 |


Задание на лабораторную работу
|
|
|
|
1. Выбрать Aztec код в соответствии с вариантом по имени Вариант[номер варинта].bmp.
2. Расшифровать кодовые слова так, как показано на рисунках 9.7 и 9.8, указав кодовые слова без корректирующих слов Рида-Соломона.
3. Используя программу «VidikonReader.exe», проверьте как распознается код с различными видами зашумлений: только данных кода пиксельным зашумлением, мишени кода пиксельным зашумлением, всего кода с помощью шумовых линий.
4.4 Контрольные вопросы
1. Какие виды двумерных кодов вы знаете?
2. Каков общий алгоритм распознавания двумерного бар-кода?
3. Зачем необходима коррекция Рида-Соломона?
4. Какова разрядность кодовых слов в Aztec коде?
5. Какие виды высокоуровневого кодирования Aztec вы знаете?
Лабораторная работа № 5. Распознавание текста в графическом изображении
Цель работы: получить навыки использования шаблонного метода распознавания текста в графическом изображении
Теоретическая часть
Алгоритмы распознавания текста (OCR), как и многие другие алгоритмы работают с бинаризированным изображением. Бинаризация изображений – это перевод RGB или в градациях серого изображения в монохромное, где присутствуют только два типа пикселей (темные и светлые). Существуют различные подходы к бинаризации, которые условно можно разделить на 2 группы: пороговые, адаптивные.
Если говорить кратко, то пороговые методы бинаризации работают со всем изображением, находя какую-то характеристику (порог), позволяющую разделить все изображение на чёрное и белое. Адаптивные методы работают с участками изображений и используются при неоднородном освещении объектов.
Для того, чтобы использовать пороговый метод бинаризации, необходимо или самостоятельно задать порог, например, значение 128 при анализе изображения в градациях серого, или воспользоваться какими-либо критериями автоматического определения оптимального порогового значения. Наиболее известные методы – Отсу, Бернсена, Эйквеля, Ниблэка и т.п. Наиболее эффективным по качеству и скорости обработки считается метод Отсу.
|
|
|
Суть данных методов такова: пусть все пиксели изображения распределяются по гистограмме яркости так, как показано на рисунке 5.1, тогда пороговым значением яркости будет то, которое делит оптимальным образом пиксели на черные и белые.

|
Рисунок 5.1 – Пример гистограммы яркости для изображения
Метод Отсу использует гистограмму распределений значения яркости. Диапазон яркости делится на L элементов, в котором ищется два класса значений (т.е. ищутся две области на гистограмме с распределением пикселей вокруг них). Каждому классу соответствуют относительные частоты:

| (5.1) |
где N – общее количество пикселей на изображении, ni – количество пикселей с уровнем яркости i.
Средние уровни для каждых из двух классов изображения:
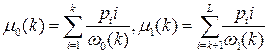 . .
| (5.2) |
Для каждого k из диапазона 1 ÷ L можно вычислить относительные частоты и средние уровни, после чего посчитать оценку качества разделения (качества порогового уровня) для каждого значения и найти максимум:

| (5.3) |
где σобщ 2 – общая дисперсия всего изображения.
Однако в случаях, когда изображение освещено неравномерно, описанный выше алгоритм применить достаточно сложно. Для этого необходимо использовать адаптивное преобразование в монохромное изображение. Задаются блоки на изображении с одинаковыми шириной и высотой, значения которых являются нечётными, т.к. они являются окрестностями центрального пикселя.
Суть метода такова: для каждого пикселя определяются окрестности, в которых вычисляется среднее значение яркости, которое и является пороговым значением T (x, y) для текущего пикселя. Для 24-битного изображения преобразование в монохромное изображение может осуществляться по следующей формуле:
|
|
|

| (5.4) |
где src (x, y) – RGB-значения пикселя с координатами x и y на исходном изображении, dst (x, y) – соответственно конечного изображения.
Пример отличия работы этих двух подходов на рисунке 5.2.
 (а)
(а)
  (б) (в)
(б) (в)
|
Рисунок 5.2 – Два подхода к преобразованию в монохромное изображение:
(а) – исходное изображение; (б) – бинарное; (в) – адаптивное преобразование
И тот и другой подходы имеет смысл применять в различных ситуациях с учётом необходимых требований. В библиотеке OpenCV данные преобразования осуществляются с помощью функций cvThreshold и cvAdaptiveThreshold. Помимо этих методов существуют еще множество комбинированных методов.
Предположим на некотором изображении есть текст, представленный на рисунке 5.3 (а).
 (а)
(а)
|  (б)
(б)
|
Рисунок 5.3 – Изображение с текстом: (а) – исходное; (б) – монохромное
Для того чтобы распознать символы, необходимо определить их местоположение. Однако в данной лабораторной работе задача будет упрощена, и на вход будет поступать изображение с одним символом. Первоначально изображение надо привести к монохромному изображению, используя адаптивный или пороговый подход, представленный на рисунке 5.3 (б).
Определить границу символа для распознавания достаточно просто после проведенной бинаризации. Для этого можно воспользоваться выделением контуров (функция cvFindContours() в OpenCV – описано в следующей лабораторной работе) либо заранее заданным местом поиска символа.
Конечно, известны методы распознавание текста на базе нейронных сетей, но существует ещё более простой метод (в плане обучения), основанный на сравнении с эталоном (шаблоном). В ряде случаев сравнение с шаблоном будет достаточно для распознавания текста. Суть шаблонного метода заключается в том, чтобы взять изображение символа и сравнить их со всеми эталонами, каждый из которых разделен на небольшие блоки.
На рисунке 5.5 приведено несколько примеров различного построения шаблонов для буквы «С».
|
|
|
 (а)
(а)
|  (б)
(б)
|
Рисунок 5.5 – Два варианта шаблона для буквы «С»:
(а) обыкновенный шаблон; (б) шаблон по методу зон
В обыкновенном шаблоне проверяется, заполнена ячейка или нет (естественно округляя, если полупустая) и умножается на коэффициент. В идеальном случае совпадение с буквой «С» будет возвращать значение 13 (сумма всех единиц), а, например, с буквой «B» сумма будет складываться так: -1+1+1+1+1-1-2-2-1+1+1+1+1+1-1+1+1+1+1-1-1=3. По наибольшему совпадению будет определяться тот образ, который и соответствует неизвестному. Также необходимо предусмотреть пороговое значение, ниже которого образ считается нераспознанным.
На рисунке 5.5 (б) представлен другой вариант, где на каждую ячейку шаблона выделяется не полностью вариант – совпало / не совпало – а выделяется вес этой ячейки, который будет сопоставляться с совпадением пикселей неизвестного образа. Естественно в обоих случаях размеры шаблонов можно увеличивать для увеличения точности распознавания.
Для того, чтобы сравнить область изображения с символом необходимо привести эту область к размеру шаблона или наоборот – шаблон к размеру области. Можно просто использовать известные методы увеличения, или написать самому.
В листинге 5.1 показан C-код, в котором осуществляется приведение к размеру шаблона (в данном случае шаблон 5 на 7).
Листинг 5.1. Приведение размеров неизвестного образа к шаблону
double a[5*7];
double a1[4];
uchar* ptr = (uchar*) (Image->imageData);
int x,y;
int x1,y1;
double x1_,y1_;
int x2,y2;
double x2_,y2_;
..../* Точками обозначен участок, где необходимо получить зону (Rect), где находится символ */
memset(a,0,5*7*sizeof(double));
for(y=0;y<Rect.height;y++)
for(x=0;x<Rect.width;x++){
if (ptr[x+Rect.x+(y+Rect.y)* Image->widthStep]==0) continue;
memset(a1,0,4*sizeof(double));
x1_=(double)x*ratioW;
y1_=(double)y*ratioH;
x1=int(x1_);y1=int(y1_);
x2_=(double)(x+1)*ratioW;
y2_=(double)(y+1)*ratioH;
x2=int(x2_);y2=int(y2_);
if (x2==x1) { a1[0]=1;a1[1]=0;}
else {
a1[0]=(double)(x1+1-x1_)/(x2_-x1_);
a1[1]=(double)(x2_-x2)/(x2_-x1_);
}
if (y2!=y1){
a1[2]=(double)a1[0]*(y2_-y2)/(y2_-y1_);
|
|
|
a1[3]=(double)a1[1]*(y2_-y2)/(y2_-y1_);
a1[0]=(double)a1[0]*(y1+1-y1_)/(y2_-y1_);
a1[1]=(double)a1[1]*(y1+1-y1_)/(y2_-y1_);
}
a[x1+y1*7]+=a1[0];
if (x1<4)
a[x1+1+y1*7]+=a1[1];
if (y1<6)
a[x1+(y1+1)*7]+=a1[2];
if (x1<4 && y1<6)
a[x1+1+(y1+1)*7]+=a1[3];
}
В листинге 5.1 перебираются каждые точки, относящиеся к символу, после чего происходит их отнесение к той или иной ячейки изображения, причем не всегда полностью, но и частично – часть пикселя в одну ячейку, часть в другую. Далее можно сравнить полученный результат с каждым из эталонов, просто перемножив соответствующие элементы матрицы. И по наибольшему совпадению выбрать эталон.
На рисунке 5.6 приведено несколько примеров подобных искажений на базе автомобильных номеров.

| 
| 
| 
|

| 
| 
| 
|
| (а) | (б) | (в) | (г) |
Рисунок 5.6 – Искажения текста и результаты бинаризации:
(а) наклон текста вглубь; (б) шум на изображении; (в) грязь; (г) поворот символов
В идеальном случае достоверность распознавания шаблонным методом будет высокой, однако, в реальности на изображения символов оказывают влияние следующие факторы: поворот в плоскости, наклон вглубь, загрязнение и зашумление символов.
Порядок выполнения работы
1. Используя любую среду программирования (например, Visual Studio версии 2005 или старше и язык C/C++) и создайте новый проект.
2. С помощью встроенного в операционную систему Windows редактора Paint создайте 6 эталонных образов типа и шрифта в соответствии с вариантом. Фон белый, текст черный. Эталонный образ (буква) должен быть полностью вписан в изображение, причем с максимально возможным размером. Размер изображения может быть произвольным, например 40 на 30 пикселей по X и Y соответственно.
3. Напишите процедуру загрузки изображений в оперативную память.
4. Напишите процедуру обучения алгоритма распознавания для типа и размера шаблона в соответствии с вариантом. При обучении вся входная картинка условно разбивается на клетки и информация о заполнении клетки (черный цвет) записывается в качестве обучающей в массив данных.
5. Напишите процедуру распознавания, которая будет: а) приводить размеры входного изображения к эталонному (функция cvResize в OpenCV); б) получать информацию о заполнении клеток распознаваемого изображения; в) сравнивать информацию о заполнении клеток с эталонами и выдавать результат о величине совпадения с каждым эталоном.
6. Протестировать работу программы в соответствии с постановкой задачи.
7. Сделайте выводы о проделанной работе и составьте отчет.
|
|
|
8. Ответьте на контрольные вопросы.
|
|
|
