 |


Критерии распознавания открытого текста
|
|
|
|
Математические модели открытого текста
Потребность в математических моделях открытого текста продиктована, прежде всего, следующими соображениями. Во-первых, даже при отсутствии ограничений на временные и материальные затраты по выявлению закономерностей, имеющих место в открытых текстах, нельзя гарантировать того, что такие свойства указаны с достаточной полнотой. Например, хорошо известно, что частотные свойства текстов в значительной степени зависят от их характера. Поэтому при математических исследованиях свойств шифров прибегают к упрощающему моделированию, в частности, реальный открытый текст заменяется его моделью, отражающей наиболее важные его свойства. Во-вторых, при автоматизации методов криптоанализа, связанных с перебором ключей, требуется "научить" ЭВМ отличать открытый текст от случайной последовательности знаков. Ясно, что соответствующий критерий может выявить лишь адекватность последовательности знаков некоторой модели открытого текста.
Один из естественных подходов к моделированию открытых текстов связан с учетом их частотных характеристик, приближения для которых можно вычислить с нужной точностью, исследуя тексты достаточной длины. Основанием для такого подхода является устойчивость частот к -грамм или целых словоформ реальных языков человеческого общения (то есть отдельных букв, слогов, слов и некоторых словосочетаний). Основанием для построения модели может служить также и теоретико-информационный подход, развитый в работах К. Шеннона.
Учет частот k-грамм приводит к следующей модели открытого текста. Пусть Р(k)(А) представляет собой массив, состоящий из приближений для вероятностей р(b1,b2,...,bk) появления k-грамм b 1bг...bk в открытом тексте, k  N,
N,
|
|
|
А = (а1,...,ап) — алфавит открытого текста, bi  A, i = 1,k.
A, i = 1,k.
Тогда источник "открытого текста" генерирует последовательность с1,с2,...,сk,сk+1,... знаков алфавита А, в которой k-грамма с1с2...сk появляется с вероятностью р(с1с2...сk) е Р(k)(А), следующая k-грамма с1с2...сk+1 появляется с вероятность р(с2с3...сk+1) Р(k)(А) и т. д. Назовем построенную модель открытого текста вероятностной моделью k-го приближения.
Таким образом, простейшая модель открытого текста - вероятностная модель первого приближения – представляет собой последовательность знаков с1,с2,..., в которой каждый знак ci, i = 1,2,..., появляется с вероятностью р(сi) P(1)(A), независимо от других знаков. Будем называть также эту модель позначной моделью открытого текста. В такой модели открытый текст с1с2...с1 имеет вероятность
 .
.
В вероятностной модели второго приближения первый знак с1 имеет вероятность р(с1) P(1)(A), а каждый следующий знак сi зависит от предыдущего и появляется с вероятностью
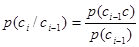 ,
,
где р(сi-1сi) Р(2)(А), р(сi-1) Р(1)(A), i = 2,3,.... Другими словами, модель открытого текста второго приближения представляет собой простую однородную цепь Маркова. В такой модели открытый текст с1с2...сl имеет вероятность
 .
.
Модели открытого текста более высоких приближений учитывают зависимость каждого знака от большего числа предыдущих знаков. Ясно, что чем выше степень приближения, тем более "читаемыми" являются соответствующие модели. Проводились эксперименты по моделированию открытых текстов с помощью ЭВМ.
Отметим, что с более общих позиций открытый текст может рассматриваться как реализация стационарного эргодического случайного процесса с дискретным временем и конечным числом состояний.
Критерии распознавания открытого текста
Заменив реальный открытый текст его моделью, мы можем теперь построить критерий распознавания открытого текста. При этом можно воспользоваться либо стандартными методами различения статистических гипотез, либо наличием в открытых текстах некоторых запретов, таких, например, как биграмма ЪЪ в русском тексте. Проиллюстрируем первый подход при распознавании позначной модели открытого текста.
|
|
|
Итак, согласно нашей договоренности, открытый текст представляет собой реализацию независимых испытаний случайной величины, значениями которой являются буквы алфавита А = {а1,...,ап}, появляющиеся в соответствии с распределением вероятностей Р(1)(А) = (р(а1),...,р(ап)). Требуется определить, является ли случайная последовательность с1с2...сl букв алфавита А открытым текстом или нет.
Пусть Н0 — гипотеза, состоящая в том, что данная последовательность — открытый текст, Н1 — альтернативная гипотеза. В простейшем случае последовательность c1c2...cl можно рассматривать при гипотезе Н1 как случайную и равновероятную. Эта альтернатива отвечает субъективному представлению о том, что при расшифровании криптограммы с помощью ложного ключа получается "бессмысленная" последовательность знаков. В более общем случае можно считать, что при гипотезе Н1 последовательность c1c2...cl представляет собой реализацию независимых испытаний некоторой случайной величины, значениями которой являются буквы алфавита А = {а1,...,ап}, появляющиеся в соответствии с распределением вероятностей Q(1)(A)= (q(al),...,q(an)). При таких договоренностях можно применить, например, наиболее мощный критерий различения двух простых гипотез, который дает лемма Неймана — Пирсона.
В силу своего вероятностного характера такой критерий может совершать ошибки двух родов. Критерий может принять открытый текст за случайный набор знаков. Такая ошибка обычно называется ошибкой первого рода, ее вероятность равна  = p{H1/H0}. Аналогично вводится ошибка второго рода и ее вероятность
= p{H1/H0}. Аналогично вводится ошибка второго рода и ее вероятность  = p{Н0/Н1}. Эти ошибки определяют качество работы критерия. В криптографических исследованиях естественно минимизировать вероятность ошибки первого рода, чтобы не "пропустить" открытый текст. Лемма Неймана—Пирсона при заданной вероятности первого рода минимизирует также вероятность ошибки второго рода.
= p{Н0/Н1}. Эти ошибки определяют качество работы критерия. В криптографических исследованиях естественно минимизировать вероятность ошибки первого рода, чтобы не "пропустить" открытый текст. Лемма Неймана—Пирсона при заданной вероятности первого рода минимизирует также вероятность ошибки второго рода.
|
|
|
Критерии на открытый текст, использующие запретные сочетания знаков, например к -граммы подряд идущих букв, будем называть критериями запретных k-грамм. Они устроены чрезвычайно просто. Отбирается некоторое число s редких k -грамм, которые объявляются запретными. Теперь, просматривая последовательно k- грамму за k -граммой анализируемой последовательности c1c2...cl, мы объявляем ее случайной, как только в ней встретится одна из запретных k- грамм, и открытым текстом в противном случае. Такие критерии также могут совершать ошибки в принятии решения. В простейших случаях их можно рассчитать. Несмотря на свою простоту, критерии запретных k -грамм являются весьма эффективными.
Классификация шифров
В качестве первичного признака, по которому производится классификация шифров, используется тип преобразования, осуществляемого с открытым текстом при шифровании. Если фрагменты открытого текста (отдельные буквы или группы букв) заменяются некоторыми их эквивалентами в шифртексте, то соответствующий шифр относится к классу шифров замены. Если буквы открытого текста при шифровании лишь меняются местами друг с другом, то мы имеем дело с шифром перестановки. С целью повышения надежности шифрования шифрованный текст, полученный применением некоторого шифра, может быть еще раз зашифрован с помощью другого шифра. Всевозможные такие композиции различных шифров приводят к третьему классу шифров, которые обычно называют композиционными шифрами. Заметим, что композиционный шифр может не входить ни в класс шифров замены, ни в класс шифров перестановки (рис. 1).

Рисунок 1. Классификация шифров
Шифры перестановки
Шифры перестановки, или транспозиции, изменяют только порядок следования символов или других элементов исходного текста. Классическим примером такого шифра является система, использующая карточку с отверстиями – решетку Кардано, которая при наложении на лист бумаги оставляет открытыми лишь некоторые его части. При зашифровке буквы сообщения вписываются в эти отверстия. При расшифровке сообщение вписывается в диаграмму нужных размеров, затем накладывается решетка, после чего на виду оказываются только буквы открытого текста.
|
|
|
Решетки можно использовать двумя различными способами. В первом случае зашифрованный текст состоит только из букв исходного сообщения. Решетка изготавливается таким образом, чтобы при ее последовательном использовании в различных положениях каждая клетка лежащего под ней листа бумаги оказалась занятой. Примером такой решетки является поворотная решетка,показанная на рис.1. Если такую решетку последовательно поворачивать на 90° после заполнения всех открытых при данном положении клеток, то при возврате решетки в исходное положение все клетки окажутся заполненными. Числа, стоящие в клетках, облегчают изготовление решетки. В каждом из концентрических окаймлений должна быть вырезана только одна клетка из тех, которые имеют одинаковый номер. Второй, стеганографический метод использования решетки позволяет скрыть факт передачи секретного сообщения. В этом случае заполняется только часть листа бумаги, лежащего под решеткой, после чего буквы или слова исходного текста окружаются ложным текстом.
| 1 | 2 | 3 | 4 | 5 | 1 |
| 5 | 1 | 2 | 3 | 1 | 2 |
| 4 | 3 | 1 | 1 | 2 | 3 |
| 3 | 2 | 1 | 1 | 3 | 4 |
| 2 | 1 | 3 | 2 | 1 | 5 |
| 1 | 5 | 4 | 3 | 2 | 1 |
Рисунок 2. Пример поворотной решетки
Рассмотрим усложненную перестановку по таблице. Пример таблицы для реализации этого метода шифрования показан на рис.3. Таблица представляет собой матрицу размерностью 6 х 6, в которую построчно вписывается искомое сообщение. При считывании информации по столбцам в соответствии с последовательностью чисел ключа получается шифротекст. Усложнение заключается в том, что некоторые ячейки таблицы не используются. При зашифровании сообщения
КОМАНДОВАТЬ ПАРАДОМ БУДУ Я
получим:
ОЬБНАОДКДМУМВ АУ ОТР ААПДЯ,
| Ключ | |||||
| 2 | 4 | 0 | 3 | 5 | 1 |
| К | О | М | А | Н | |
| Д | О | В | А | ||
| Т | Ь | П | А | ||
| Р | А | Д | О | ||
| М | Б | У | Д | ||
| У | Я | ||||
Рисунок 3. Пример шифрования методом усложненной перестановки по таблице
При расшифровании буквы шифротекста записываются по столбцам в соответствии с последовательностью чисел ключа, после чего исходный текст считывается по строкам. Для удобства запоминания ключа применяют перестановку столбцов таблицы по ключевому слову или фразе, всем символам которых ставятся в соответствие номера, определяемые порядком соответствующих букв в алфавите. Например, при выборе в качестве ключа слова ИНГОДА последовательность использования столбцов будет иметь вид 462531.
|
|
|
Также возможны и другие варианты шифра перестановки, например, шифры столбцовой и двойной перестановки.
Шифры замены
Большое влияние на развитие криптографии оказали появившиеся в середине XX века работы американского математика Клода Шеннона. В этих работах были заложены основы теории информации, а также был разработан математический аппарат для исследований во многих областях науки, связанных с информацией. Более того, принято считать, что теория информации как наука родилась в 1948 году после публикации работы К. Шеннона «Математическая теория связи» (см. приложение).
В своей работе «Теория связи в секретных системах» Клод Шеннон обобщил накопленный до него опыт разработки шифров. Оказалось, что даже в очень сложных шифрах в качестве типичных компонентов можно выделить такие простые шифры как шифры замены, шифры перестановки или их сочетания.
Шифр замены является простейшим, наиболее популярным шифром. Типичными примерами являются шифр Цезаря, «цифирная азбука» Петра Великого и «пляшущие человечки» А. Конан Дойла. Как видно из самого названия, шифр замены осуществляет преобразование замены букв или других «частей» открытого текста на аналогичные «части» шифрованного текста. Легко дать математическое описание шифра замены. Пусть X и Y – два алфавита (открытого и шифрованного текстов соответственно), состоящие из одинакового числа символов. Пусть также g: X —> Y — взаимнооднозначное отображение Х в Y. Тогда шифр замены действует так: открытый текст х1х2...хп преобразуется в шифрованный текст g(x1)g(x2)... g(хп).
Шифр перестановки, как видно из названия, осуществляет преобразование перестановки букв в открытом тексте. Типичным примером шифра перестановки является шифр «Сцитала». Обычно открытый текст разбивается на отрезки равной длины и каждый отрезок шифруется независимо. Пусть, например, длина отрезков равна п и σ — взаимнооднозначное отображение множества {1,2,..., п} в себя. Тогда шифр перестановки действует так: отрезок открытого текста х1...хп преобразуется в отрезок шифрованного текста
|
|
|
