 |


Построение расширенного МП-автомата.
|
|
|
|
Будем строить расширенный МП-автомат, который выполняет правосторонний разбор входной строки, образованной из терминалов грамматики. Стек отведем для левой части текущей сентенциальной формы. Сначала это особый магазинный символ, маркер пустого стека (обозначим #). На каждом шаге автомат по правилу грамматики замещает нетерминалом строку верхних символов стека или дописывает в вершину входной символ. Помимо единственного текущего состояния, автомат имеет одно заключительное состояние. В этом состоянии стек пуст.
Вход: КС-грамматика  .
.
Выход: Расширенный МП-автомат  такой, что
такой, что  .
.
1. Положить 
2. Для каждого правила вида  , где
, где  , сформировать магазинную функцию вида
, сформировать магазинную функцию вида  , предписывающую заменять правую часть правила в вершине стека нетерминалом из левой части, независимо от текущего символа входной строки.
, предписывающую заменять правую часть правила в вершине стека нетерминалом из левой части, независимо от текущего символа входной строки.
3. Для каждого 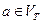 сформировать магазинную функцию вида
сформировать магазинную функцию вида  , которая помещает символ входной строки в вершину стека, если там нет правой части правила, и перемещает читающую головку.
, которая помещает символ входной строки в вершину стека, если там нет правой части правила, и перемещает читающую головку.
4. Предусмотреть магазинную функцию для перевода автомата в заключительное состояние  .
.
Параграф 5. Нисходящие распознаватели языков.
Пункт 1. Стратегия нисходящего анализа.
В основе стратегии нисходящего анализа лежит левосторонний разбор строки языка. Исходной сентенциальной формой является аксиома грамматики, а целевой – заданная строка языка. На каждом шаге разбора правило грамматики применяется к самому левому нетерминалу сентенциальной формы. Может возникнуть основная проблема нисходящего анализа - неоднозначность выбора правила грамматики. Эта проблема решается привлечением группы очередных символов входной строки.
|
|
|
Пример 1. Дана КС-грамматика  , где
, где  ,
,  и множество
и множество 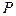 состоит из шести правил:
состоит из шести правил:
1)  2)
2)  3)
3)  4)
4)  5)
5)  6)
6)  .
.
Требуется выполнить нисходящий анализ строки  . Обратим внимание, что каждый нетерминал грамматики имеет по два правила, но они начинаются с разных терминалов. Этим свойством грамматики будем пользоваться при выборе правила, сопоставляя очередной символ входной строки с головным символом правой части. Построим дерево разбора:
. Обратим внимание, что каждый нетерминал грамматики имеет по два правила, но они начинаются с разных терминалов. Этим свойством грамматики будем пользоваться при выборе правила, сопоставляя очередной символ входной строки с головным символом правой части. Построим дерево разбора:

Сначала в стек помещается аксиома  , а читающая головка указывает на левый символ
, а читающая головка указывает на левый символ 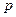 строки. На каждом шаге работы распознавателя выполняется следующая работа:
строки. На каждом шаге работы распознавателя выполняется следующая работа:
1) читается символ входной строки (терминал);
2) если в вершине стека находится такой же терминал, то он удаляется из стека; читающая головка перемещается на одну позицию вправо; шаг завершается;
3) если в вершине стека находится нетерминал, то он замещается правой частью соответствующего правила, начинающейся с прочитанного терминала; шаг завершается;
4) если во входной строке больше нет символов и стек пуст, то строка принята; анализ завершен;
5) если нет подходящего правила для нетерминала или возникла другая неопределенная ситуация, то строка не будет принята.
Процесс нисходящего анализа сведем в таблицу:
| № п/п | Входная строка | Стек | Правило |
|
|
| ||
|
| 
| ||

| 
| ||
|
| 
| ||

| 
| ||
|
| 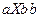
| ||

| 
| ||
|
|
| ||

|
| ||

|
| ||
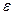
|
|
-грамматиками называются КС-грамматики со следующими свойствами:
1. правила грамматики имеют вид  , где
, где  .
.
2. альтернативные правые части правил, определяющие один и тот же нетерминал, начинаются с разных терминалов.
Первое свойство обеспечивает выбор очередного правила грамматики, а второе свойство делает этот выбор однозначным, то есть позволяет построить детерминированный распознаватель.
Пункт 2. LL(k)-грамматики.
В КС-грамматиках можно выделить обширное подмножество грамматик, обладающих сходными свойствами и обеспечивающих детерминированный нисходящий разбор строк порождаемых языков. Это подмножество называют LL(k)-грамматиками, причем буквы L, L, k означают следующее:
|
|
|
 L – просмотр строки языка осуществляется слева направо (левосторонний просмотр);
L – просмотр строки языка осуществляется слева направо (левосторонний просмотр);
L – строится левосторонний вывод (левосторонний разбор);
K – используется k предварительно просматриваемых символов входной строки для выбора очередного правила грамматики. Чем больше k, тем более сложные языки описывает грамматика и тем сложнее распознаватели этих языков.
В большинстве практических приложений можно ограничиться LL(1)-грамматиками. S-грамматики являются частным случаем LL(1)-грамматик. В LL(1)-грамматиках головными символами в правых частях правил наряду с терминалами могут быть и нетерминалы.
КС-грамматику называют LL(1)-грамматикой, если не пересекаются множества направляющих символов для правил, определяющих один и тот же нетерминал грамматики.
Обозначим  - множество направляющих символов для правила
- множество направляющих символов для правила  , где
, где  и
и 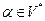 . Формально
. Формально  .
.
Множество  называют множеством символов-предшественников для строки
называют множеством символов-предшественников для строки 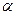 и определяют так:
и определяют так:
 .
.
Отсюда следует, что - это множество терминалов, которые получаются как головные символы строк, выводимых из непустой строки .
Множество  назовем множеством символов-последователей для нетерминала и определим его так:
назовем множеством символов-последователей для нетерминала и определим его так:

Эта запись означает, что - это множество терминалов, которые могут появляться в сентенциальных формах непосредственно за нетерминалом . Напомним, что сентенциальная форма – это любое порождение начального символа грамматики. Множество принимается во внимание только в том случае, если существует вывод  (то есть вывод пустой строки из правой части правила для нетерминала ).
(то есть вывод пустой строки из правой части правила для нетерминала ).
Проверку принадлежности КС-грамматики классу LL(1)-грамматик можно выполнить на основе определения LL(1)-грамматики, то есть путем вычисления пересечения множеств направляющих символов для альтернативных правых частей правил нетерминала. Кроме того имеются признаки, по которым достаточно просто установить, что заданная КС-грамматика не является LL(1)-грамматикой. К таким признакам относятся:
|
|
|
одинаковые головные символы в альтернативных правых частях правил для нетерминала, например  или
или  ;
;
наличие левой рекурсии (прямой или косвенной), например  .
.
|
|
|
