 |


Методология PLSA в области
|
|
|
|
Извлечения информации
Как мы уже отмечали выше, индивидуализация, или персонализация, интерфейса пользователя благодаря алгоритмам его идентификации позво-ляет учитывать неявные интересы АПР и использовать их в контексте текущего запроса. Тем самым еще на стадии обработки результатов запроса отсеивается большая часть нерелевантных документов.
В настоящее время применение моделей пользователя в адаптивных гипермедиасистемах вызывает большой интерес исследователей. Однако пока еще не предложено эффективных моделей, позволяющих описывать пользователя в режиме реального времени, а тем более производить корректировку модели в соответствии с новой информацией или изменением состояния окружения АГС.
Любая адаптивная гипермедиасистема - это прежде всего информационная система, т. е. система, представляющая информацию по некоторой предметной области в удобном для пользователя виде. Удобство представления обеспечивается введением в узлы АГС ссылок и, наряду с текстовой информацией, мультимедиаэлементов. В гипермедиасистемах выделяют два основных способа поиска информации: во-первых, это навигация по ссылкам, т. е. перемещение от одного узла системы к другому; во-вторых, это поисковые запросы, т. е. описание необходимой информации в виде строки запроса и активация механизма поиска. В этом случае в ответ на запрос может быть выдана совокупность страниц.
Далее мы будем рассматривать алгоритм непрерывной корректировки модели пользователя на основе текущих запросов в соответствии с методологией вероятностного латентно-семантического анализа (Probabilistic Latent Semantic Analysis, PLSA) [42].
Один из распространенных подходов к представлению документов (и запросов) при извлечении информации из Интернета основан на понятии модели векторного гиперпространства [57], которое при использовании методологии латентной семантической индексации заменяется представлением документа в латентном пространстве меньшей размерности [29].
|
|
|
Расширим понятие латентного семантического пространства с учетом текущих интересов пользователя, изменяющихся со временем, для чего должна быть предусмотрена возможность уменьшения или увеличения важности этих интересов. Введем понятие временного измерения в латентном семантическом пространстве и назовем результирующее пространство временны́м латентным семантическим пространством. Это пространство служит для отслеживания динамики изменения интересов (профиля) пользователя с течением времени. Координаты документа и запроса в новом латентном семантическом пространстве рассчитываются аналогично схеме, предложенной Т. Хофманом в работе [92]. Отличие заключается лишь в том, что запросы имеют временное измерение (текущий вес), начальное значение которого задается положительными величинами, убывающими с течением времени.
4.3.1. Частотная терминологическая модель запросов ЛПР
В настоящее время каждый пользователь Интернета имеет доступ ко всем источникам информации, представленным в нем. Однако качество поиска информации при всей ее доступности очень низкое. В существующих поисковых системах отсутствуют эффективные алгоритмы поиска релевантной информации, т. е. набора релевантных документов, отражающих сущность запроса. И в ответ на запрос такая система может выдать сколь угодно большое количество документов, либо отдаленно отражающих сферу интересов пользователя, либо вовсе не имеющих никакой связи с сутью запроса.
Разработка алгоритмов поиска релевантной информации базируется на двух научных направлениях: традиционное лингвистическое направление, пытающееся научить компьютер естественному языку, и направление, ориентированное на применение статистических методов. При поиске информации предлагается использовать подход PLSA, относящийся ко второму направлению.
|
|
|
В основе PLSA, как мы уже отмечали, лежит модель векторного пространства [44; 45]. При этом любой документ представляется как вектор частот появления определенных терминов в нем. В этом подходе отношения между документами и терминами выражены в виде матрицы смежности A, элементом wij которой является частота появления термина tj в документе di.
Обозначим через m количество проиндексированных терминов в коллекции документов d, а через n – количество самих документов. В общем случае элементом wij матрицы A является некоторый вес, поставленный в соответствие паре «документ–термин» (di, tj). После того как все веса заданы, матрица A становится отображением коллекции документов в векторном гиперпространстве. Таким образом, каждый документ можно представить как вектор весов терминов:
A  (4.1)
(4.1)
Методология PLSA основана на идее, предложенной в LSA (см. п. 3.2.3) и расширенной следующим образом. В PLSA на латентном семантическом пространстве вводится понятие латентного класса
z Î Z = { z 1, …, zk },
а также рассматриваются условные вероятности среди документов
d Î D = { d 1, …, dk }
и терминов
w Î W = { w 1, …, wk }.
Далее предположим, что распределение слов, принадлежащих данному классу, не зависит от документа и пары наблюдений «документ–термин» (d, w) независимы.
Распределение терминов в документе P (w | d) определяется выпуклой комбинацией факторов P (w | z) и P (z | d) и записывается следующим образом:
 (4.2)
(4.2)
Совместная вероятность документа и термина рассчитывается по соотношению
 (4.3)
(4.3)
Используя алгоритм максимизации математического ожидания (Expectation-Maximization (EM) Algorithm), который состоит из двух этапов: Е и М, оценим вероятности P (w | z) и P (z | d), максимизируя логарифми-ческую функцию правдоподобия:
 (4.4)
(4.4)
где n (d, w) – частота термина в документе, т. е. количество появлений термина w в документе d.
Вероятность того, что появление термина w в документе d объясняется принадлежностью их к классу z, на этапе E оценивается как
|
|
|
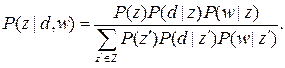 (4.5)
(4.5)
На этапе М происходит переоценка вероятностей:

 (4.6)
(4.6)

В работе [101] Т. Хофман предложил обобщенную модель для оценивания условной вероятности, которую он назвал ослабленной процедурой максимизации математического ожидания (Tempered Expectation Maximization, TEM).
В этой модели на этапе E в оценку условной вероятности вносится регуляризационный параметр b:
 (4.7)
(4.7)
Согласно (4.2) любая условная вероятность P (w | d) может быть аппро-ксимирована полиномом, представляющим собой выпуклую комбинацию условных вероятностей P (w | z). Весовые коэффициенты P (z | d) геометрически могут быть интерпретированы как координаты документа в подпространстве, определяемом как латентное семантическое пространство [91].
Именно такое пространство несет в себе основную смысловую нагрузку и формируется по близости расположения точек.
4.3.2. Динамический профиль ЛПР
в информационно-управляющих системах
А теперь рассмотрим новую схему моделирования интересов пользователя, основанную на инициализации начального профиля и его последовательной корректировке в процессе работы.
Как уже отмечалось, для того чтобы следить и непрерывно анализировать возможные изменения интересов пользователя, в латентное семантическое пространство необходимо ввести понятие временного измерения, рассматривая тем самым уже не само латентное семантическое пространство, а его модификацию – временное латентное семантическое пространство [103]. Каждое измерение такого векторного пространства (за исключением временно́го) представляет собой условные вероятности при заданном классе P (· | z), документы являются векторами с весовыми коэффициентами (координатами) P (z | d), а временное измерение полагаем равным нулю.
Запросы, как и сами документы, могут быть векторами во временном латентном семантическом пространстве. Кроме весов P (z | Q) у них есть дополнительное (временное) измерение – текущий вес, первоначально равный некоторой положительной величине, уменьшающейся с течением времени исходя из предположения о падении интереса пользователя к определенной тематике при отсутствии ее фигурирования в запросах продолжительное время. Если же пользователь инициирует запрос, связанный с определенной категорией из его текущего профиля, то вес данной категории может быть либо стабилизирован на определенное время, либо увеличен.
|
|
|
Согласно теории латентного семантического пространства, запрос, состоящий из терминов, проецируется в латентное семантическое пространство [92]. Таким образом, гиперповерхность Si, образованная запросом Qi, является пересечением вероятностных поверхностей всех классов, введенных на латентном семантическом пространстве, в которых с определенной вероятностью фигурирует данный термин:
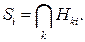
Для реализации запроса используется алгоритм адаптивной коррекции профиля, основанный на неявной обратной связи с пользователем, которая реализуется на основе истории его запросов. На вход алгоритма поступает запрос пользователя, на выходе будет получена одна или более троек (триплетов) вида (Ci, Wi, a i), где Ci – категория интересов; Wi – текущий вес; a i – уровень изменчивости (смысл данной величины состоит в том, чтобы отразить, насколько изменяются интересы пользователя в рамках текущего запроса по отношению к прошлым запросам).
Итак, профиль пользователя представляет собой набор троек. При этом он организован таким образом, что интересы пользователя разделены на два типа: краткосрочные (краткосрочный профиль) и долгосрочные (долгосрочный профиль). Как правило, емкость долгосрочного профиля больше емкости краткосрочного. При этом считается, что тройки, в которых величина текущего веса положительная, относятся к краткосрочному профилю, если вес отрицательный, то к долгосрочному профилю. Текущий вес для троек, находящихся в краткосрочном профиле, уменьшается линейно, тогда как для троек, находящихся в долгосрочном профиле, снижение весов экспоненциальное.
Структуру профиля пользователя можно представить в табличном виде (рис. 4.2).
| Кино | Музыка | Квантовая физика | Спорт | Категория |
| Текущий вес | ||||
| 0.60 | 0.45 | 0.20 | 0.15 | Уровень изменчивости |
Рис. 4.2. Краткосрочный профиль пользователя
Формально профиль в текущий момент i описывается следующим образом:
Pr i = {(Cj, Wj, a j) i, j = 1, k }. (4.8)
При этом
Pr i = Pr Ri È Pr Li, (4.9)
где Pr Ri = {(Cj, Wj, a j) i | " Wj ³ 0, j = 1, k } – краткосрочный профиль; Pr Li = {(Cj, Wj, a j) i | " Wj < 0, j = 1, k } – долгосрочный профиль.
Уровень изменчивости a i рассчитывается как близость двух последовательных запросов Qi и Qi –1, представленных в пространстве частот их терминов:
|
|
|
 (4.10)
(4.10)
где 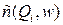 – взвешенные частоты терминов.
– взвешенные частоты терминов.
На основании приведенных выше расчетов можно сделать вывод о том, что емкость долгосрочного профиля действительно больше емкости краткосрочного.
4.3.3. Алгоритм непрерывной корректировки профиля ЛПР
При использовании алгоритма непрерывной корректировки профиля ЛПР предполагается, что существует некоторое хранилище предыдущих запросов пользователя. В текущий момент времени i пользователь вводит новый запрос, который после соответствующей обработки помещается в хранилище запросов. Обновленное (или дополненное) в момент времени i текущим запросом хранилище запросов будем обозначать Qi.
Запрос перед передачей алгоритму обрабатывается с целью выделения ключевых терминов. Далее производится пересчет взвешенных частот терминов в хранилище запросов Qi с учетом нового запроса. Когда пользователь вводит очередной запрос, ключевым словам (терминам) данного запроса назначаются наибольшие веса. При поступлении запроса в хранилище запросов происходит проверка на наличие в этом хранилище терминов, присущих текущему запросу. Если термин встречается впервые, то при его занесении в хранилище вес остается без изменений, если же такой термин уже существует (это означает, что пользователь уже когда-то использовал запрос, включающий данный термин), то производится пересчет весового коэффициента данного термина. В результате происходит нормирование весовых коэффициентов. Категории интересов Ci для включения в текущий профиль извлекаются из хранилища посредством использования методологии PLSA.
Представим пошаговый алгоритм непрерывной корректировки профиля пользователя.
1. Инициализировать хранилище запросов Qi = { w 1 i, w 2 i, …, wki }, где wki – термины хранилища запросов, k = 1, …, M.
2. Выделить набор ключевых терминов текущего запроса.
3. Скорректировать весовые коэффициенты терминов и произвести их нормировку с учетом нового запроса.
4. Рассчитать уровень изменчивости a i.
5. Рассчитать условные вероятности классов, используя процедуру TEM следующим образом:

6. Рассчитать вероятность категории Ci для заданного класса латентного семантического пространства:

7. Рассчитать вероятность включения категории Ci для текущего состояния хранилища запросов Qi.
8. Занести категорию в профиль пользователя. Для этого включить соответствующую тройку (Ci, Wi, a i) в профиль.
9. Если уровень изменчивости a i > a0 (где a0 – заданная величина), то увеличить текущий вес категории Ci на величину
D Wi: Wi = Wi + D Wi.
10. Отсортировать последовательность троек (Ci, Wi, a i) в профиле по порядку убывания веса Wi.
11. Сохранить получившийся профиль как текущий.
Эффективность работы алгоритма непрерывной корректировки профиля пользователя была оценена на сравнительно небольших тестовых наборах данных, но и это позволило отразить реальную ситуацию в корпоративных информационно-управляющих системах.
|
|
|
