 |


Арифметическое кодирование
|
|
|
|
Пусть имеется последовательность  . .
| (1.21) |
Относительная частота символов:
 ,
,  ,
,  .
.
При арифметическом кодировании последовательность (1.21) заменяется одним единственным числом. Для получения этого числа разобьем интервал [0,1] на подинтервалы:
| [0; 0,25], (0,25; 0,75], (0,75; 1]. | (1.22) |
Заметим, что длина каждого подинтервала соответствует относительной частоте соответствующего символа. Нетрудно сообразить, что первый подинтервал [0; 0,25] соответствует  ; подинтервал (0,25; 0,75] – символу
; подинтервал (0,25; 0,75] – символу  и (0,75; 1] – символу
и (0,75; 1] – символу  . В последовательности (3.22) первый символ . Ему соответствует интервал [0; 0,25]. Поэтому выбираем этот подинтервал и делим его опять согласно относительным частотам символов:
. В последовательности (3.22) первый символ . Ему соответствует интервал [0; 0,25]. Поэтому выбираем этот подинтервал и делим его опять согласно относительным частотам символов:
| [0; 0,0625), [0,0625; 0,1875), [0,1875; 0,25]. | (1.23) |
Следующий символ – . Ему соответствует интервал (0,0625; 0,1875]. Делим его на подинтервалы:
| [0,0625; 0,09375), [0,09375; 0,15625), [0,15625; 0,1875]. | (1.24) |
Следующий символ – . Выбираем второй подинтервал (0,09375; 0,15625]. Делим его на три подинтервала соответственно частотам символов:
| [0,09375; 0,109375), [0,109375; 0,140625), [0,140625; 0,15625]. | (1.25) |
Наконец, последний символ –  . Ему соответствует третий интервал. Поэтому в качестве окончательного кода для последовательности (1.21) можно указать любое число из интервала [0,140625; 0,15625]. Например, возьмем 0,15. Итак, последовательность (1.21) кодируется числом 0.15.
. Ему соответствует третий интервал. Поэтому в качестве окончательного кода для последовательности (1.21) можно указать любое число из интервала [0,140625; 0,15625]. Например, возьмем 0,15. Итак, последовательность (1.21) кодируется числом 0.15.
Чтобы восстановить исходную последовательность, нужно действовать таким образом. Согласно частотам символов составляем исходное разбиение (1.22). Видим, что наш код 0,15 попадает в первый подинтервал [0; 0,25]. Значит первый символ – . Далее разбиваем интервал [0; 0,25] на три подинтервала (1.23) и смотрим, к какому из них принадлежит наш код 0,15. Теперь этот второй подинтервал, поэтому следующий символ . Далее из представления (1.24) снова выбираем второй подинтервал и символ . Наконец, из (1.25) выбираем символ .
|
|
|
Арифметическое сжатие может давать большие последовательности цифр и поэтому его применение ограничивается небольшими последовательностями символов.
Сжатие графических файлов
Сжатие графической информации основано на частичной потере информации. В самом деле, в изображении соседние пиксели (точки) мало различаются по яркости (светимости) и цвету. Особенностью является то обстоятельство, что глаз человека меньше различает именно светимость двух соседних точек. Поэтому модель данных YCbCr в большей степени ориентирована на сжатие, чем модель RGB. Для получения сжатого изображения применяют ортогональные преобразования данных. Ортогональные преобразования выполняют таким образом, чтобы большая часть данных при преобразовании получила маленькие (близкие к нулю значения) и лишь небольшая часть данных оказалась значимой. Затем выполняется квантование (округление данных) так, что малозначимые данные становятся равными 0. Дадим иллюстрацию сказанному. Пусть исходные данные представлены следующей матрицей:
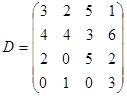 .
.
Возьмем матрицу преобразования:
 . .
| (1.26) |
Сначала найдем по правилам матричной алгебры произведение
 ,
,
Затем
 . .
| (1.27) |
Получим
 .
.
В этой матрице доминирует лишь небольшое число элементов. Можно выполнить квантование, например, следующим образом:
 .
.
Именно эта операция (квантования) и приводит к потере данных, хотя эта потеря мало отражается на исходных данных. В самом деле, легко восстановить из (3.27) матрицу С:
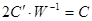 . .
| (1.28) |
и, аналогично,
 . .
| (1.29) |
С помощью (3.28), (3.29) получим восстановленную приближенную матрицу исходных данных:
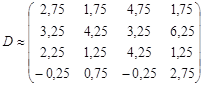 .
.
После квантования получим
|
|
|
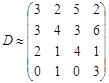 .
.
Эта последняя матрица очень близка к исходной матрице D (!).
Прежде всего, заметим, что матрица преобразования W должна строится специальным образом. Во-первых, она должна быть ортогональной, что означает, что векторное произведение любых ее двух строк или столбцов равно 0 (а это означает, что строки и столбцы матрицы не зависимы и, следовательно, определитель матрицы отличен от 0). Во-вторых, матрица W подбирается так, что сумма элементов только в первой строке и в первом столбце максимальны; в остальных строках и столбцах суммы элементов равны или близки к 0.
Из соображений, близких к рассмотренным, строится матрица дискретного косинусного преобразования (DCT-матрица), используемая в алгоритме JPEG. Матрица двумерного DCT-преобразования определяется из следующей формулы
 . .
| (1.30) |
В (3.30)  – значение пикселя в строке x и столбце y квадратной матрицы пикселей размеров
– значение пикселя в строке x и столбце y квадратной матрицы пикселей размеров 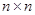 ;
;

Матрица одномерного DCT-преобразования использует расчетную формулу
 . .
| (1.31) |
Заметим, что величины
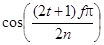
изменяются для  и
и 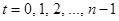 так что в результате из них можно построить следующую матрицу преобразования (для
так что в результате из них можно построить следующую матрицу преобразования (для 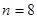 )
)

| 
| 
| 
| 
| 
| 
| 
| 
|

| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |

| 0,981 | 0,831 | 0,556 | 0,195 | -0,195 | -0,556 | -0,831 | -0,981 |

| 0,924 | 0,383 | -0,383 | -0,924 | -0,924 | -0,383 | 0,383 | 0,924 |

| 0,831 | -0,195 | -0,981 | -0,556 | 0,556 | 0,981 | 0,195 | -0,831 |
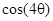
| 0,707 | -0,707 | -0,707 | 0,707 | 0,707 | -0,707 | -0,707 | 0,707 |

| 0,556 | -0,981 | 0,195 | 0,831 | -0,831 | -0,195 | 0,981 | -0,556 |

| 0,383 | -0,924 | 0,924 | -0,383 | -0,383 | 0,924 | -0,924 | 0,383 |

| 0,195 | -0,556 | 0,831 | -0,981 | 0,981 | -0,831 | 0,556 | -0,195 |
Эта матрица является ортогональной и построена по тем же принципам, что и матрица W, которую мы рассмотрели выше. Нам остается коротко охарактеризовать алгоритм сжатия JPEG, основу которого составляет DCT-преобразование.
В JPEG используется цветовая модель YCrCb, где Y передает светимость пикселя. Преобразование DCT выполняется отдельно к светимости Y, и отдельно к матрице, кодирующей хроматические числа Cr и Cb. К светимости Y применяется одномерное DCT преобразование. Для компоненты <Cr, Cb> выполняется разбиение изображения на матрицы пикселей  . К каждой из таких матриц применяется двумерное DCT-преобразование. Таким образом, выполняется сжатие с потерей информации.
. К каждой из таких матриц применяется двумерное DCT-преобразование. Таким образом, выполняется сжатие с потерей информации.
Сокращение JPEG происходит от слов Joint Photographic Expert Group – совместная группа по фотографии. Проект JPEG стал стандартом в 1991г. – принят международной организацией стандартов ISO.
|
|
|
Классификация документов
Методы спецификации и обработки документов в Internet получают широкое применение в связи с созданием новых технологий и расширением возможностей представления семантики текстов, в первую очередь в документах XML.
В настоящем разделе рассматриваются программно-математические аспекты обработки текстов и создания интеллектуальных поисковых систем в Internet.____________________________________
Задача классификации и идентификации документов
Пусть в базе данных имеются спецификации текстов документов I1, I2,...,In, на входе системы имеется спецификация документа Х = (х1, х2,...,хm). Требуется установить, к какому классу документов I1, I2,...,In относится Х.
Задачу будем решать при следующих условиях:
· Параметры х1, х2,...,хm задают частоты встречаемости термов в тексте. Аналогичным образом, спецификации представлены векторами частот встречаемости термов в текстах-шаблонах. Под термом понимается ключевое слово текста.
· Известны весовые оценки значимости термов для соответствующих документов.
В результате будут вычислены некоторые оценки b 1, b 2,..., b n, определяющие систему предпочтений в установлении документа-шаблона, к которому принадлежит текст Х, при этом å b i =1 и если b p > b s, то объективно принадлежность Х к Ip оцениваетсявыше, чем к Is.
Описание проблемы и этапов ее решения
Допустим, что в силу общности или пересечения тем документов может возникнуть n кластеров (доменов, зон) с различной степенью (оценки) принадлежности к ним рассматриваемого документа Х; Пусть P (w i ï х) - условная вероятность того, что наблюдаемый вектор х относится к домену w i. В силу теоремы Байеса получим:
 , (1.32)
, (1.32)
где  - вероятность фактического наблюдения вектора х с данными значениями частот встречаемости ключевых слов (термов);
- вероятность фактического наблюдения вектора х с данными значениями частот встречаемости ключевых слов (термов);
 - априорная вероятность того, что документ относится к домену w i,
- априорная вероятность того, что документ относится к домену w i,
|
|
|
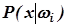 - вероятность того, что домен w i мог привести к появлению вектора х;
- вероятность того, что домен w i мог привести к появлению вектора х;
w i - идентификатор домена.
Рассматриваются следующие домены:
w 0 – ни один из шаблонов-документов не является владельцем Х;
w 1 – 1 -й источник является владельцем Х, остальные – нет;
w m – m -й источник является владельцем Х, остальные – нет;
w m +1 – 1-й и 2-й источники в совокупности могут быть владельцами Х, остальные нет;
w n – все n могут быть в совокупности владельцами Х.
Введем штрафную оценку
 , (1.33)
, (1.33)
где 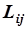 - штраф, который следует заплатить за ошибочную классификацию владельца Ii вместо фактического Ij.
- штраф, который следует заплатить за ошибочную классификацию владельца Ii вместо фактического Ij.
С учетом (1.32) перепишем (1.33) в виде
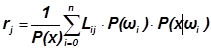
Теперь, приняв Lkk =0 и Lij = Lji =1 (для всех i, j, i ¹ j), получим окончательно
 (1.34)
(1.34)
Формула (1.34) служит основой для принятия решений.
Введя соотношение
 , (1.35)
, (1.35)
можно утверждать, что наименьшему значению b i будет соответствовать документ с наименьшей оценкой возможности быть владельцем Х.
Применение формулы (1.34) потребует упрощающего допущения, а именно - предельные распределения значений частот встречаемости термов в тексте должны подчиняться многомерному нормальному закону.
Априорную вероятность  того, что владельцем документа является шаблон Ii, можно определить на основе теории выбора многокритериальных решений с использованием функции полезности.
того, что владельцем документа является шаблон Ii, можно определить на основе теории выбора многокритериальных решений с использованием функции полезности.
Для оценки вероятности 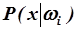 необходимо определить
необходимо определить  , вероятность фактического наблюдения вектора х, значимо не отличающегося от результатов расчета частот встречаемости термов, порождаемых доменом w m,что повлечет за собой необходимость спланировать специальный вычислительный эксперимент с построением информационной сети через проективные геометрии и поля Галуа.
, вероятность фактического наблюдения вектора х, значимо не отличающегося от результатов расчета частот встречаемости термов, порождаемых доменом w m,что повлечет за собой необходимость спланировать специальный вычислительный эксперимент с построением информационной сети через проективные геометрии и поля Галуа.
Таким образом, методика расчетов сводится к определению членов формулы (1.34). Для определения множителей P (w i) используется техника многокритериальной оценки на основе процедуры Саати, где в качестве альтернатив рассматриваются домены w i, а критериями являются факторы, обусловливающие априорные значения P (w i). Для оценки значений P ( x | w i) проводится серия вычислительных экспериментов, целью которых является получение математического ожидания и среднеквадратического отклонения частот встречаемости термов в домене w i.
Последующее изложение раскрывает существо указанной методики и ее теоретико-практическое наполнение.
Оценка 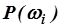 - априорной вероятности того, что владельцем документа является домен w i
- априорной вероятности того, что владельцем документа является домен w i
Значение искомой вероятности можно получить путем математической обработки экспертных оценок специалистов с привлечением теории многокритериальных решений и функции полезности.
|
|
|
Значения dij частных функций полезности, присваиваемые экспертами каждому домену, могут располагаться в диапазоне [0, 1]. Чем dij ближе к единице, тем, по мнению эксперта, вероятнее соответствие факта принадлежности j -го ключевого слова i - му домену.
Для выявления возможного домена - владельца выбраны следующие критерии:
Т1 - степень соответствия входной спецификации тематике i -го шаблона-документа,
Т2 – распространенность тематики;
Т3 – цитируемость документов по тематике за последний месяц;
Т4 – степень общности тематики (широта тематики).
Для получения обобщенной, комплексной оценки вероятности по p критериям одновременно необходимо определить коэффициенты d j, характеризующие значимость, приоритеты (статистические веса) каждого критерия. Для этой цели используется алгоритм Саати, по которому строится матрица приоритетов D:
| Т1 | Т2 | Т3 | Т4 | |
| Т1 | 1 | d12 | d13 | d14 |
| Т2 | d21 | 1 | d22 | d24 |
| Т3 | d31 | d32 | 1 | d34 |
| Т4 | d41 | d42 | d43 | 1 |
Для каждой строки находим
 (1.36)
(1.36)
Откуда
 (1.37)
(1.37)
Найденные значения статистических весов считаются согласованными, если выполняется условие Саати:
 (1.38)
(1.38)
где 
| Размер матрицы | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| x | 0 | 0 | 0,58 | 0,90 | 1,12 | 1,24 | 1,32 | 1,41 | 1,45 | 1,49 |
Обобщенную оценку вероятности владельца документа Ii можно вычислить по формуле:
 (1.39)
(1.39)
где p - количество обобщаемых признаков;
d ij - частные функции полезности i -го объекта по j -му критерию;
m j - статистический вес (важность) j -го критерия (0 £ m j £ 1).
Величины q (...) используются следующим образом. Находим, например, P (w я) - оценку априорной вероятности того, что владельцами являются домены 1, 2, а остальные три источника – 3,4,5,6 – нет:
P (w R) = q (1)* q (2)*(1- q (3))*(1- q (4))*(1- q (5)) *(1- q (6)).
Отметим, что эта и подобные формулы получаются из общей формулы Бернулли для вероятности сложного события.
Определение  - вероятностифактического наблюдения вектора | х |,значимо не отличающегося от результатов расчета частотвстречаемости термов в документах, порождаемых от источника Ii.
- вероятностифактического наблюдения вектора | х |,значимо не отличающегося от результатов расчета частотвстречаемости термов в документах, порождаемых от источника Ii.
Перед тем как приступить к построению информационной сети, нужно обосновать выбор необходимого числа факторов и уровней варьирования каждого фактора. Этапами формирования информационной сети являются составление групп координат вершин связок плоскостей на бесконечности, численно равных количеству факторов и выступающих в качестве генераторов планов эксперимента, а также решение проблемы упаковки ортогональных таблиц путем заполнения их элементами поля Галуа в соответствии с генераторами планов.
При составлении групп координат вершин связок плоскостей на бесконечности, действуют следующие правила:
- ( *) в группу входит столько координат, сколько вершин в фундаментальном симплексе;
- (**) число уровней варьирования каждого фактора обозначается S и называется модулем;
- (***) каждая последующая группа координат получается прибавлением единицы к младшему разряду по модулю;
- (****) первая ненулевая координата не может быть больше единицы.
Необходимое число опытов в узлах информационной сети определяется по формуле
N = Sn, (1.40)
a количество факторов, которое можно описать этим количеством опытов, находится из выражения
F =(S n -1)/(S -1) (1.41)
где S - число уровней варьирования;
n - число вершин фундаментального симплекса.
Следующей операцией формирования информационной сети является заполнение элементами поля Галуа столбцов ортогональной таблицы под координатами вершин фундаментального симплекса (составление линейно независимых векторов).
Правила составления линейно независимых векторов:
- группы координат вершин фундаментального симплекса должны располагаться в первых столбцах ортогональной таблицы;
- в первом столбце элементы поля Галуа, численно равные уровням варьирования факторов, перечисляются по порядку столько раз, сколько уровней варьирования, т.е. число элементов должно быть (0,1,..,S) ´ S;
- во втором столбце каждый элемент, численно равный уровню варьирования, повторяется S раз подряд;
- в третьем столбце смена уровней варьирования происходит через S ´ S повторений и т.д.
Решение проблемы упаковки ортогональной таблицы производится путем умножения и сложения элементов поля Галуа в кольце классов вычетов по модулю S в соответствии с координатами вершин связок плоскостей на бесконечности (генераторов информационной сети).
Определение векторов | mi | оценок достоверности владельца шаблона Ii
Для получения оценок векторов средних значений mi и стандартных отклонений (коэффициентов корреляции) частот встречаемости термов необходимо рассмотреть ряд документов, относящихся к одной тематике, представленной шаблоном w i. Этот этап должен быть проведен заранее при создании системы идентификации.
Оценка  , вероятности того, что владельцем входного документа является шаблон Ii
, вероятности того, что владельцем входного документа является шаблон Ii
Предельные распределения значений частот термов от каждого источника должны подчиняться многомерному нормальному закону:
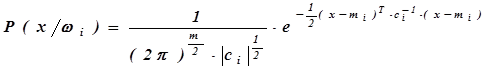 (1.42)
(1.42)
где: mi - вектор математических ожиданий частот встречаемости термов в документа, порождаемых от источника Ii,
m - размерность вектора х
ci - ковариационная матрица векторов частот термов,
ci -1 - обратная матрица ci,
 - определитель матрицы с i
- определитель матрицы с i
Для определения элементов ковариационной матрицы используется соотношение:
 (1.43)
(1.43)
Определение классифицирующего множества документов-шаблонов
С целью формализации процедуры принятия решения о требуемом количестве документов-шаблонов предложено рассматривать некоторую метрику, устанавливающую меру близости двух различных документов-шаблонов.
Расстоянием между двумя документами назовем величину d ( a , b ) ( x , c ):
 (1.44)
(1.44)
Значения евклидова расстояния можно использовать для разбиения множества документовна кластеры (зоны), представляющие некоторые типовые сюжеты.
На основании этих данных строится 0,1 - матрица В = [ bjj ], такая, что bij = 1 в том и только в том случае, когда расстояние dij между документами i и j не превосходит d, и bij = 0 в противном случае. Каждому документу присвоим вес Сi, отражающий его типичность для раскрываемой в нем темы.
Подготовленные таким образом исходные данные позволяют сформулировать и решить следующую важную прикладную задачу.
Во-первых, можно найти минимальное взвешенное покрытие p min, т.е. такое множество строк из ½ В ½, которые имеют минимальную стоимость и, по крайней мере, любая одна строка из p min содержит на пересечении с каждым из столбцов единицу. Эта задача позволяет определить необходимое число шаблонов документов в классифицирующем множестве.
Таким образом, процедура определения необходимого числа документов в классифицирующем сводится к решению хорошо известной NP- полной задаче о минимальном взвешенном покрытии 0,1-матрицы множеством строк (ЗМВП).
Литература
1. Успенский И. Интернет как инструмент маркетинга. BHV, С-т Петербург, 256с., 2002..
2. Меградж З. Разработка приложений для электронной коммерции на ORACLE и JAVA. Вильямс, 2000, 328с.
3. Пирогов В.П. MS SQL Server 2000. Управление и программирование. – СПб. БХВ.-2005,-600с.
4. Холл М., Браун Л. Программирование для WEB. Вильямс, 2002, - 1280с.
|
|
|
