 |


Отношения, схема базы данных
|
|
|
|
Основные функции СУБД
1. Администрирование базы данных.
СУБД имеют развитые средства администрирования базы данных (определение доступа к базе, ее архивация). В связи с тем, что базы данных приникают сегодня во многие сферы деятельности человека, появилась новая профессия – администратор базы данных, человек, отвечающий за проектирование, создание, использование и сопровождение базы данных. В процессе эксплуатации БД администратор обычно следит за ее функционированием, обеспечивает защиту от несанкционированного доступа к хранимым данным, вносит изменения в структуру базы, контролирует достоверность информации в ней.
2. Непосредственное управление данными во внешней памяти.
Эта функция предоставляет пользователю возможность выполнения основных операций с данными – хранение, извлечение и обновление информации. Она включает в себя обеспечение необходимых структур внешней памяти как для хранения данных, непосредственно входящих в БД, так и для служебных целей, например, для убыстрения доступа к данным. СУБД поддерживает собственную систему именования объектов БД.
3. Управление буферами оперативной памяти.
СУБД обычно работают с БД значительного размера; по крайней мере этот размер обычно существенно больше доступного объема оперативной памяти. Понятно, что если при обращении к любому элементу данных будет производиться обмен с внешней памятью, то вся система будет работать со скоростью устройства внешней памяти. Практически единственным способом реального увеличения этой скорости является буферизация данных в оперативной памяти. Однако этого недостаточно для целей СУБД. Поэтому в развитых СУБД поддерживается собственный набор буферов оперативной памяти.
|
|
|
4. Управление транзакциями
Транзакция – это последовательность операций над БД, которые рассматриваются СУБД как единое целое и позволяют добавлять, удалять или обновлять сведения о некотором объекте в базе (по существу это некоторый программный код, написанный на одном из языков управления данными). Либо транзакция успешно выполняется, и СУБД фиксирует изменения БД, произведенные этой транзакцией, либо ни одно из этих изменений никак не отражается на состоянии БД. Например, если в результате транзакции произошел сбой компьютера, база данных попадает в противоречивое положение – некоторые изменения уже внесены, остальные нет. Транзакция позволяет вернуть базу в первоначальное непротиворечивое состояние (отменить все выполненные изменения).
5. Журнализация
Одним из основных требований к СУБД является надежность хранения данных во внешней памяти. Под надежностью хранения понимается то, что СУБД должна быть в состоянии восстановить последнее состояние БД после любого аппаратного или программного сбоя (аварийное выключение питания, аварийное завершение работы СУБД или аварийное завершение пользовательской программы). Понятно, что в любом случае для восстановления БД нужно располагать некоторой дополнительной информацией. Наиболее распространенным методом поддержания надежности хранения является ведение журнала изменений БД.
Журнал – это особая часть БД, недоступная пользователям и поддерживаемая с особой тщательностью (иногда поддерживаются две копии журнала, располагаемые на разных физических дисках), в которую поступают записи обо всех изменениях основной части БД. Изменения БД журнализуются следующим образом: запись в журнале соответствует некоторой операции изменения БД (например, операции удаления строки из таблицы реляционной БД). С помощью журнала можно решить все проблемы восстановления БД после любого сбоя.
|
|
|
6. Поддержка языков БД
СУБД включает язык определения данных, с помощью которого можно определить структуру базы, тип данных в ней, указать ограничения целостности (это язык, с помощью которого задаются различные имена, свойства объектов). Кроме того, СУБД позволяет вставлять, удалять, обновлять и извлекать информацию из базы данных посредством языка управления данными – языка запросов, который позволяет выполнять различные действия с данными, осуществлять их поиск и выборку. Он содержит набор различных операторов (заносить данные, удалять, модифицировать, выбирать и т.д.). Процесс извлечения данных и их обработка скрыты от пользователя.
Стандартным языком наиболее распространенных в настоящее время СУБД является язык SQL (Structured Query Language). Он имеет сразу два компонента: язык определения данных и язык управления данными. Кроме того, одним из языков управления данными является язык QBE – язык запросов по образцу. Подробно о реализаций функций СУБД с помощью языка SQL будет рассказано на отдельных лекциях, посвященных языку SQL.
Классификация СУБД
1. По степени универсальности все СУБД делятся на СУБД общего назначения и специализированные СУБД. СУБД общего назначения не ориентируются на информационные потребности конкретной группы пользователей. Они могут быть использованы для создания и использования баз данных в любой предметной области (документоведение, образование, риэлтерская деятельность и т.д.). К ним относят MS Access, MS FoxPro. Однако в некоторых случаях доступные СУБД общего назначения не позволяют добиться требуемых результатов. С этой целью используют специализированные СУБД, которые позволяют осуществить работу с данными, описывающими информационные потребности узкого круга пользователе. К таким СУБД можно отнести Lotus.
2. По функциональности все СУБД делятся на полнофункциональные СУБД, серверы баз данных, клиенты баз данных. Полнофункциональные СУБД представляют собой традиционные СУБД, которые изначально создавались для больших ЭВМ, затем для ПЭВМ. Они являются наиболее многочисленными и мощными по своим возможностям. К ним относят MS Access, MS FoxPro, Paradox, dBase IV. Такие СУБД имеют развитый интерфейс, для создания отчетов и запросов используются мастера. Многие СУБД имеют встроенные языки программирования для профессиональных разработчиков. Серверы БД предназначены для организации центров обработки данных в локальной (или глобальной) сети. Они обладают скудным интерфейсом, однако их основное назначение – организация хранения баз данных удаленных пользователей, защита данных от несанкционированного доступа, ограничение доступа к данным, возможность одновременной работы с базой нескольким пользователям. Данная группа менее многочисленна, однако их количество постоянно растет за счет того, что сегодня практически в любой организации, на любом предприятии все компьютеры соединяются в локальную сеть. Следовательно возникает необходимость организации централизованного хранения базы и создания удаленного многопользовательского доступа к ней. Примером такой СУБД является СУБД MS SQL Server. В роли клиентов баз данных могут использоваться любые полнофункциональные СУБД. здесь их роль сводится к тому, чтобы обеспечить доступ к данным, их просмотр, поиск и выборку.
|
|
|
3. По характеру использования СУБД делят на персональные и многопользовательские.
Персональные СУБД обычно обеспечивают возможность создания персональных баз данных. Такие СУБД могут выступать в роли клиентов БД. К ним относят MS Access, MS FoxPro, Paradox, Clipper. Многопользовательские СУБД включают в себя сервер базы данных и клиентскую часть, могут работать в с различными операционными системами, с различными типами ЭВМ. К таким СУБд относят Oracle, Informix.
Компоненты среды СУБД
В СУБД можно выделить несколько основных компонентов: данные, пользователи, аппаратное обеспечение, программное обеспечение, процедуры.
Данные являются наиболее важным компонентом.
Для хранения данных и функционирования базы необходимо аппаратное обеспечение – набор физических устройств (ПК, сеть), на которых существует база и СУБД.
Для того, чтобы можно было работать с данными, кроме аппаратного обеспечения необходимо иметь операционную систему, сетевое программное обеспечение, программное обеспечение самой СУБД и прикладные программы-приложения. Прикладные программы пишутся программистами на одном из языков высокого уровня (Pascal, C, VB) для нужд конкретной организации. Такие программы используют средства СУБД для обращения к данным в базе и их обработки, создавая различные свойственные данной организации формы, отчеты.
|
|
|
Среди пользователей базой данной можно выделить 4 категории лиц: администраторы данных, администраторы баз данных, разработчики баз данных, непосредственно сами пользователи.
Администраторы данных работают с данными с самого начала процесса ее создания. Отвечают за сбор информационных потребностей данной организации, проектирование будущей базы.
Администратор базы данных отвечает за физическую реализацию базы, обеспечение безопасности, сопровождает базу в процессе ее эксплуатации, следит за достоверностью информации в базе и т.д.
Разработчики баз данных – категория лиц, которые работают с ней только в процессе ее разработки по проекту, созданному администратором данных.
Пользователи – это конечные пользователи, ради которых база проектировалась, создавалась и будет работать. Их часто называют клиентами.
СУБД является достаточно сложным видом программного обеспечения, поэтому в составе СУБД можно выделить ряд программных компонентов:
– ядро СУБД, которое отвечает за управление данными во внешней памяти, управление буферами оперативной памяти, транзакциями, журнализацию. Это главная часть СУБД. Ядро обладает собственным интерфейсом, недоступным пользователю напрямую.
– компилятор языка БД (обычно SQL), предназначенный для работы с данными.
– набор утилит.
Лекция 2. Модели данных
Первые СУБД использовали иерархическую модель данных. Типичным представителем СУБД, поддерживаемых данный вид моделей (наиболее известным и распространенным), является Information Management System (IMS) фирмы IBM. Первая версия появилась в 1968 г. и была создана для поддержки лунного проекта «Аполлон» (управление огромного количества деталей, иерархически связанных между собой).
Структурная часть
Основными информационными единицами являются сегмент, поле дерево. Поле данных – наименьшая неделимая поименованная информационная единица, сегмент (запись) образуется из конкретных значений полей данных, тип записи – набор взаимосвязанных сегментов одного уровня, дерево – набор записей данного типа (таблица).
Иерархическая модель базируется на теории графов и представляет собой древовидный граф. Вершины графа – деревья базы данных, дуги, соединяющие вершины – связь «предок – потомок». Иерархическая модель из-за своего внешнего сходства часто называют деревом или набором деревьев. В вершине иерархии лежит корень дерева, ответвления – листья дерева.
|
|
|
Между типами записи поддерживаются связи.
База данных с такой схемой могла бы выглядеть следующим образом:
Управляющая часть
Примерами типичных операторов манипулирования иерархически организованными данными могут быть следующие:
· Найти указанное дерево БД (например, отдел 310);
· Перейти от одного дерева к другому;
· Перейти от одной записи к другой внутри дерева (например, от отдела - к первому сотруднику);
· Перейти от одной записи к другой в порядке обхода иерархии;
· Вставить новую запись в указанную позицию;
· Удалить текущую запись.
В иерархической модели используются два метода доступа к данным: прямой порядок обхода дерева и обратный порядок. Прямой обход осуществляется сверху вниз, начинается с корня и постепенно делается обход всех предков в направлении сверху-вниз, слева-направо. Обратный подход начинается с доступа к самым нижним сегментам с постепенным переходом снизу-вверх, слева-направо.
Ограничения целостности
Целостность связи поддерживается между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя.
Кроме того, иерархическая модель обладает следующими свойствами:
1. каждый потомок имеет только одного предка;
2. предок может не иметь потомков.
К достоинствам иерархической модели данных относятся эффективное использование памяти компьютера и высокие временные показатели выполнения операций над данными. Недостатком иерархической модели является ее громоздкость для обработки информации с достаточно сложными связями.
Примеры иерархических СУБД: Ока, ИНЭС, МИРИС, Data Edge
Сетевая модель
Сети – естественный способ представления реальных отношений между объектами. Сетевая модель также опирается на теорию графов.
Появились в 70-х годах XX века. Типичными представителями являются СУБД Integrated Database Management System (IDMS) компании Cullinet Software, Inc. и Integrated Data Store (IDS) фирмы General Electric.
Сетевой подход к организации данных является расширением иерархического. В иерархических структурах запись-потомок должна иметь в точности одного предка; в сетевой структуре данных потомок может иметь любое число предков.
Структурная часть
Основными элементами сетевой базы данных являются элемент данных, агрегат данных, запись, набор.
Элемент данных – наименьшая неделимая поименованная информационная единица, доступная пользователю. Элемент данных может иметь свой тип. Агрегат данных – поименованная совокупность элементов данных внутри записи (дата – день, месяц, год).
Запись – поименованная структура, содержащая элементы данных (запись в реляционной таблице).
Тип записей – это совокупность логически связанных экземпляров записей, моделирует некоторый класс объектов реального мира.
Набор – это поименованная двухуровневая иерархическая структура, которая выражает связи между двумя типами записей (один к одному, один ко многим).
На формирование типов связи не накладываются особые ограничения; возможны, например, следующие ситуации:
– Данный тип записи может быть предком для любого числа связей.
– Данный тип записи может быть потомком в любом числе связей.
– Может существовать любое число связей с одним и тем же типом записи предка и одним и тем же типом записи потомка.
– Типы записи X и Y могут быть предком и потомком в одной связи и потомком и предком - в другой.
– Предок и потомок могут быть одного типа записи.
– Между двумя типами записей может быть любое количество наборов (преподаватель может не только преподавать, и быть куратором этой группы).
Простой пример сетевой схемы БД:
Таким образом, сетевая база данных – поименованная совокупность записей различного типа и наборов, содержащих связи между ними.
Управляющая часть
Примерный набор операций может быть следующим:
– Найти конкретную запись в наборе однотипных записей (инженера Сидорова);
– Перейти от предка к первому потомку по некоторой связи (к первому сотруднику отдела 310);
– Перейти к следующему потомку в некоторой связи (от Сидорова к Иванову);
– Перейти от потомка к предку по некоторой связи (найти отдел Сидорова);
– Создать новую запись;
– Уничтожить запись;
– Модифицировать запись;
– Включить в связь;
– Исключить из связи;
– Переставить в другую связь и т.д.
Ограничения целостности
Достоинством сетевой модели данных является возможность эффективной реализации по показателям затрат памяти и оперативности. В сравнении с иерархической моделью сетевая модель предоставляет большие возможности по созданию и моделированию различных связей между сущностями реального мира (предметной области). Недостатком сетевой модели является высокая сложность и жесткость схемы данных, сложность для понимания и выполнения обработки информации обычным пользователем.
Реляционная модель данных
Сложность практического использования иерархических и сетевых СУБД, желание пользователей оперировать более крупными объектами, чем элементы данных заставили искать иные способы представления данных и послужило причиной возникновения новой структуры данных – реляционной (табличной). Работа с таблицами понятна и привычна каждому пользователю. Создателем реляционной модели является математик, сотрудник фирмы IBM Э.Ф. Кодд (1970 г.). Он же ввел два языка манипулирования данными SQL и QBE.
Э.Кодд предложил использовать для обработки данных аппарат теории множеств (объединение, пересечение, разность). Он показал, что любое представление данных сводится к совокупности двумерных таблиц.
Структурная часть
Реляционная база данных представляет собой набор таблиц (которые Кодд назвал отношениями), каждая из которых имеет уникальное имя и состоит из строк – записей (кортежей) и столбцов – полей (атрибутов). Каждая запись представляет объект реального мира. Свойства объекта, его характеристики определяются значениями полей. Каждое поле имеет имя, тип и размер данных, хранимых в нем. Имена полей вынесены в шапку таблицы.
Тип данных
Понятие тип данных в реляционной модели данных полностью адекватно понятию типа данных в языках программирования. Обычно в современных реляционных БД допускается хранение символьных, числовых данных, битовых строк, специализированных числовых данных (таких как "деньги"), а также специальных "темпоральных" данных (дата, время, временной интервал).
Наименьшая единица данных реляционной модели – это отдельное атомарное (неразложимое) для данной модели значение данных. Так, в одной предметной области фамилия, имя и отчество могут рассматриваться как единое значение, а в другой – как три различных значения.
Доменом называется множество значений данного типа (например, множество названий населенных пунктов).
Домены весьма важные компоненты реляционной модели. Смысл доменов состоит в следующем. Если значения двух атрибутов берутся из одного и того же домена, то, вероятно, имеют смысл сравнения, использующие эти два атрибута (например, для организации транзитного рейса можно дать запрос "Выдать рейсы, в которых время вылета из Москвы в Сочи больше времени прибытия из Архангельска в Москву"). Если же значения двух атрибутов берутся из различных доменов, то их сравнение, вероятно, лишено смысла: стоит ли сравнивать номер рейса со стоимостью билета?
Кортеж, отношение
Отношением является таблица, заголовком которой является схема отношения, а строками - кортежи; имена атрибутов именуют столбцы этой таблицы. Отношения используются для представления объектов окружающего мира и представления связей между объектами.
Реляционная база данных - это конечный набор отношений.
Каждое отношение обладает хотя бы одним потенциальным ключом, поскольку по меньшей мере комбинация всех его атрибутов удовлетворяет условию уникальности. Один из потенциальных ключей (выбранный произвольным образом) принимается за его первичный ключ. Остальные возможные ключи, если они есть, называются альтернативными ключами.
Отношения, схема базы данных
Схема отношения - это именованное множество пар {имя атрибута, имя домена (или типа)}.
Схемой реляционной базы данных называется набор заголовков отношений, входящих в базу данных.
Ограничение целостности
В целостной части реляционной модели данных фиксируются два базовых требования целостности, которые должны поддерживаться в любой реляционной СУБД. Первое требование называется требованием целостности сущностей. Объекту или сущности реального мира в реляционных БД соответствуют кортежи отношений. Конкретно требование состоит в том, что любой кортеж любого отношения отличим от любого другого кортежа этого отношения, т.е. другими словами, любое отношение должно обладать первичным ключом.
Второе требование называется требованием целостности по ссылкам и является несколько более сложным. Очевидно, сложные сущности реального мира представляются в реляционной БД в виде нескольких кортежей нескольких отношений. Например, представим, что нам требуется представить в реляционной базе данных сущность ОТДЕЛ с атрибутами ОТД_НОМЕР (номер отдела), ОТД_КОЛ (количество сотрудников) и ОТД_СОТР (набор сотрудников отдела). Для каждого сотрудника нужно хранить СОТР_НОМЕР (номер сотрудника), СОТР_ИМЯ (имя сотрудника) и СОТР_ЗАРП (заработная плата сотрудника). Как мы вскоре увидим, при правильном проектировании соответствующей БД в ней появятся два отношения: ОТДЕЛЫ (ОТД_НОМЕР, ОТД_КОЛ) (первичный ключ - ОТД_НОМЕР) и СОТРУДНИКИ (СОТР_НОМЕР, СОТР_ИМЯ, СОТР_ЗАРП, СОТР_ОТД_НОМ) (первичный ключ - СОТР_НОМЕР).
Как видно, атрибут СОТР_ОТД_НОМ появляется в отношении СОТРУДНИКИ не потому, что номер отдела является собственным свойством сотрудника, а лишь для того, чтобы иметь возможность восстановить при необходимости полную сущность ОТДЕЛ. Значение атрибута СОТР_ОТД_НОМ в любом кортеже отношения СОТРУДНИКИ должно соответствовать значению атрибута ОТД_НОМ в некотором кортеже отношения ОТДЕЛЫ. Атрибут такого рода называется внешним ключом, поскольку его значения однозначно характеризуют сущности, представленные кортежами некоторого другого отношения (т.е. задают значения их первичного ключа). Говорят, что отношение, в котором определен внешний ключ, ссылается на соответствующее отношение, в котором такой же атрибут является первичным ключом.
Требование целостности по ссылкам, или требование внешнего ключа состоит в том, что для каждого значения внешнего ключа, должен найтись кортеж с таким же значением первичного ключа, либо значение внешнего ключа должно быть неопределенным (т.е. ни на что не указывать). Для нашего примера это означает, что если для сотрудника указан номер отдела, то этот отдел должен существовать.
Ограничения целостности сущности и по ссылкам должны поддерживаться СУБД. Для соблюдения целостности сущности достаточно гарантировать отсутствие в любом отношении кортежей с одним и тем же значением первичного ключа. С целостностью по ссылкам дела обстоят несколько более сложно.
Понятно, что при обновлении ссылающегося отношения (вставке новых кортежей или модификации значения внешнего ключа в существующих кортежах) достаточно следить за тем, чтобы не появлялись некорректные значения внешнего ключа. Но как быть при удалении кортежа из отношения, на которое ведет ссылка?
Здесь существуют три подхода, каждый из которых поддерживает целостность по ссылкам. Первый подход заключается в том, что запрещается производить удаление кортежа, на который существуют ссылки (т.е. сначала нужно либо удалить ссылающиеся кортежи, либо соответствующим образом изменить значения их внешнего ключа). При втором подходе при удалении кортежа, на который имеются ссылки, во всех ссылающихся кортежах значение внешнего ключа автоматически становится неопределенным. Наконец, третий подход (каскадное удаление) состоит в том, что при удалении кортежа из отношения, на которое ведет ссылка, из ссылающегося отношения автоматически удаляются все ссылающиеся кортежи.
В развитых реляционных СУБД обычно можно выбрать способ поддержания целостности по ссылкам для каждой отдельной ситуации определения внешнего ключа. Конечно, для принятия такого решения необходимо анализировать требования конкретной прикладной области.
Управляющая часть
Для управления реляционной базой данных Э.Ф.Кодд ввел реляционные языки обработки данных – реляционную алгебру и реляционное исчисление.
Реляционная алгебра – это процедурный язык обработки реляционных таблиц. Здесь используется пошаговый подход к созданию реляционных таблиц.
Реляционное исчисление – непроцедурный язык, в котором таблица, содержащая ответы на запросы, определяется за один шаг.
Реляционная алгебра
Основная идея реляционной алгебры состоит в том, что коль скоро отношения являются множествами, то средства манипулирования отношениями могут базироваться на традиционных множественных операциях, дополненных некоторыми специальными операциями, специфичными для баз данных.
Набор основных алгебраических операций состоит из восьми операций, которые делятся на основные и дополнительные.
Основные – это объединение, разность, декартово произведение, проекция, выбор. К дополнительным относят пересечение, естественное соединение, соединение и деление.
Объединение
Объединением двух совместимых по типу отношений  и
и  называется отношение с тем же заголовком, что и у отношений и , и телом, состоящим из кортежей, принадлежащих или , или , или обоим отношениям.
называется отношение с тем же заголовком, что и у отношений и , и телом, состоящим из кортежей, принадлежащих или , или , или обоим отношениям.
Синтаксис операции объединения:
Замечание. если некоторый кортеж входит и в отношение , и отношение , то в объединение он входит один раз.
Пример. Пусть даны два отношения и с информацией о сотрудниках:
Таблица 1 - Отношение A
| Табельный номер | ||
| Фамилия | Зарплата | |
| 1 | Иванов | 1000 |
| 2 | Пушников | 2500 |
| 4 | Сидоров | 3000 |
Таблица 2 - Отношение B
| Табельный номер | Фамилия | Зарплата |
| 1 | Иванов | 1000 |
| 2 | Петров | 2000 |
| 3 | Сидоров | 3000 |
| 2 | Пушников | 2500 |
Замечание. Как видно из приведенного примера, потенциальные ключи, которые были в отношениях и не наследуются объединением этих отношений. Поэтому, в объединении отношений и атрибут "Табельный номер" может содержать дубликаты значений. Если бы это было не так, и ключи наследовались бы, то это противоречило бы понятию объединения как "объединение множеств". Конечно, объединение отношений и имеет, как и любое отношение, потенциальный ключ, например, состоящий из всех атрибутов.
Пересечение
Определение 3. Пересечением двух совместимых по типу отношений и называется отношение с тем же заголовком, что и у отношений и , и телом, состоящим из кортежей, принадлежащих одновременно обоим отношениям и .
Пример 3. Для тех же отношений и , что и в предыдущем примере пересечение имеет вид:
Таблица 4 - Отношение A INTERSECT B
| Табельный номер | Фамилия | Зарплата |
| 1 | Иванов | 1000 |
Замечание. Казалось бы, что в отличие от операции объединения, потенциальные ключи могли бы наследоваться пересечением отношений. Однако это не так. Вообще, никакие реляционные операторы не передают результатирующему отношению никаких данных о потенциальных ключах. В качестве причины этого можно было бы привести тривиальное соображение, что так получается более просто и симметрично - все операторы устроены одинаково. На самом деле причина более глубока, и заключается в том, что потенциальный ключ - семантическое понятие, отражающее различимость объектов предметной области. Наличие потенциальных ключей не выводится из структуры отношения, а явно задается для каждого отношения, исходя из его смысла. Реляционные же операторы являются формальными операциями над отношениями и выполняются одинаково, независимо от смысла данных, содержащихся в отношениях. Поэтому, реляционные операторы ничего не могут "знать" о смысле данных. Трактовка результата реляционных операций - дело пользователя.
Примеры использования реляционных операторов
Пример 12. Получить имена поставщиков, поставляющих деталь номер 2.
Решение:

Пример 13. Получить имена поставщиков, поставляющих по крайней мере одну гайку.
Решение:
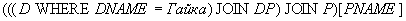
Ответ на этот запрос можно получить и иначе:
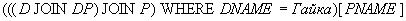
Пример 14. Получить имена поставщиков, поставляющих все детали.
Решение:

Пример 15. Получить имена поставщиков, не поставляющих деталь номер 2.
Решение:

Ответ на этот запрос можно получить и пошагово:
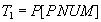 - получить список номеров всех поставщиков
- получить список номеров всех поставщиков
 - соединить данные о поставщиках и поставках
- соединить данные о поставщиках и поставках
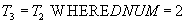 - в данных о поставщиках и поставках оставить только данные о поставках детали номер 2.
- в данных о поставщиках и поставках оставить только данные о поставках детали номер 2.
 - получить список номеров поставщиков, поставляющих деталь номер 2.
- получить список номеров поставщиков, поставляющих деталь номер 2.
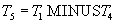 - получить список номеров поставщиков, не поставляющих деталь номер 2.
- получить список номеров поставщиков, не поставляющих деталь номер 2.
 - соединить список номеров поставщиков, не поставляющих деталь номер 2 с данными о поставщиках (получатся полные данные о поставщиках, не поставляющих деталь номер 2).
- соединить список номеров поставщиков, не поставляющих деталь номер 2 с данными о поставщиках (получатся полные данные о поставщиках, не поставляющих деталь номер 2).
 - искомый ответ (имена поставщиков, не поставляющих деталь номер 2).
- искомый ответ (имена поставщиков, не поставляющих деталь номер 2).
|
|
|
