 |


Краткое обозрение технологий SIMD
|
|
|
|
Введение
В этой работе проводиться обзор основных моментов необходимых для оптимизации программного обеспечения для текущего поколения процессоров основанных на технологии IA-32, таких как Intel Pentium 4, Intel Xeon и Intel Pentium M. Работа дает базу для понимания правильного подхода к кодированию для технологии IA-32.
Ключевые моменты, повышающие производительность процессоров текущего поколения на базе IA-32:
· Расширение инструкций SIMD поддерживающих технологию MMX, потоковые расширения инструкций SIMD (SSE), потоковые расширения инструкций SIMD второй редакции (SSE2) и потоковые расширения инструкций SIMD третьей редакции (SSE3)
· Микроархитектуры позволяющие выполнение большего количества инструкций на высоких тактовых частотах, иерархия высокоскоростных КЭШей и возможность получать данные по высокоскоростной системной шине
· Поддержка технологии Hyper Threading
Процессоры Intel Pentium 4 и Intel Xeon построены на микроархитектуре NetBurst. Микроархитектура процессора Intel Pentium M основывается на балансе производительности и низкого энергопотребления.
Технология SIMD
Один из путей к увеличению производительности процессора – это использование технологии вычислений основанной на том, что одна команда оперирует многими данными (single-instruction, multiple data (SIMD)).
Вычисления с помощью SIMD (рисунок 1) представлены в архитектуре IA-32 технологией MMX.Технология MMX позволяет вычислениям SIMD производиться над упакованными целыми числами в виде байтов, слов и двойных слов. Эти целые содержаться в наборе из восьми 64-битных регистрах называемых MMX регистрами (рисунок 2).
В процессоре Intel Pentium III технология SIMD была расширена с помощью потоковых расширений SIMD (SSE). SSE позволяет производить вычисления SIMD над операндами, содержащими четыре упакованных элемента с плавающей точкой одинарной точности. Эти операнды могут храниться как в памяти, так и в одном из 128-битных регистров называемых XMM регистрами (рисунок 2). SSE также расширяет вычислительные способности SIMD, путем добавления дополнительных 64-битных MMX команд.
|
|
|
Рисунок 1 показывает типичную схему вычислений SIMD. Два блока по четыре упакованных элемента данных (X1, X2, X3, X4 и Y1, Y2, Y3,Y4), обрабатываемых параллельно с помощью одной операцией над каждой парой элементов данных (X1 и Y1, X2 и Y2, X3 и Y3 и X4 и Y4). Результаты четырех параллельных вычислений сортируются в набор из четырех элементов данных.
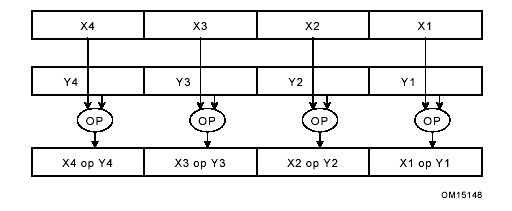
Рисунок 1. Схема вычислений SIMD
В процессорах Pentium 4 и Intel Xeon модель вычислений SIMD была далее расширена с помощью SSE2 и SSE3.
SSE2 работает с операндами, хранящимися в памяти или в XMM регистрах. Технология SSE2 расширяет вычисления SIMD для работы с упакованными элементами данных с плавающей точкой двойной точности и 128-битными упакованными целыми числами. В SSE2 введены 144 дополнительные команды для работы с двумя элементами данных с плавающей точкой двойной точности или над упакованными целыми числами в виде шестнадцати байтов, восьми слов, четырех двойных слов и двух четверных слов.
SSE3 улучшает x87, SSE и SSE2 с помощью добавления тринадцати инструкций, позволяющих повысить производительность приложений в специфичных областях. Таких как: обработка видео, комплексная арифметика синхронизация потоков. SSE3 дополняет SSE и SSE2 с помощью команд ассиметричной обработки данных SIMD, команд позволяющих горизонтальные вычисления, а так же команд позволяющих избежать загрузки в кэш разделенных нитей.
Полный набор технологий SIMD (MMX, SSE, SSE2, SSE3) в технологии IA-32 дает возможность программисту разрабатывать алгоритмы, совмещающие операции над упакованными 64-битными и 128-битными целыми, и операндами с плавающей точкой одинарной и двойной точности.
|
|
|

Рисунок 2. Регистры SIMD
SIMD улучшает выполнение 3D графики, распознавание речи, обработки изображений, научных приложений и приложений удовлетворяющих следующим характеристикам:
· Внутренняя параллельность
· Рекурсивный доступ к областям памяти
· Локальные рекурсивные операции над данными
· Контроль над потоком независимых данных
Инструкции SIMD для работы с числами с плавающей точкой полностью поддерживают стандарт IEEE 754 «для бинарной арифметики чисел с плавающей точкой». Они доступны во всех режимах работы процессора.
Технологии SSE, SSE2 и MMX – это архитектурные дополнения архитектуры IA-32. SSE и SSE2 также включают инструкции кэширования и организации памяти, которые могут улучшить использование КЭШа и производительность приложений.
Краткое обозрение технологий SIMD
Технология MMX
Технология MMX основывается на:
· 64-битных MMX-регистрах
· поддержке операций SIMD над упакованными целыми в виде байтов, слов и двойных слов
Инструкции MMX полезны в мультимедийных и коммуникационных приложениях
SSE
SSE основывается на:
· 128-битных XMM-регистрах
· 128-битных типах данных, содержащих четыре упакованных операнда с плавающей точкой одинарной точности
· инструкциях предвыборки данных
· инструкциях хранения в течение неопределенного срока и других инструкций кэширования и упорядочивания памяти
· дополнительной поддержке 64-битных целых SIMD
Инструкции SSE полезны при обработке трехмерной геометрии, 3D-рендеринга, распознавания речи, а также для кодирования и декодирования видео.
SSE2
SSE2 добавляют следующее:
· 128-битный тип данных с двумя упакованными операндами с плавающей точкой двойной точности
· 128-битные типы данных для целочисленных операций SIMD над целыми в виде шестнадцати байт, восьми слов, четырех двойных слов или двух четверных слов.
· Поддержку арифметики SIMD над 64-битными целочисленными операндами
· Инструкции для конвертирования между новыми и существующими типами данных
· Дополнительная поддержка перемешивания данных
· Дополнительная поддержка операций кэширования и упорядочивания памяти
Инструкции SSE2 полезны для обработки 3D графики, кодирования и декодирования видео и шифрования.
|
|
|
SSE3
SSE3 добавляет следующее:
· SIMD операции с плавающей точкой для ассиметричных и горизонтальных вычислений
· Специальную 128-битную загрузочную инструкцию для избежания разделения нити КЭШа
· x87 FPU – инструкцию для конвертирования в целое независимо от FCW (floating-point control word)
· инструкции для поддержки синхронизации потоков
Инструкции SSE3 могут применяться в научных, видео и многопоточных приложениях.
|
|
|
