 |


Этапы изучения web-графа и его моделирование.
|
|
|
|
Оглавление.
Введение........................................................................................................................................ 3
Web-граф. Применение и ценность исследования............................................................... 3
Этапы изучения web-графа и его моделирование................................................................. 4
Цели и задачи этой работы...................................................................................................... 7
Модели Web-графа........................................................................................................................ 8
Модель ACL............................................................................................................................... 8
Модель “Развивающейся” сети.............................................................................................. 10
Копирующая модель сети....................................................................................................... 12
Модель “Растущей сети”........................................................................................................ 13
Многослойная модель............................................................................................................. 14
Заключение.................................................................................................................................. 16
Библиография.............................................................................................................................. 17
Введение.
Web-граф. Применение и ценность исследования.
Под Web-графом понимается орграф, вершинами которого являются документы (в основном статические html страницы) сети Интернет, а дугами – гипертекстовые ссылки между ними. Изучение его свойств представляет большой научный интерес и имеет огромную практическую ценность. Основная область применения накопленных о Web-графе данных – информационно поисковые системы (ИПС), такие как Google, MSN, Altavista.
Подавляющее большинство запросов пользователей содержат не более 3-5 слов, и число релевантных им документов измеряется десятками тысяч. Естественно, пользователю предоставляются ссылки на первые 10-15 самых “лучших” страниц. Ранжирование результатов поиска производится по присвоенным им рейтингам. Существует огромное число алгоритмов, для определения “важности” ресурса сети. Прорывом в методах ранжирования стал алгоритм PageRank [1] компании Google: превосходя конкурентов более качественным поиском, она быстро стала лидером рынка. На данный момент ни одна крупная ИПС не может обойтись без подобного алгоритма. PageRank в качестве рейтинга страницы использует взвешенное отношение суммы рейтингов ссылающихся на страницу ресурсов к количеству исходящих из них ссылок. Реализация подобного подхода невозможна без использования web-графа.
|
|
|
Наряду с web-графом исследуются также такие структуры как:
· Хост -граф (Host graph). Орграф вершинами которого являются web узлы. Дуга между вершинами A и B существует, если существует хоть одна web страница узла A имеющая гипертекстовую ссылку на одну из web страниц узла B.
· Cosine-граф (Cosine graph). Неориентированный граф, вершинами которого являются web узлы. А дуги имеют вес равный cosine дистанции между векторами терминов соответствующих страниц
· Граф цитирования (Co-citation graph). Неориентированный граф вершинами которого являются web узлы. Весом дуги E(x,y) между вершинами x и y является число страниц ссылающихся и на страницу x и на страницу y.
· Пиринговый граф (Gnutella graph). Орграф, вершинами которого являются хосты пиринговых программ, таких как Gnutella, Napster, Morpheus и т.п. А дугами – соединения между ними.
· Интернет-граф (Internet graph). Неориентированный граф, представляющий физическое соединение компьютеров в Интернет.
· Коммуникационный граф (Communication graph). Взвешенный неориентированный граф, вершинами которого являются хосты, а дугами – соединения между ними. Весом дуги является количество информации проходящей по соответствующей линии связи.
· Роутинг граф (Routing graph). Представляет движение пакетов в сети Интернет.
|
|
|
Удивительно, но web-граф имеет во многом схожие свойства со многими вышеперечисленными структурами.
Одним из направлений в исследовании web-графа является его моделирование. Получить Web-граф всей сети невозможно – размеры ее огромны. Каждая ИПС имеет сеть роботов-пауков, производящих индексирование ресурсов сети и накапливающих информацию о них в специальных хранилищах данных. Со временем появляются новые ресурсы, исчезают, либо перемещаются уже проиндексированные – поэтому, процесс исследования сети пауками непрерывен. Периодически происходит обновление рабочей базы данных ИПС (раз в 1-2 недели, для крупных ИПС – раз в месяц). В настоящий момент наибольшим числом проиндексированных сайтов может похвастаться компания Google -.... Непроиндексированными же остаются многочисленные форумы, блоги, файлы неподдерживаемых форматов, динамически создаваемые и просто труднодоступные для пауков страницы. Эту часть сети принято называть невидимой (“Invisible Web”). По различным оценкам, она превосходит видимую часть от 10 до 500 раз.
Многие ИПС, заинтересованные в более качественном ранжировании результатов поиска, предоставляют данные, собранные пауками, для изучения. Но размеры этих данных делают эксперименты над ними чрезвычайно трудоемкими, что затрудняет создание эффективных алгоритмов. Работа с полноценным web-графом может вестись только на высокопроизводительных серверах. Для примера, приведем сведения о экспериментальных данных, использованных при создании алгоритма BlockRank [2]. Работа алгоритма на web-графе, созданном в рамках проекта “Stanford WebBase” в январе 2001г., размером в 290 млн. вершин и чуть более миллиарда дуг, на AMD Athlon 1533MHz с дисковым массивом RAID-5 и3.5Гб оперативной памяти, требовала около 100 итераций по 7 минут каждая. Представление web-графа на внешних носителях потребовало 6Гб памяти, и это – очень небольшой web-граф.
На практике используют “мини” web-графы, сгенерированные на основе некоторой модели. Основная задача моделирования web-графа – охватить все его особенности, в связи с этим, создание новой модели обычно являлось ответом на обнаружение неизвестных свойств web-графа. Рассмотрим основные, известные на данный момент, свойства web-графа и модели, их отражающие:
|
|
|
Этапы изучения web-графа и его моделирование.
· Первой моделью web-графа являлась модель Erdös-Renyi [3]. Конечные вершины для исходящих дуг в этой модели выбираются случайным образом из всех вершин графа. В частности, для моделирования web-графа применялась модель с среднем числом исходящих из каждой вершины дуг равным 7. Более глубокий анализ полученных на практике данных показал неадекватность модели Erdös-Renyi настоящим web-графам.
· В 1999г. R. Kumar [4] и независимо A.L. Barabasi и A. Albert [5] обнаружили, что число входящих в вершину дуг имеет экспоненциально распределение с коэффициентом 2.1. Также ими было выдвинуто предположение о том что и число исходящих дуг имеет экспоненциальное распределение с коэффициентом 2.7. Следует отметить, что последнее утверждение не является бесспорным [6].
· Первой моделью, реализовавшая это свойство считается модель Aiello, Chung и Lu [7], хотя она и предназначена для отображения трафика телефонных звонков.[1] Немного позднее Albert, Barabasi and Jeong [8] предложили модель “Развивающейся сети”, в которой на каждой итерации к графу добавляется новая вершина и соединяется с некоторым числом вершин графа. Если выбрать эту константу равной 7-и, то коэффициент распределения будет около 2.
· В том же году A. Border [9] обнаружил удивительное свойство web-графа. На макроскопическом уровне он имеет структуру “бабочки”. Ее центром является группа страниц, образующих компонент сильной связности (SCC). Также имеются страницы, ссылающиеся на центральную группу (IN), страницы на которые ссылается центральная группа (OUT) и группа несвязных с ними страниц. Существуют также “трубы” – ссылки между “крыльями” бабочки. В web-графе размером 200 млн. страниц, предоставленным компанией Alexa в 1997г. было обнаружено свыше 100000 подобных сообществ.

рис 1. Структура “бабочки”.
· Также A. Border показал, что вероятность существования пути между двумя случайно выбранными вершинами web-графа равна 24%, а средняя длина такого пути равна 16.
|
|
|
· В работах J. Kleinberg [10] и D. Watts [11] был обнаружен свойственный web-графу феномен “Малого мира” (Small world phenomen), типичный для динамических социальных сетей.[2] За исключением небольшого процента дуг, почти все страницы достижимы из любой другой через огромный центральный компонент связности, объединяющий около 90% вершин web-графа.
· В структуре web-графа также было выделено удивительно большое число специфических топологических структур, таких как двудольные клики небольшого размера (3-10 страниц). Это связывают с наличием неявных кибер-сообществ: групп ресурсов сходной тематики, имеющих общие “авторитетные” страницы. Двудольные клики интерпретируются как ядро подобных сообществ – они состоят из множества “фанатских” и “авторитетных” страниц, причем все страницы из первого множества ссылаются на страницы второго.[3]
· Для реализации вышеназванных свойств, в частности существования кибер-сообществ R. Kumar [12] в 2000г. предложил “Копирующую модель”. Она похожа на модель развивающейся сети, но новые вершины соединяется с некоторым постоянным числом уже имеющихся вершин с некоторой вероятностью. (т.н. фактор копирования) Автор предложил 2 модификации алгоритма: в первой на каждой итерации добавляется постоянное (обычно 1) число вершин (линейная модель), во второй – это число является функцией от текущего размера сети (экспоненциальная модель).

рис 2. Двудольная клика.
· В виду особой практической важности PageRank и ему подобных алгоритмов G. Pandurangan, P. Raghavan, и E. Upfal изучили распределение рейтинга PageRank (PR) в web-графе. Их исследование показало, что распределение PR, также как и число ссылающихся страниц, подчиняется экспоненциальному закону с коэффициентом 2.1, но корреляция между этими параметрами очень невелика, а значит, страница с большим количеством входящих ссылок может получить очень низкий PR. Подобный результат очень обрадовал ИПС, в частности Google, ведущую постоянную борьбу с компаниями-оптимизаторами сайтов (SEO).
· Основываясь на данных о распределении PageRank и числа ссылающихся страниц, G. Pandurangan, P. Raghavan и E.Upfal [13] предложили т.н. PageRank модель, являющуюся обобщением модели развивающейся сети. В ней вводятся 2 параметра  и
и  ,
,  ,
, 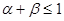 . Конечная вершина для i-й дуги, соединяющая ее с новой добавляемой вершиной, с вероятностью
. Конечная вершина для i-й дуги, соединяющая ее с новой добавляемой вершиной, с вероятностью  будет выбираться с вероятностью, пропорциональной числу входящих в нее дуг (преференциальное добавление); с вероятностью она выбирается с вероятностью пропорциональной ее PageRank; и с вероятностью
будет выбираться с вероятностью, пропорциональной числу входящих в нее дуг (преференциальное добавление); с вероятностью она выбирается с вероятностью пропорциональной ее PageRank; и с вероятностью  случайным образом (единообразное добавление). С помощью компьютерной симуляции авторам удалось показать, что при правильно подобранных коэффициентах генерируемый данной моделью граф обладает свойствами распределения и числа входящих дуг и PageRank.
случайным образом (единообразное добавление). С помощью компьютерной симуляции авторам удалось показать, что при правильно подобранных коэффициентах генерируемый данной моделью граф обладает свойствами распределения и числа входящих дуг и PageRank.
|
|
|
· В 2002г. D.M. Pennock, G.W. Flake и др. [14] установили, что закон распределения числа входящих дуг для таких групп страниц, как домашние сайты студентов университета, или все страницы сайтов новостей, испытывают значительные отклонения от экспоненциального закона в различной для каждой группы степени. В этой же работе, они предложили модель “Растущей сети”, являющуюся комбинацией единообразных и преференциальных добавлений вершин с коэффициентом вероятности . Было установлено, что меняя и тем самым балансируя между единообразным и преференциальным добавлением вершин, можно добиться распределения числа входящих дуг, аналогичного распределению обнаруженному в рассматриваемых группах. Это модель также считается обобщением развивающейся модели.
· S. Dill в своей работе [15] исследовал различные фрактальные свойства web-графа. Граф может быть рассмотрен как производная нескольких независимых стохастических процессов. Изучая различные cohesive группы страниц (напр. страницы, принадлежащие одному сайту, или страницы общей тематики), было обнаружено подобие их структуры структуре всего графа (структура “бабочки”, экспоненциальный закон распределения числа ссылающихся страниц). Центральная часть структуры этих коллекций была названа “Тематически Объединенным Кластером” (Thematically Unified Cluster" (TUC)).

рис 3. Самоподобие web-графа.
· Для реализации фрактальных свойств web-графа, L. Laura, S. Leonardi и др. [16] в 2002г. предложили “Многослойная модель”. Она позволяет одновременное использование 2-х и более моделей, рассмотренных ранее, и подробно освещается в данной работе.
|
|
|
