ конкретизирует, какое из них должно участвовать в предстоящем обмене данными. Этот адрес запоминается в логике управления КПДП.
Третий параметр — адрес начальной ячейки — хранится в регистре адреса (РА) контроллера. После передачи каждого слова содержимое РА автоматически увеличивается на единицу, то есть в нем формируется адрес следующей ячейки ОП.
Размер блока в словах заносится в счетчик данных (СД) контроллера. После передачи каждого слова содержимое СД автоматически уменьшается на единицу. Нулевое состояние СД свидетельствует о том, что пересылка блока данных завершена.
После инициализации процесс пересылки информации может быть начат в любой момент. Инициаторами обмена вправе выступать как ЦП, так и ВУ. Устройство, желающее начать В/ВЫВ, извещает об этом контроллер подачей соответствующего сигнала. Получив такой сигнал, КПДП выдает в ЦП сигнал «Запрос ПДП». В ответ ЦП освобождает шины адреса и данных, а также тс линии шины управления, по которым передаются сигналы, управляющие операциями на шине адреса (IIIА) и шине данных (ШД). К таким, прежде всего, относятся линии ЧтЗУ, ЗпЗУ, Выв, Вв и линия выдачи адреса на 111 А. Далее ЦП отвечает контроллеру сигналом «Подтверждение ПДП», который для последнего означает, что ему делегированы права на управление системной шиной и можно приступать к пересылке данных.
Процесс пересылки каждого слова блока состоит из двух этапов.
При выполнении операции чтения (ОП →ВУ) на первом этапе КПДП выставляет на шину адреса содержимое РА (адрес текущей ячейки ОП) и формирует сигнал ЧтЗУ. Считанное из ячейки ОП слово помещается на шину данных. На втором этапе КПДП выставляет на ША адрес устройства вывода и формирует сигнал Выв, который обеспечивает передачу слова с шины данных в ВУ.
|
|
|
При выполнении операции записи (ВУ -> ОП) КПДП сначала выдает на шину данных адрес устройства ввода и формирует сигнал Вв, по которому введенные данные поступают на шину данных. На втором этапе КПДП помещает на ША адрес ячейки ОП, куда должны быть занесены данные, и выдает сигнал ЗпЗУ. Этим сигналом информация с ШД записывается в ячейку ОП.
Как при чтении, так и при записи происходит буферизация пересылаемого слова в регистре данных (РД) контроллера. Это необходимо для компенсации различий в скорости работы ОП и ВУ, в силу чего сигналы Выв и Вв формируются контроллером лишь при получении от ВУ подтверждения о готовности. Буферизация сводится к тому, что после первого этапа слово с ШД заносится в РД, а перед вторым — возвращается из РД на шину данных.
После пересылки каждого слова логика управления прибавляет единицу к содержимому РА (формирует адрес следующей ячейки ОП) и уменьшает на единицу содержимое СД (ведет подсчет переданных слов).
Когда пересылка завершена (при нулевом значении в СД), КПДП снимает сигнал «Запрос ПДП», в ответ на что ЦП снимает сигнал «Подтверждение ПДП» и вновь берет на себя управление системной шиной, то есть ЦП вовлечен в процесс ввода/вывода только в начале и конце передачи.
Эффективность ПДП зависит от того, каким образом реализовано распределение системной шины между ЦП и КПДП в процессе пересылки блока. Здесь может применяться один из трех режимов:
- блочная пересылка;
- пропуск цикла;
- прозрачный режим.
При блочной пересылке КПДП полностью захватывает системную шину с момента начала пересылки и до момента завершения передачи всего блока. На весь этот период ЦП не имеет доступа к шине.
В режиме пропуска цикла КПДП после передачи каждого слова на один цикл шины освобождает системную шину, предоставляя ее на это время процессору. Поскольку КПДП все равно должен ждать готовности ПУ, это позволяет ЦП эффективно распорядиться данным обстоятельством.
В прозрачном режиме КПДП имеет доступ к системной шине только в тех циклах, когда ЦП в ней не нуждается. Это обеспечивает наиболее эффективную работу процессора, но может существенно замедлять операцию пересылки блока данных. Здесь многое зависит от решаемой задачи, поскольку именно она определяет интенсивность использования шины процессором.
В отличие от обычного прерывания в пределах цикла команды имеется несколько точек, где КПДП вправе захватить шину (рис 8.10). Отметим, что это не прерывание: процессору не нужно запоминать контекст задачи.
|
|
|
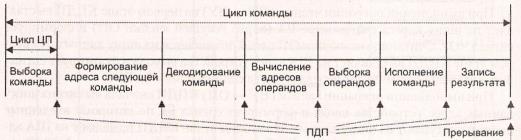
Рис. 8.10. Точки возможного вмешательства в цикл команды при прямом доступе к памяти и при обычном прерывании
Механизм ПДП может быть реализован различными путями. Некоторые возможности показаны на рис. 8.11.
В первом примере (см. рис. 8.11, а) все ВУ совместно используют общую системную шину. КПДП работает как заменитель ЦП и обмен данными между памятью и ВУ через КПДП производит через программно управляемый ввод/вывод. Хотя этот вариант может быть достаточно дешевым, эффективность его невысока. Как и в случае программно управляемого ввода/вывода, осуществляемого процессором, каждая пересылка требует двух циклов шины.

Рис. 8.11. Возможные конфигурации систем прямого доступа к памяти
Число необходимых циклов шины может быть уменьшено при объединении функций КПДП и ВУ. Как видно из рис. 8.11, б, это означает, что между КПДП и одним или несколькими ВУ есть другой тракт, не включающий системную шину. Логика ПДП может быть частью ВУ, либо это может быть отдельный КПДП, управляющий одним или несколькими внешними устройствами. Допустим и еще один шаг в том же направлении (см. рис. 8.11, в) — соединение КПДП с ВУ посредством шины ввода/вывода. Это уменьшает число интерфейсов В/ВЫВ в КПДП и делает такую конфигурацию легко расширяемой. В двух последних вариантах системная шина задействуется КПДП только для обмена данными е памятью. Обмен данными между КПДП и ВУ реализуется минуя системную шину.
|
|
|
