 |


Часть 2 Фундаментальные алгоритмы 4 глава
|
|
|
|
Алгоритм 6.15 Алгоритм поиска в глубину Авербаха.
Передачу сообщения < vis > соседу, которому процесс передает маркер, можно опустить. Это усовершенствование (не выполняемое в Алгоритме 6.15) сберегает по два сообщения для каждого ребра дерева и, следовательно, уменьшает сложность сообщений на 2N-2 сообщения.
Решение Сайдона. Алгоритм Сайдона [Cidon; Cid88] улучшает временную сложность алгоритма Авербаха, не посылая сообщения < ack >. В модификации Сайдона маркер передается немедленно, т.е. без задержки на 2 единицы времени, внесенной в алгоритм Авербаха ожиданием подтверждения. Этот же алгоритм был предложен Лакшмананом и др. [Lakshmanan; LMT87]. В алгоритме Сайдона может возникнуть следующая ситуация. Процесс p получил маркер и послал сообщение < vis > своему соседу r. Маркер позже попадает в r, но в момент, когда r получает маркер, сообщение < vis > процесса p еще не достигло r. В этом случае r может передать маркер p, фактически посылая его через листовое ребро. (Заметим, что сообщения < ack > в алгоритме Авербаха предотвращают возникновение такой ситуации.)
Чтобы обойти эту ситуацию процесс p запоминает (в переменной mrsp), какому соседу он переслал маркер в последний раз. Когда маркер проходит только по ребрам дерева, p получает его в следующий раз от того же соседа mrsp. В ситуации, описанной выше, p получает сообщение < tok > от другого соседа, а именно, от r; в этом случае маркер игнорируется, но p помечает ребро rp, как пройденное, как если бы от r было получено сообщение < vis >. Процесс r получает сообщение < vis > от p после пересылки маркера p, т.е. r получает сообщение < vis > от соседа mrsr. В этом случае r действует так, как если бы он еще не послал маркер p; r выбирает следующего соседа и передает маркер; см. Алгоритм 6.16/6.17.
|
|
|
Теорема 6.35 Алгоритм Сайдона (Алгоритм 6.16/6.17) вычисляет DFS- дерево за 2N-2 единиц времени, используя 4|E| сообщений.
Доказательство. Маршрут маркера подобен маршруту в Алгоритме 6.14. Прохождение по листовым ребрам либо пропускается (как в Алгоритме 6.15), либо в ответ на маркер через листовое ребро посылается сообщение < vis >. В последнем случае, процесс, получая сообщение < vis >, продолжает передавать маркер, как если бы маркер был возвращен через листовое ребро немедленно.
Время между двумя успешными передачами маркера по дереву ограничено одной единицей времени. Если маркер послали по ребру дерева процессу p в момент времени t, то в момент t все сообщения < vis > ранее посещенных соседей q процесса p были посланы, и, следовательно, эти сообщения прибудут не позднее момента времени t+1. Итак, хотя p мог несколько раз послать маркер по листовым ребрам до t+1, не позднее t+1 p восстановился после всех этих ошибок и передал маркер по ребру, принадлежащему дереву. Т.к. должны быть пройдены 2N-2 ребра дерева, алгоритм завершается за 2N-2 единиц времени.
Через каждый канал передается не более двух сообщений < vis > и двух < tok >, откуда граница сложности сообщений равна 4|E|.
var usedp[q]: boolean init false для всех q Î Neighp;
fatherp : process init udef;
mrsp : process init udef;
Для инициатора (выполняется один раз):
begin fatherp:= p; выбор q Î Neighp;
forall r Î Neighp do send < vis > to r;
usedp[q]:= true; mrsp:= q; send < tok > to q;
end
Для каждого процесса при получении < vis > от q0:
begin usedp[q0]:= true;
if q0 = mrsp then (* интерпретировать, как < tok > *)
передать сообщение < tok > как при получении < tok >
end
Алгоритм 6.16 Алгоритм поиска в глубину Сайдона (Часть 1).
Для каждого процесса при получении < tok > от q0:
|
|
|
begin if mrsp ¹ udef and mrsp ¹ q0
(* это листовое ребро, интерпретируем как сообщение < vis >*)
then usedp[q0]:= true
else (* действовать, как в предыдущем алгоритме *)
begin if fatherp = udef then
begin fatherp := q0 ;
forall r Î Neighp\ {fatherp}
do send < vis > to r;
end;
if p - инициатор and "q Î Neighp: usedp[q]
then decide
else if $q Î Neighp: (q ¹ fatherp & Øusedp[q])
then begin if fatherp ¹ q0 & Øusedp[q0]
then q:= q0
else выбор q Î Neighp\ {fatherp}
с Øusedp[q];
usedp[q]:= true; mrsp:= q;
send < tok > to q
end
else begin usedp[fatherp]:= true;
send < tok > to fatherp
end
end
end
Алгоритм 6.17 Алгоритм поиска в глубину Сайдона (Часть 2).
Во многих случаях этот алгоритм будет пересылать меньше сообщений, чем алгоритм Авербаха. Оценка количества сообщений в алгоритме Сайдона предполагает наихудший случай, а именно, когда маркер пересылается через каждое листовое ребро в обоих направлениях. Можно ожидать, что сообщения < vis > помогут избежать многих нежелательных пересылок, тогда через каждый канал будет передано только два или три сообщения.
Сайдон замечает, что хотя алгоритм может передать маркер в уже посещенную вершину, он обладает лучшей временной сложностью (и сложностью сообщений), чем Алгоритм 6.15, который предотвращает такие нежелательные передачи. Это означает, что на восстановление после ненужных действий может быть затрачено меньше времени и сообщений, чем на их предотвращение. Сайдон оставляет открытым вопрос о том, существует ли DFS-алгоритм, который достигает сложности сообщений классического алгоритма, т.е. 2|E|, и который затрачивает O(N) единиц времени.
|
|
|
6.4.3 Поиск в глубину со знанием соседей
Если процессам известны идентификаторы их соседей, проход листовых ребер можно предотвратить, включив в маркер список посещенных процессов. Процесс p, получая маркер с включенным в него списком L, не передает маркер процессам из L. Переменная usedp[q] не нужна, т.к. если p ранее передал маркер q, то q Î L; см. Алгоритм 6.18.
Теорема 6.36 DFS- алгоритм со знанием соседей является алгоритмом обхода и вычисляет дерево поиска в глубину, используя 2N-2 сообщений за 2N-2 единиц времени.
У этого алгоритма высокая битовая сложность; если w - количество бит, необходимых для представления одного идентификатора, список L может занять до Nw бит; см. Упражнение 6.14.
var fatherp : process init udef;
Для инициатора (выполняется один раз):
begin fatherp:= p; выбор q Î Neighp;
send < tlist, {p}> to q
end
Для каждого процесса при получении < tlist, L> от q0:
begin if fatherp = udef then fatherp := q0 ;
if $q Î Neighp \ L
then begin выбор q Î Neighp \ L;
send < tlist, LÈ{p} > to q
end
else if p - инициатор
then decide
else send < tlist, LÈ{p} > to fatherp
end
Алгоритм 6.18 Алгоритм поиска в глубину со знанием соседей.
6.5 Остальные вопросы
6.5.1 Обзор волновых алгоритмов
В Таблице 6.19 дан список волновых алгоритмов, рассмотренных в этой главе. В столбце «Номер» дана нумерация алгоритмов в главе; в столбце «C/D» отмечено, является ли алгоритм централизованным (C) или децентрализованным (D); столбец «T» определяет, является ли алгоритм алгоритмом обхода; в столбце «Сообщения» дана сложность сообщений; в столбце «Время» дана временная сложность. В этих столбцах N - количество процессов, |E| - количество каналов, D - диаметр сети (в переходах).
|
|
|
| Алгоритм | Номер | Топология | C/D | T | Сообщения | Время |
| Раздел 6.2: Общие алгоритмы | ||||||
| Кольцевой | 6.2 | кольцо | C | да | N | N |
| Древовидный | 6.3 | дерево | D | нет | N | O(D) |
| Эхо-алгоритм | 6.5 | произвольная | C | нет | 2|E| | O(N) |
| Алгоритм опроса | 6.6 | клика | C | нет | 2N-2 | 2 |
| Фазовый | 6.7 | произвольная | D | нет | 2D|E| | 2D |
| Фазовый на кликах | 6.8 | клика | D | нет | N(N-1) | 2 |
| Финна | 6.9 | произвольная | D | нет | £4N|E| | O(D) |
| Раздел 6.3: Алгоритмы обхода | ||||||
| Последовательный опрос | 6.10 | клика | C | да | 2N-2 | 2N-2 |
| Для торов | 6.11 | тор | C | да | N | N |
| Для гиперкубов | 6.12 | гиперкуб | C | да | N | N |
| Тарри | 6.13 | произвольная | C | да | 2|E| | 2|E| |
| Раздел 6.4: Алгоритмы поиска в глубину | ||||||
| Классический | 6.14 | произвольная | C | да | 2|E| | 2|E| |
| Авербаха | 6.15 | произвольная | C | нет | 4|E| | 4N-2 |
| Сайдона | 6.16/6.17 | произвольная | C | нет | 4|E| | 2N-2 |
| Со знанием соседей | 6.18 | произвольная | C | да | 2N-2 | 2N-2 |
Замечание: фазовый алгоритм (6.7) и алгоритм Финна (6.9) подходят для ориентированных сетей.
Таблица 6.19 Волновые алгоритмы этой главы.
Сложность распространения волн в сетях большинства топологий значительно зависит от того, централизованный алгоритм или нет. В Таблице 6.20 приведена сложность сообщений централизованных и децентрализованных волновых алгоритмов для колец, произвольных сетей и деревьев. Таким же образом можно проанализировать зависимость сложности от других параметров, таких как знание соседей или чувство направления (Раздел B.3).
| Топология | C/D | Сложность | Ссылка |
| Кольцо | C | N | Алгоритм 6.2 |
| D | O(N logN) | Алгоритм 7.7 | |
| Произвольная | C | 2|E| | Алгоритм 6.5 |
| D | O(N logN + |E|) | Раздел 7.3 | |
| Дерево | C | 2(N-1) | Алгоритм 6.5 |
| D | O(N) | Алгоритм 6.3 |
Таблица 6.20 Влияние централизации на сложность сообщений.
6.5.2 Вычисление сумм
В Подразделе 6.1.5 было показано, что за одну волну можно вычислить инфимум по входам всех процессов. Вычисление инфимума может быть использовано для вычисления коммутативного, ассоциативного и идемпотентного оператора, обобщенного на входы, такого как минимум, максимум, и др. (см. Заключение 6.14). Большое количество функций не вычислимо таким образом, среди них - сумма по всем входам, т.к. оператор суммирования не идемпотентен. Суммирование входов может быть использовано для подсчета процессов с определенным свойством (путем присваивания входу 1, если процесс обладает свойством, и 0 в противном случае), и результаты этого подраздела могут быть распространены на другие операторы, являющиеся коммутативными и ассоциативными, такие как произведение целых чисел или объединение мультимножеств.
|
|
|
Оказывается, не существует общего метода вычисления сумм с использованием волнового алгоритма, но в некоторых случаях вычисление суммы возможно. Например, в случае алгоритма обхода, или когда процессы имеют идентификаторы, или когда алгоритм порождает остовное дерево, которое может быть использовано для вычисления.
Невозможность существования общего метода. Невозможно дать общий метод вычисления сумм с использованием произвольного волнового алгоритма, подобного методу, использованному в Теореме 6.12 для вычисления инфимумов. Это может быть показано следующим образом. Существует волновой алгоритм для класса сетей, включающего все неориентированные анонимные (anonymous) сети диаметра два, а именно, фазовый алгоритм (с параметром D=2). Не существует алгоритма, который может вычислить сумму по всем входам, и который является правильным для всех неориентированных анонимных (anonymous) сетей диаметра два. Этот класс сетей включает две сети, изображенные на Рис.6.21. Если предположить, что каждый процесс имеет вход 1, ответ будет 6 для левой сети и 8 - для правой. Воспользовавшись технологией, представленной в Главе 9, можно показать, что любой алгоритм даст для обеих сетей один и тот же результат, следовательно, будет работать неправильно. Детальное доказательство оставлено читателю в Упражнении 9.7.
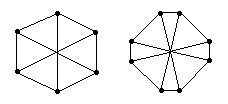
Рис.6.21 Две сети диаметра два и степени три.
Вычисление сумм с помощью алгоритма обхода. Если A - алгоритм обхода, сумма по всем входам может быть вычислена следующим образом. Процесс p содержит переменную jp, инициализированную значением входа p. Маркер содержит дополнительное поле s. Всякий раз, когда p передает маркер, p выполняет следующее:
s:= s + jp; jp:= 0
и затем можно показать, что в любое время для каждого ранее пройденного процесса p jp = 0 и s равно сумме входов всех пройденных процессов. Следовательно, когда алгоритм завершается, s равно сумме по всем входам.
Вычисление суммы с использованием остовного дерева. Некоторые волновые алгоритмы предоставляют для каждого события принятия решения dp в процессе p остовное дерево с корнем в p, по которому сообщения передаются по направлению к p. Фактически, каждое вычисление любого волнового алгоритма содержит такие остовные деревья. Однако, может возникнуть ситуация, когда процесс q посылает несколько сообщений и не знает, какие из его исходящих ребер принадлежат к такому дереву. Если процессы знают, какое исходящее ребро является их родителем в таком дереве, дерево можно использовать для вычисления сумм. Каждый процесс посылает своему родителю в дереве сумму всех входов его поддерева.
Этот принцип может быть применен для древовидного алгоритма, эхо-алгоритма и фазового алгоритма для клик. Древовидный алгоритм легко может быть изменен так, чтобы включать сумму входов Tpq в сообщение, посылаемое от p к q. Процесс, который принимает решение, вычисляет окончательный результат, складывая величины из двух сообщений, которые встречаются на одном ребре. Фазовый алгоритм изменяется так, чтобы в каждом сообщении от q к p пересылался вход q. Процесс p складывает все полученные величины и свой собственный вход, и результат является правильным ответом, когда p принимает решение. В эхо-алгоритме входы могут суммироваться с использованием остовного дерева T, построенного явным образом во время вычисления; см. Упражнение 6.15.
Вычисление суммы с использованием идентификации. Предположим, что каждый процесс имеет уникальный идентификатор. Сумма по всем входам может быть вычислена следующим образом. Каждый процесс помечает свой вход идентификатором, формируя пару (p, jp); заметим, что никакие два процесса не формируют одинаковые пары. Алгоритм гарантирует, что, когда процесс принимает решение, он знает каждый отдельный вход; S = {(p, jp): p Î P} - объединение по всем p множеств Sp = {(p, jp)}, которое может быть вычислено за одну волну. Требуемый результат вычисляется с помощью локальных операций на этом множестве.
Это решение требует доступности уникальных идентификаторов для каждого процесса, что значительно увеличивает битовую сложность. Каждое сообщение волнового алгоритма включает в себя подмножество S, которое занимает N*w бит, если для представления идентификатора и входа требуется w бит; см. Упражнение 6.16.
6.5.3 Альтернативные определения временной сложности
Временную сложность распределенного алгоритма можно определить несколькими способами. В этой книге при рассмотрении временной сложности всегда имеется в виду Определение 6.31, но здесь обсуждаются другие возможные определения.
Определение, основанное на более строгих временных предположениях. Время, потребляемое распределенными вычислениями, можно оценить, используя более строгие временные предположения в системе.
Определение 6.37 Единичная сложность алгоритма (one-time complexity) - это максимальное время вычисления алгоритма при следующих предположениях.
O1. Процесс может выполнить любое конечное количество событий за нулевое время.
O2. Промежуток времени между отправлением и получением сообщения - ровно одна единица времени.
Сравним это определение с Определением 6.31 и заметим, что предположение O1 совпадает с T1. Т.к. время передачи сообщения, принятое в T2, меньше или равно времени, принятому в O2, можно подумать, что единичнаясложность всегда больше или равна временной сложности. Далее можно подумать, что каждое вычисление при предположении T2 выполняется не дольше, чем при O2, и, следовательно, вычисление с максимальным временем также займет при T2 не больше времени, чем при O2. Упущение этого аргумента в том, что отклонения во времени передачи сообщения, допустимые при T2, порождают большой класс возможных вычислений, включая вычисления с плохим временем. Это иллюстрируется ниже для эхо-алгоритма.
Фактически, верно обратное: временная сложность алгоритма больше или равна единичнойсложности этого алгоритма. Любое вычисление, допустимое при предположениях O1 и O2, также допустимо при T1 и T2 и занимает при этом такое же количество времени. Следовательно, наихудшее поведение алгоритма при O1 и O2 включено в Определение 6.31 и является нижней границей временной сложности.
Теорема 6.38 Единичная сложность эхо-алгоритма равна O(D). Временная сложность эхо-алгоритма равна Q(N), даже в сетях с диаметром 1.
Доказательство. Для анализа единичной сложности сделаем предположения O1 и O2. Процесс на расстоянии d переходов от инициатора получает первое сообщение < tok > ровно через d единиц времени после начала вычисления и имеет глубину d в возникающем в результате дереве T. (Это можно доказать индукцией по d.) Пусть DT - глубина T; тогда DT £ D и процесс глубины d в T посылает сообщение < tok > своему родителю не позднее (2DT + 1) - d единиц времени после начала вычисления. (Это можно показать обратной индукцией по d.) Отсюда следует, что инициатор принимает решение не позднее 2DT + 1 единиц времени после начала вычисления.
Для анализа временной сложности сделаем предположения T1 и T2. Процесс на расстоянии d переходов от инициатора получает первое сообщение < tok > не позднее d единиц времени после начала вычисления. (Это можно доказать индукцией по d.) Предположим, что остовное дерево построено через F единиц времени после начала вычисления, тогда F £ D. В этом случае глубина остовного дерева DT необязательно ограничена диаметром (как будет показано в вычислении ниже), но т.к. всего N процессов, глубина ограничена N-1. Процесс глубины d в T посылает сообщение < tok > своему родителю не позднее (F+1)+(DT-d) единиц времени после начала вычисления. (Это можно показать обратной индукцией по d.) Отсюда следует, что инициатор принимает решение не позднее (F+1)+DT единиц времени после начала вычисления, т.е. O(N).
Чтобы показать, что W ( N) - нижняя граница временной сложности, построим на клике из N процессов вычисление, которое затрачивает время N. Зафиксируем в клике остовное дерево глубины N-1 (на самом деле, линейную цепочку вершин). Предположим, что все сообщения < tok >, посланные вниз по ребрам дерева, будут получены спустя 1/N единиц времени после их отправления, а сообщения < tok > через листовые ребра будут получены спустя одну единицу времени. Эти задержки допустимы, согласно предположению T2, и в этом вычислении дерево полностью формируется в течение одной единицы времени, но имеет глубину N-1. Допустим теперь, что все сообщения, посылаемые вверх по ребрам дерева также испытывают задержку в одну единицу времени; в этом случае решение принимается ровно через N единиц времени с начала вычисления.
Можно спорить о том, какое из двух определений предпочтительнее при обсуждении сложности распределенного алгоритма. Недостаток единичной сложности в том, что некоторые вычисления не учитываются, хотя они и допускаются алгоритмом. Среди игнорируемых вычислений могут быть такие, которые потребляют очень много времени. Предположения в Определении 6.31 не исключают ни одного вычисления; определение только устанавливает меру времени для каждого вычисления. Недостаток временной сложности в том, что результат определен вычислениями (как в доказательстве Теоремы 6.38), что хотя и возможно, но считается крайне маловероятным. Действительно, в этом вычислении одно сообщение «обгоняется» цепочкой из N-1 последовательно передаваемого сообщения.
В качестве компромисса между двумя определениями можно рассмотреть a- временную сложность, которая определяется согласно предположению, что задержка каждого сообщения - величина между a и 1 (a - константа £1). К сожалению, этот компромисс обладает недостатками обоих определений. Читатель может попытаться показать, что a-временная сложность эхо-алгоритма равна O(min(N,D/a)).
Наиболее точная оценка временной сложности получается, когда можно задать распределение вероятностей задержек сообщений, откуда может быть вычислено ожидаемое время вычисления алгоритма. У этого варианта есть два основных недостатка. Во-первых, анализ алгоритма слишком зависит от системы, т.к. в каждой распределенной системе распределение задержек сообщений различно. Во-вторых, в большинстве случаев анализ слишком сложен для выполнения.
Определение, основанное на цепочках сообщений. Затраты времени на распределенное вычисление могут быть определены с использованием структурных свойств вычисления, а не идеализированных временных предположений. Пусть C - вычисление.
Определение 6.39 Цепочка сообщений в C - это последовательность сообщений m1, m2,..., mk такая, что для любого i (0 £ i £ k) получение mi каузально предшествует отправлению mi+1.
Цепочечная сложность распределенного алгоритма (chain-time complexity) - это длина самой длинной цепочки сообщений во всех вычислениях алгоритма.
Это определение, как и Определение 6.31,рассматривает всевозможные выполнения алгоритма для определения его временной сложности, но определяет другую меру сложности для вычислений. Рассмотрим ситуацию (происходящую в вычислении, определенном в доказательстве теоремы 6.38), когда одно сообщение «обгоняется» цепочкой из k сообщений. Временная сложность этого (под)вычисления равна 1, в то время, как цепочечная сложность того же самого (под)вычисления равна k. В системах, где гарантируется существование верхней границы задержек сообщений (как предполагается в определении временной сложности), временная сложность является правильным выбором. В системах, где большинство сообщений доставляется со «средней» задержкой, но небольшая часть сообщений может испытывать гораздо большую задержку, лучше выбрать цепочечную сложность.
Упражнения к Главе 6
Раздел 6.1
Упражнение 6.1 Приведите пример PIF- алгоритма для систем с синхронной передачей сообщений, который не позволяет вычислять функцию инфимума (см. Теоремы 6.7 и 6.12). Пример может подходить только для конкретной топологии.
Упражнение 6.2 В частичном порядке (X, £) элемент b называется дном, если для всех c Î X, b £ c.
В доказательстве Теоремы 6.11 используется то, что частичный порядок (X,£) не содержит дна. Где именно?
Можете ли вы привести алгоритм, который вычисляет функцию инфимума в частичном порядке с дном и не является волновым алгоритмом?
Упражнение 6.3 Приведите два частичных порядка на натуральных числах, для которых функция инфимума является (1) наибольшим общим делителем, и (2) наименьшим общим кратным (the least common ancestor).
Приведите частичные порядки на наборах подмножеств области U, для которых функция инфимума является (1) пересечением множеств, и (2) объединением множеств.
Упражнение 6.4 Докажите теорему об инфимуме (Теорему 6.13).
|
|
|
