 |


Исполнительные блоки и выводные порты
|
|
|
|
На каждом цикле ядро может посылать микрокоманды в один или несколько из четырех портов вывода. На микроархитектурном уровне операции хранения делятся на две группы:
1. операции хранения данных
2. операции хранения адресов
Четыре порта, через которые микрокоманды выводятся в исполнительные блоки и служащие для операций загрузки и хранения показаны на рисунке 4. Некоторые порты могут выводить до двух микрокоманд за такт. Они обозначены как исполнительные блоки двойной скорости.
Порт 0. В первой половине цикла, нулевой порт может вывести либо одну сдвиговую микрокоманду с плавающей точкой (сдвиг стека для плавающей точки, обмен между операндами с плавающей точкой или сохранение данных с плавающей точкой), либо одну из микрокоманд арифметико-логического устройства (арифметические, логические, ветвление или сохранение данных). Во второй половине цикла порт может вывести схожую микрокоманду АЛУ.
Порт 1. В первой части цикли первый порт может вывести либо одну из исполнительных операций с плавающей точкой (все исключительные сдвиговые операции с плавающей точкой, все операции SIMD), либо одну арифметическую АЛУ микрокоманду. Во второй части цикла порт может вывести одну схожую микрокоманду АЛУ.
Порт 2. Этот порт обеспечивает вывод одной загрузочной операции за цикл.
Порт 3. Этот порт обеспечивает вывод одной операции сохранения адреса за цикл.
Общая выводная мощность может варьироваться от нуля до шести микрокоманд за цикл. Каждый конвейер состоит из нескольких исполнительных блоков. Микрокоманда помещается в блок конвейера, отвечающий правильному типу операций. Например, целочисленный АЛУ и блок исполнения операций с плавающей точкой (сумматор, множитель или делитель) могут разделять один конвейер.
|
|
|
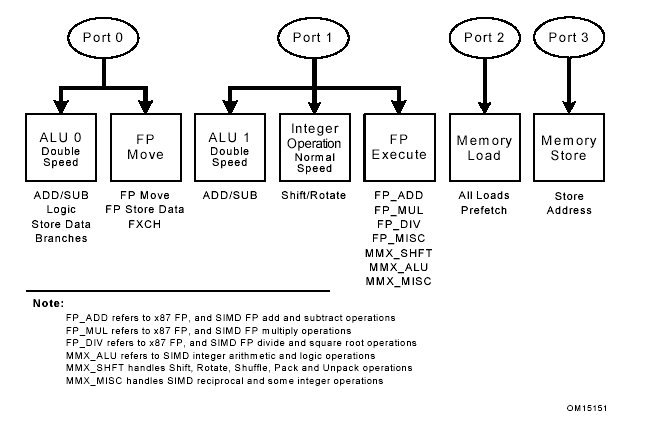
Рисунок 4. Исполнительные блоки и порты беспорядочного ядра
Кэши
Микроархитектура Intel NetBurst поддерживает до трех уровней встроенного КЭШа. По крайней мере, два уровня КЭШа встроены в процессоры, основанные на микроархитектуре Intel NetBurst. Процессоры Intel Xeon MP могут содержать кэш третьего уровня.
Кэш первого уровня (ближайший к исполнительному ядру) состоит из раздельных КЭШей инструкций и данных. Они включают кэш данных первого уровня и кэш трасс (улучшенный кэш инструкций первого уровня). Все остальные кэши делятся между инструкциями и данными.
Уровни в иерархии КЭШа не взаимовключающие. Факт того, что нить находиться на уровне N не означает, что она так же находиться на уровне N+1. Все кэши используют алгоритм замен псевдо-НЧИ (наименее часто используемые).
Таблица 1 приводит сравнительные параметры КЭШей всех уровней процессоров Pentium 4 и Xeon.
Таблица 1. Параметры кэша процессоров Pentium 4 и Intel Xeon

На процессорах без КЭШа третьего уровня, промах КЭШа второго уровня инициирует транзакцию через интерфейс системной шины в подсистему памяти. На процессорах с тремя уровнями КЭШа, промах КЭШа третьего уровня инициирует транзакцию через системную шину. Транзакция записи через шину записывает 64 байта в кэшируемую память, или раздельные восьми байтные контейнеры, если место назначения не кэшируется. Транзакция чтения через шину из кэшируемой памяти извлекает две нити данных КЭШа.
Интерфейс системной шины поддерживает работу с масштабируемой частотой шины и достигает эффективной скорости в четыре раза превышающей скорость шины. Маршрут от входа в шину и обратно занимает двенадцать процессорных циклов, и от шести до двенадцати циклов для доступа к памяти, если шина не перегружена. Каждый цикл шины соответствует нескольким циклам процессора. Отношение тактовой частоты процессора к масштабируемой тактовой частоте системной шины, если один цикл шины. Например, один цикл шины с частотой 100 МГц эквивалентен пятнадцати циклом процессора в 1,5 ГГц процессоре.
|
|
|
Предвыборка данных
Процессоры Intel Xeon и Pentium 4 имеют два механизма предвыборки данных: программно управляемая предвыборка и автоматическая аппаратная предвыборка.
Программно управляемая предвыборка включается с помощью четырех инструкций предвыборки (PREFETCHh) представленных в SSE. Программно управляемая предвыборка не обязательна для предвыборки кодов. Ее использование может привести к большим проблемам в многопроцессорных системах, если код разделен между процессорами.
Программно управляемая предвыборка данных может принести выгоду в следующих ситуациях:
· когда блок команд доступа к памяти в приложении позволяет программисту перекрыть задержки доступа к памяти
· когда точный выбор может быть сделан, основываясь на знании количества нитей кэша к выбору в дальнейшем перед исполнением текущей нити
· когда выбор может быть сделан, основываясь на знании того, какую предвыборку необходимо использовать
Инструкции предвыборки SSE имеют различные характеры поведения в зависимости от уровня кэша и реализации процессора. Например, в процессоре может быть реализована постоянная предвыборка, путем возврата данных в уровень кэша, ближайший к ядру процессора. Такой метод приводит к следующему:
· минимизирует нарушения временных данных в других уровнях кэша
· предупреждает необходимость доступа к внекристальным КЭШам, что может увеличить реализованную мощность относительно неправильной загрузки, которая перегружает данные во все уровни кэша
Ситуации, в которых не желательно использовать программно управляемую предвыборку:
· в случаях, когда запросы определены, предвыборка приводит к увеличению требований запросов
· в случае предвыборки далеко вперед, она может привести к вытеснению кэшированных данных из кэша раньше, чем они будут использованы
· слишком близкая предвыборка может снизить возможность к перекрытию задержек доступа к памяти и выполнения
Программные предвыборки потребляют ресурсы в процессоре, и использование слишком многих предвыборок может ограничить их эффективность. Примеры таких предвыборок включают предвыборку данных в цикле для не зависимости от информации находящейся вне цикла и предвыборку в основных блоках, которые часто исполняются, но которые редко используют ее не зависимо от целей предвыборки.
|
|
|
Автоматическая аппаратная предвыборка – механизм, реализованный в процессорах Intel Xeon и Intel Pentium 4. Она заносит нити кэша в унифицированный кэш второго уровня, основанный на ранних независимых моделях.
|
|
|
