 |


Тема 3. Реляционная модель БД
|
|
|
|
Основы реляционной модели данных были впервые изложены в статье Е.Кодда в 1970 г. Эта работа послужила стимулом для большого количества статей и книг, в которых реляционная модель получила дальнейшее развитие. Наиболее распространенная трактовка реляционной модели данных принадлежит К.Дейту, который представил реляционную модель, состоящей из трех частей: структурной, целостной и манипуляционной.
Структурная часть описывает, какие объекты рассматриваются реляционной моделью. Постулируется, что единственной структурой данных, используемой в реляционной модели, являются нормализованные n-арные отношения.
Целостная часть описывает ограничения специального вида, которые должны выполняться для любых отношений в любых реляционных базах данных. Это целостность сущностей и целостность связей (внешних ключей). Целостность обычно выражается в виде ограничений или правил сохранения непротиворечивости данных, которые не должны нарушаться в базе.
Манипуляционная часть описывает два эквивалентных способа манипулирования реляционными данными - реляционную алгебру и реляционное исчисление.
Структура реляционной базы данных
Итак, реляционная база данных - база данных, в которой все данные представлены в виде двумерных таблиц или отношений.
Таблица применяется для описания некой сущности, такой как персона, место, событие и тому подобное. Таблица Таблица представляет собой совокупность столбцов и строк. В каждом столбце собраны данные одного типа. Строка таблицы объединяет данные всех столбцов о предмете таблицы. Строке таблицы соответствует запись БД, а информация внутри записи на пересечении с одним столбцом называется полем.
|
|
|
К примеру, автоматизируя архив данных о студентах, начнем с нижеследующей таблицы, где столбцам поставлены в соответствия поля, а строкам — записи:
Таблица 1.Фрагмент списка из студенческого архива
| Поле ФИО | Поле Дата_рождения | Поле Группа | Поле Специальность | |
| ¯ | ¯ | ¯ | ¯ | |
| ФИО | Дата_рождения | Группа | Специальность | |
| Иванов И.И. | 01.09.85 | ГМУ | запись 1 | |
| Петров П.П. | 09.12.84 | УП | запись 2 | |
| Сидоров С.С. | 07.10.85 | ГМУ | запись 3 | |
| Соловьев С.С. | 07.10.85 | ГМУ | запись 4 | |
| Агапов Р.П. | 23.07.90 | ГМУ | запись 5 |
Записи таблицы соответствует термин кортеж, пришедший из теории множеств. Столбцы (поля записи) имеют имена. Имена столбцов — это атрибуты отношения. Список атрибутов отношения называют схемой отношения.
Число атрибутов отношения (столбцов таблицы) называют его степенью, а максимально возможное число кортежей — мощностью. Степень отношения уже введенной в эксплуатацию БД меняется редко (это зависит от конкретной используемой СУБД), другими словами, добавлять и удалять поля в существующую таблицу не всегда возможно. Количество записей меняется постоянно, поскольку требуется добавление в таблицу новых или удаление уже устаревших.
Замечание
Понятия «отношение» и «реляционная таблица» не совсем совпадают, подобно различию понятий «информация» и «данные», которыми эта информация представлена [3]. Пояснение дает следующий факт: мощность отношения определяется количеством встречаемых проявлений сущности, иначе говоря, неисчислимостью множества кортежей, тогда как количество сток в реляционной таблице каждый раз конечно. Но в практике работы с базами данных и в литературе по базам данных эти два понятия обычно смешиваются, и реляционные таблицы также называют просто «отношениями». С одной стороны, указанные различия часто находятся за рамками рассмотрения, с другой — всегда можно утверждать, что любой реляционной таблицей задано определенное отношение (пусть даже и не совпадающее с исходным). Из контекста почти всегда становится ясным, о чем идет речь.
|
|
|
Очевидно, что данной таблицы (см. таб.1) недостаточно для автоматизации студенческого архива. Возможно, потребуется еще несколько таблиц с различным количеством полей, но и это еще не все, могут потребоваться связи между таблицами.
Отношения реляционной базы данных делятся на два типа: объектные и связные. Объектное отношение хранит данные об экземплярах объекта предметной области. Например, отношение Студент хранит данные о различных студентах. Каждый студент является экземпляром объекта Студент и должен быть однозначно идентифицируем, поэтому объектное отношение должно обязательно иметь первичный ключ.
Связное отношение содержит атрибуты, характеризующие связь между объектами. Оно обязательно содержит первичные ключи объектных отношений, участвующих в связи, а также атрибуты, которые функционально зависят от этой связи. Связное отношение не обязательно содержит первичный ключ. Оно служит для того, чтобы можно было, выбрав информацию из одного отношения, использовать ее для поиска соответствующей информации в другом отношении.
Совокупность таблиц должна удовлетворять определенным ограничивающим условиям. Одним из главных ограничений является запрет на присутствие в таблице двух одинаковых строк, а точнее – строк, имеющих одинаковые первичные ключи (см. ниже).
Все названные понятия – таблицы (отношения) с их именами, поименованные столбцы (атрибуты), связи входят в понятие структуры БД. Также в структуру БД входит описание используемых типов данных.
Типы данных
Любые данные, используемые в программировании, соответствуют определенным типам. Обычно в программировании. рассматриваются типы данных трех групп: простые, структурированные, ссылочные.
Реляционная модель требует, чтобы типы используемых данных были простыми.
Простые, или атомарные, типы данных не обладают внутренней структурой. Данные такого типа называют скалярами. К простым типам данных относятся следующие типы:
· Логический
· Строковый
· Численный
|
|
|
Различные языки программирования могут расширять и уточнять этот список, добавляя такие типы как:
· Целый
· Вещественный
· Дата
· Время
· Денежный
· Перечислимый
· Интервальный
· И т. д.…
Пример. Личные данные в таблице СТУДЕНТ обычно представляются набором атрибутов, включающих, в частности, такие три как ФАМИЛИЯ, ИМЯ, ОТЧЕСТВО, а не единый ФИО. К такому решению разработчики приходят, принимая во внимание возможные запросы к БД, например, найти всех Татьян (к Татьяниному дню). Кроме того, у студента может измениться фамилия или отчество.
Конечно, понятие атомарности довольно относительно. Так, строковый тип данных можно рассматривать как одномерный массив символов, а целый тип данных - как набор битов. Важно лишь то, что при переходе на такой низкий уровень теряется семантика (смысл) данных. Если строку, выражающую, например, фамилию студента, разложить в массив символов, то при этом теряется смысл такой строки как единого целого. Работая с простыми типами данных, например с числовыми, мы манипулируем ими как неделимыми целыми объектами.
Требование использования для реляционной модели данных простого типа, чтобы тип данных был, нужно понимать так, что в реляционных операциях не должна учитываться внутренняя структура данных. Конечно, должны быть описаны действия, которые можно производить с данными как с единым целым, например, данные числового типа можно складывать, для строк возможна операция конкатенации и т.д.
Замечание
С этой точки зрения, если рассматривать массив, например, как единое целое и не использовать поэлементных операций, то массив можно считать простым типом данных. Более того, можно создать свой, сколь угодно сложных тип данных, описать возможные действия с этим типом данных, и, если в операциях не требуется знание внутренней структуры данных, то такой тип данных также будет простым с точки зрения реляционной теории. Тогда, если в действиях с этим типом использовать только описанные операции, то внутренняя структура не играет роли, и тип данных извне выглядит как атомарный.
|
|
|
Именно так в некоторых пост-реляционных (объектно-реляционных) СУБД реализована работа со сколь угодно сложными типами данных, создаваемых пользователями.
В реляционной модели данных с понятием тип данных тесно связано понятие домена, которое можно считать уточнением типа данных.
Домен– это семантическое понятие. Домен можно рассматривать как подмножество значений некоторого типа данных имеющих определенный смысл. Домен характеризуется следующими свойствами:
· Домен имеет уникальное имя (в пределах базы данных)
· Домен определен на некотором простом типе данных или на другом домене
· Домен может иметь некоторое логическое условие, позволяющее описать подмножество данных, допустимых для данного домена
· Домен несет определенную смысловую нагрузку
Пример 1. Поле ИМЯ таблицы СТУДЕНТ (атрибут ИМЯ отношения СТУДЕНТ) – простейший пример домена.
Пример 2. Домен 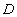 , имеющий смысл "возраст сотрудника" можно описать как следующее подмножество множества натуральных чисел:
, имеющий смысл "возраст сотрудника" можно описать как следующее подмножество множества натуральных чисел:

Если тип данных можно считать множеством всех возможных значений данного типа, то домен напоминает подмножество в этом множестве.
Отличие домена от понятия подмножества состоит именно в том, что домен отражает семантику (смысл), определенную предметной областью. Может быть несколько доменов, совпадающих как подмножества, но несущие различный смысл.
Пример. Домены "Вес детали" и "Количество деталей" можно одинаково описать как множество неотрицательных целых чисел, но смысл этих доменов будет различным, следовательно, это различные домены, и сравнение значений из них доменов некорректно, с логической точки зрения. Таким образом, синтаксически правильный запрос "выдать список всех деталей, у которых вес детали больше имеющегося количества" не соответствует смыслу понятий "количество" и "вес". Вероятно, в БД найдутся такие записи и СУБД даст ответ, но, вероятно, он будет бессмысленным.
Замечания
1 Понятие домена помогает правильно моделировать предметную область.
2 Не все домены обладают логическим условием, ограничивающим возможные значения домена. В таком случае множество возможных значений домена совпадает с множеством возможных значений типа данных.
Пример. Домен "Фамилия сотрудника" может содержать любую последовательность символов, кроме цифр, служебных символов, не должна начинаться с мягкого знака. Но ограничения на строку подобную «Йййййзззззвр» задать невозможно. Трудности такого рода возникают потому, что смысл реальных явлений далеко не всегда можно формально описать. Единственный выход из подобной ситуации - положиться на разум сотрудника, вводящего фамилии в БД.
|
|
|
