 |


Оценка качества поисковых алгоритмов
|
|
|
|
Для сравнения эффективности методов решения задач информационного поиска необходимо определить, какие критерии будут использованы для оценки эффективности.
Можно выделить, как минимум, два критерия:
- качество результатов поиска, включающее точность (Precision) и полноту (Recall);
- вычислительная производительность.
В рамках данной монографии наибольший интерес вызывает первый критерий, наглядное представление о котором дает рис. 3.5.
Сформулируем определение точности и полноты: точность – это доля истинно релевантных документов в общем числе найденных, а полнота – доля обнаруженных истинно релевантных документов по сравнению с общим числом релевантных документов:
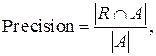 (3.25)
(3.25)
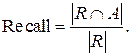 (3.26)
(3.26)
Необходимо также отметить, что точность и полнота – это критерии общего назначения. Для решения конкретной задачи информационного поиска лучше использовать специализированные критерии, отражающие специфику проблемы [53].

Рис. 3.5. Точность и полнота результата запроса:
A – результат работы метода поиска (поисковой системы);
С – общий объем документов, участвующих в эксперименте;
R – множество документов, релевантных
предметной области запроса
Чаще всего для оценки качества метода используют тестовые наборы данных, которые условно могут быть приближены к объемам данных, содержащихся в Интернете, например тестовые коллекции TREC[1], предназначенные для сравнения эффективности разных методов решения информационного поиска [54].
Коллекции TREC, кроме самих наборов, также содержат наборы тестовых запросов, а также идеальные таблицы релевантности документов запросам, при создании которых используются знания экспертов по тематике запросов. Наборы данных TREC слишком велики для ручной оценки релевантности каждого документа запросу, поэтому для каждого запроса сначала полуавтоматическим способом отбирается относительно небольшое множество документов, которые в дальнейшем анализируются экспертами. Для такого отбора обычно используются эвристики, основанные, например, на доступной для документов метаинформации.
|
|
|
В Интернете существует еще одна тестовая коллекция – набор данных Reuters-21578. Эта коллекция содержит документы преимущественно экономической тематики, полученные от одноименного агентства новостей. Как и наборы данных TREC, эта коллекция содержит множество тестовых запросов и идеальные ответы для них. Одной из отличительных особенностей этой коллекции является значительный разброс в размерах документов, что осложняет задачу поиска информации [54].
Таким образом, можно сделать вывод, что при разработке новых алгоритмов мультилингвистического поиска информации, обеспечивающих заданный уровень релевантности электронных документов, прежде всего учитывается критерий качества результатов поиска.
* * *
В заключение отметим, что в настоящее время разработано множество моделей и алгоритмов поиска информации в Интернете, применяемых крупными поисковыми системами. Однако эти разработки в работе метапоисковых систем не используются, что связано со спецификой организации поиска в этих системах, а именно с обработкой результатов запроса с нескольких поисковых сайтов.
В монографии предложены модели поиска и ранжирования информации, получаемой из сети Интернет для формирования частотных мультилингвистических словарей, а также модифицированная модель определения релевантности документа запрашиваемой предметной области с использованием мультилингвистического частотного словаря. Эта модель позволяет ускорить работу метопоисковых систем и совершенствовать процесс разработки новых словарей для мультилингвистической адаптивно-обучающей технологии.
|
|
|
Также представлена новая модель мультилингвистического поиска данных для подготовки и принятия решения в КИУС, отличающаяся от известных моделей процедурами формирования запросов и обработкой отклика, которые базируются на узкоспециализированных многоязычных частотных словарях.

|
|
|
