 |


Каким образом определяется модель множественной линейной регрессии?
|
|
|
|
модель множественной линейной регрессии.
Теоретическое линейное уравнение регрессии имеет вид:
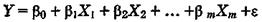
или для индивидуальных наблюдений i, i = 1, 2,…, n,

Здесь  — вектор размерности (т + 1) неизвестных параметров.
— вектор размерности (т + 1) неизвестных параметров. 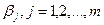 , у = 1, 2,..., т, называется
, у = 1, 2,..., т, называется  -м теоретическим коэффициентом регрессии (частичным коэффициентом регрессии). Он характеризует чувствительность величины Y к изменению
-м теоретическим коэффициентом регрессии (частичным коэффициентом регрессии). Он характеризует чувствительность величины Y к изменению 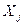 . Другими словами, он отражает влияние на условное математическое ожидание M(
. Другими словами, он отражает влияние на условное математическое ожидание M( ) зависимой переменной У объясняющей переменной Хj при условии, что все другие объясняющие переменные модели остаются постоянными.
) зависимой переменной У объясняющей переменной Хj при условии, что все другие объясняющие переменные модели остаются постоянными.  — свободный член, определяющий значение У в случае, когда все объясняющие переменные Xj) равны нулю.
— свободный член, определяющий значение У в случае, когда все объясняющие переменные Xj) равны нулю.
После выбора линейной функции в качестве модели зависимости необходимо оценить параметры регрессии.
Пусть имеется n наблюдений вектора объясняющих переменных X = (X1, X2,..., Хт) и зависимой переменной У:

Для того чтобы однозначно можно было бы решить задачу отыскания параметров  (т.е. найти некоторый наилучший вектор
(т.е. найти некоторый наилучший вектор  ), должно выполняться неравенство
), должно выполняться неравенство  . Если это неравенство не будет выполняться, то существует бесконечно много различных векторов параметров, при которых линейная формула связи между X и У будет абсолютно точно соответствовать имеющимся наблюдениям. При этом, если
. Если это неравенство не будет выполняться, то существует бесконечно много различных векторов параметров, при которых линейная формула связи между X и У будет абсолютно точно соответствовать имеющимся наблюдениям. При этом, если 
 , то оценки коэффициентов вектора рассчитываются единственным образом — путем решения системы т + 1 линейного уравнения:
, то оценки коэффициентов вектора рассчитываются единственным образом — путем решения системы т + 1 линейного уравнения:

Например, для однозначного определения оценок параметров уравнения регрессии  достаточно иметь выборку из трех наблюдений (
достаточно иметь выборку из трех наблюдений ( ), i = 1, 2, 3. В этом случае найденные значения параметров
), i = 1, 2, 3. В этом случае найденные значения параметров 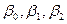 определяют такую плоскость в трехмерном пространстве, которая пройдет именно через имеющиеся три точки. С другой стороны, добавление в выборку к имеющимся трем наблюдениям еще одного приведет к тому, что четвертая точка (
определяют такую плоскость в трехмерном пространстве, которая пройдет именно через имеющиеся три точки. С другой стороны, добавление в выборку к имеющимся трем наблюдениям еще одного приведет к тому, что четвертая точка ( ) практически наверняка будет лежать вне построенной плоскости (и, возможно, достаточно далеко). Это потребует определенной переоценки параметров.
) практически наверняка будет лежать вне построенной плоскости (и, возможно, достаточно далеко). Это потребует определенной переоценки параметров.
|
|
|
Таким образом, вполне логичен следующий вывод: если число наблюдений больше минимально необходимого, т.е. n > m+1, то уже нельзя подобрать линейную форму, в точности удовлетворяющую всем наблюдениям, и возникает необходимость оптимизации, т.е. оценивания параметров , при которых формула дает наилучшее приближение для имеющихся наблюдений.
В данном случае число  = n — т — 1 называется числом степеней свободы. Нетрудно заметить, что если число степеней свободы невелико, то статистическая надежность оцениваемой формулы невысока. Например, вероятность верного вывода (получения более точных оценок) по трем наблюдениям существенно ниже, чем по тридцати. Считается, что при оценивании множественной линейной регрессии для обеспечения статистической надежности требуется, чтобы число наблюдений по крайней мере в 3 раза превосходило число оцениваемых параметров.
= n — т — 1 называется числом степеней свободы. Нетрудно заметить, что если число степеней свободы невелико, то статистическая надежность оцениваемой формулы невысока. Например, вероятность верного вывода (получения более точных оценок) по трем наблюдениям существенно ниже, чем по тридцати. Считается, что при оценивании множественной линейной регрессии для обеспечения статистической надежности требуется, чтобы число наблюдений по крайней мере в 3 раза превосходило число оцениваемых параметров.
Самым распространенным методом оценки параметров уравнения множественной линейной регрессии является метод наименьших квадратов (МНК). Напомним, что его суть состоит в минимизации суммы квадратов отклонений наблюдаемых значений зависимой переменной У от ее значений У, получаемых по уравнению регрессии.
Предпосылки МНК. Каковы последствия их невыполнимости?
Предпосылки МНК
1°. Математическое ожидание случайного отклонения  равно нулю для всех наблюдений:
равно нулю для всех наблюдений:
M() = 0, i = 1, 2,..., п.
2°.Гомоскедастичностъ (постоянство дисперсии отклонений). Дисперсия случайных отклонений < постоянна:
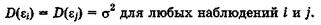
3°. Отсутствие автокорреляции.
Случайные отклонения и  - являются независимыми друг от друга для всех
- являются независимыми друг от друга для всех 
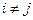
|
|
|

4°. Случайное отклонение должно быть независимо от объясняющих переменных.

5°. Модель является линейной относительно параметров.. Для случая ножественной линейной регрессии существенными являются еще две предпосылки.
6°. Отсутствие мультиколлинеарности.
Между объясняющими переменными отсутствует строгая (сильная) линейная зависимость.
7°. Ошибки , i = 1, 2,..., n, имеют нормальное распределение ( .
.
Выполнимость данной предпосылки важна для проверки статистических гипотез и построения интервальных оценок.
При невыполнимости данной предпосылки (при гетероскедастичности) последствия применения МНК будут следующими.
Оценки коэффициентов по-прежнему останутся несмещенными и линейными.
1. Оценки не будут эффективными (т.е. они не будут иметь наименьшую дисперсию по сравнению с другими оценками данного параметра). Они не будут даже асимптотически эффективными. Увеличение дисперсии оценок снижает вероятность получения максимально точных оценок.
2. Дисперсии оценок будут рассчитываться со смещением. Смещенность появляется вследствие того, что не объясненная
уравнением регрессии дисперсия  (т - число объ
(т - число объ  ясняющих переменных), которая используется при вычислении оценок дисперсий всех коэффициентов (формула (6.23)), не является более несмещенной.
ясняющих переменных), которая используется при вычислении оценок дисперсий всех коэффициентов (формула (6.23)), не является более несмещенной.
4. Вследствие вышесказанного все выводы, получаемые на основе соответствующих t- и F-статистик, а также интервальные оценки будут ненадежными. Следовательно,статистические выводы, получаемые при стандартных проверках качества оценок, могут быть ошибочными и приводить к неверным за иключениям по построенной модели. Вполне вероятно, что стандартные ошибки коэффициентов будут занижены, а следовательно, t-статистики будут завышены. Это может привести к признанию статистически значимыми коэффициентов, таковыми на самом деле не являющихся.
1. 13)Характеристика коэффициентов уравнения регрессии. С помощью т статистики, Р, грубое правило
|
|
|
