 |


Марковские случайные процессы с непрерывным временем
|
|
|
|
Итак, снова модель марковского процесса представим в виде графа, в котором состояния (вершины) связаны между собой связями (переходами из i -го состояния в j -е состояние), см. рис. 33.10.
| |
| Рис. 33.10. Пример графа марковского процесса с непрерывным временем |

Теперь каждый переход характеризуется плотностью вероятности перехода λij. По определению:

При этом плотность понимают как распределение вероятности во времени.
Переход из i -го состояния в j -е происходит в случайные моменты времени, которые определяются интенсивностью перехода λij.
К интенсивности переходов (здесь это понятие совпадает по смыслу с распределением плотности вероятности по времени t) переходят, когда процесс непрерывный, то есть, распределен во времени.
С интенсивностью потока (а переходы — это поток событий) мы уже научились работать влекции 28. Зная интенсивность λij появления событий, порождаемых потоком, можно сымитировать случайный интервал между двумя событиями в этом потоке.

где τij — интервал времени между нахождением системы в i -ом и j -ом состоянии.
Далее, очевидно, система из любого i -го состояния может перейти в одно из нескольких состояний j, j + 1, j + 2, …, связанных с ним переходами λij, λij + 1, λij + 2, ….
В j -е состояние она перейдет через τij; в (j + 1)-е состояние она перейдет через τij + 1; в (j + 2)-е состояние она перейдет через τij + 2 и т. д.
Ясно, что система может перейти из i -го состояния только в одно из этих состояний, причем в то, переход в которое наступит раньше.
Поэтому из последовательности времен: τij, τij + 1, τij + 2 и т. д. надо выбрать минимальное и определить индекс j, указывающий, в какое именно состояние произойдет переход.
|
|
|
Пример. Моделирование работы станка. Промоделируем работу станка (см. рис. 33.10), который может находиться в следующих состояниях: S 0 — станок исправен, свободен (простой); S 1 — станок исправен, занят (обработка); S 2 — станок исправен, замена инструмента (переналадка) λ 02 < λ 21; S 3 — станок неисправен, идет ремонт λ 13 < λ 30.
Зададим значения параметров λ, используя экспериментальные данные, получаемые в производственных условиях: λ 01 — поток на обработку (без переналадки); λ 10 — поток обслуживания; λ 13 — поток отказов оборудования; λ 30 — поток восстановлений.
Реализация будет иметь следующий вид (см. рис. 33.11).
| |
| Рис. 33.11. Пример моделирования непрерывного марковского процесса с визуализацией на временной диаграмме (желтым цветом указаны запрещенные, синим — реализовавшиеся состояния) |

В частности, из рис. 33.11 видно, что реализовавшаяся цепь выглядит так: S 0— S 1— S 0—…Переходы произошли в следующие моменты времени: T 0— T 1— T 2— T 3—…, где T 0 = 0, T 1 = τ01, T 2 = τ01 + τ10.
Задача. Поскольку модель строят для того, чтобы на ней можно было решить задачу, ответ которой до этого был для нас совсем не очевиден (см. лекцию 01), то сформулируем такую задачу к данному примеру. Определить долю времени в течение суток, которую занимает простой станка (посчитать по рисунку) T ср = (T + T + T + T)/ N.
Алгоритм имитации будет иметь следующий вид (см. рис. 33.12).
| |
| Рис. 33.12. Блок-схема алгоритма моделирования непрерывного марковского процесса на примере имитации работы станка |

Очень часто аппарат марковских процессов используется при моделировании компьютерных игр, действий компьютерных героев.
Фиксация и обработка статистических
результатов
В лекции 21 мы подробно познакомились со схемой статистического компьютерного эксперимента. В лекциях 21—26 мы рассмотрели практическую реализацию всех основных блоков (см. рис. 21.3) этой схемы. Сейчас важно научиться организовывать работу последних двух блоков — блок вычисления статистических характеристик (БВСХ) и блок оценки достоверности статистических результатов (БОД).
|
|
|
Итак, рассмотрим, как следует фиксировать статистические величины в результате эксперимента, чтобы получить надежную информацию о свойствах моделируемого объекта. Напомним, что обобщенными характеристиками случайного процесса или явления являются средние величины.
Вычисление средних
Вычисление средних величин во время эксперимента, который многократно повторяется, а результат его усредняется, может быть организовано несколькими способами:
- вся статистика вычисляется в конце;
- вся статистика вычисляется в процессе вычисления (по рекурсивным соотношениям);
- вся статистика вычисляется в классовых интервалах (этот метод совмещает универсальность первого метода и экономичность второго).
Способ 1. Вычисление всей статистики в конце. Для этого в процессе эксперимента значения Xi выходной (изучаемой) случайной величины X накапливается в массиве данных. После окончания эксперимента подсчитывается математическое ожидание (среднее) X и дисперсия D (характерный разброс величин относительно этого математического ожидания).


Часто используют среднеквадратичное отклонение σ = sqrt(D).
Заметим, что недостатком метода является неэффективное использование памяти, так как приходится накапливать и сохранять большое количество значений выходной величины в течение всего эксперимента, который может быть весьма продолжительным.
Второй минус заключается в том, что приходится дважды считывать массив Xi, так как воспользоваться формулой (2) в том виде, как она здесь записана, мы можем, только просчитав формулу (1) (от 1 до n), а потом еще раз прогнав для формулы (2) массив Xi.
Положительным моментом является сохранение всего массива данных, что дает возможность более подробного его изучения в дальнейшем при необходимости расследования тех или иных эффектов и результатов.
Способ 2. Вычисление всей статистики в процессе вычисления (по рекурсивным соотношениям). Этот способ предусматривает возможность хранить только текущее значение математического ожидания Xi и дисперсии Di, подправляемое на каждой итерации. Это избавляет нас от необходимости постоянного хранения всего массива экспериментальных данных. Каждое новое данное Xi учитывается в сумме с весовым коэффициентом — чем более слагаемых i накоплено в сумме Xi, тем более ее значение важно по отношению к очередной поправке Xi, поэтому соотношение весовых коэффициентов i /(i + 1): 1/(i + 1).
|
|
|
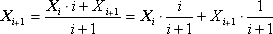

где Xi — очередное значение экспериментальной выходной величины.
Способ 3. Вычисление всей статистики в классовых интервалах. Этот способ предполагает, что в массив будут накапливать не все значения Xi, а только по значимым интервалам, в которых распределена случайная выходная величина Xi. Общий интервал изменения Xi разбивается на m подинтервалов, в каждом из которых фиксируется количество ni, которое показывает, сколько раз Xi приняло значение из i -го интервала. При небольшом количестве интервалов (m ≈ 1) мы получаем способ 1, при количестве интервалов m = n мы получаем способ 2. В случае 1 < m < n получаем среднее решение — компромисс между занимаемой памятью и информативностью массива выходных данных.


|
|
|
