 |


и факторам КСП-240 (F2) 7 страница
|
|
|
|
Приходится признать, что, несмотря на то, что с 1993 по 2000 год в России и за рубежом (Англия, Голландия, Австралия) появилось несколько десятков активных пользователей системы ТЕСТАН, мы пока не знаем ни одного случая, когда пользователи применили бы разработанную нами возможность создания интерпретирующей системы с помощью банка личностных черт. Одно из двух: либо наши идеи пока опережают свое время, либо разработка интерпретирующих (экспертных) систем в компьютерной психодиагностике развивается по другим направлением. Скорее всего, действуют обе причины: те специалисты, которые имеют достаточный уровень подготовки, для того чтобы детально изучить документацию к нашему программному средству и воспользоваться возможностями ТЕСТАНа, чаще всего замотивированы на то, чтобы создать свой собственный оригиначьный программный продукт в этом разделе софт-инженерии.
1 Сателлитная версия системы ЭКСПАН вызывается из системы ТЕСТАН по нажатию одной из клавиш системы главного меню.
Более реализованной и практичной на сегодняшний день является другая предусмотренная нами возможность сопряжения систем ТЕСТАН и ЭКСПАН (в табл. 6 она представлена пунктом «Выход2» в субменю «ВЫ-ХОД+»). В этом режиме наш комплекс позволяет:
• принять многокритериальное (многофакторное) решение с помощью автоматизированного взвешивания значимости различных, факторов независимыми экспертами или непосредственно заказчиком (ЛПР — лицом, принимающим решение);
• проверить экспертную валидность созданного теста с помощью независимых судей, оценивающих ту же выборку испытуемых.
В данном режиме, в ЭКСПАН-Т (так названа сателлитная версия системы ЭКСПАН) формируется структура данных, изображенная на рис. 32.
|
|
|
Как видим, тестовые результаты (баллы) выступают в ЭКСПАНе в качестве одного из возможных «слоев» полного куба данных. Другие «слои куба» образуются с помощью экспертных оценок. Для этого каждый эксперт должен оценить каждого испытуемого по всем факторам, что и обеспечивает сателлитная система ЭКСПАН-Т.
Именно в такой форме мы пытались в разработанных нами программных средствах практически реализовать идеи совмещения объектной и субъектной парадигм анализа данных. '
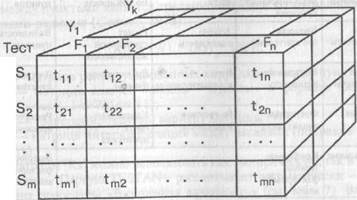
Рис. 32. Трехсторонняя структура (куб) данных в системе ТЕСТАН + ЭКСПАН. В качестве первого «слоя» выступает (в отличие от всех остальных слоев) не матрица экспертных оценок «испытуемый * фактор», а объективные баллы испытуемых, полученные по данным факторам в ходе тестирования. Таким образом, возникает возможность не только учета тестовых и экспертных данных, но и расчета согласованности между тестовыми и экспертными данными (экспертная валидизацмя теста).
Психометрический пакет ТЕСТАН+
В контексте данного исследовательского проекта необходимо также хотя бы кратко описать те процедуры психометрического анализа тестовых данных, которые были реализованы в рамках системы ТЕСТАН. В табл. 7 показано, как выглядит главное меню «психометрической субсистемы» ТЕСТАНа под названием «TESTAN+».
Использующий современные ресурсы расширенной памяти персональных компьютеров (скомпилированный в защищенном режиме на Borland-Pacal-7. 0) пакет ТЕСТАН+ позволяет анализировать матрицы практически неограниченной размерности/С помощью этого пакета мы анализировали, в частности, не только интеркорреляции между 300 пунктами 16РФ, но и для 377 пунктов ММИЛ (известная модификация MMPI, созданная Ф. Б. Березиным и соавторами), подсчитанные по выборкам, включаю-
Возможности системыТЕСТЛН. Меню психометрической субснстемы «Тестан+»
|
|
|
Таблица 7
| НОРМЫ | ВАЛ ИД НОСТ1. | НАДЕЖНОСТЬ | ДОСТОВЕРНОСТЬ | ПУНКТЫ |
| Анализ распределения | Вввод и редактирование критерия | Расщепление теста | Редактор баллов по СЖ-шкале | Надежность пунктов |
| Проверка нормальности | Внешняя {по критерию) | Альфа-надежность | Расчет социальной Желательности | Валидность пун ктов |
| Проверка устойчивости | Внутренняя вал и дн ость | Ввод и редактирование | Дублирующие пункты | Достоверность пунктов |
| Табличные нормы | Факторн ый анализ шкал | Ре-тестовая надежность | Консистент-ность протокола | Ре-тестовая надежность |
| Критериальные нормы | Конфирма-торный факторный анализ | - | Эксплораторный факторный анализ | |
| Настройка стандартной шкалы | Кластерный анализ | |||
| Анализ конгруэнтности | ||||
| * | Сокращение пунктов |
щим свыше 1000 испытуемых. Сравнение факторных решений, полученных с помощью ТЕСТАН+ и самым, по-видимому, ныне популярным западным пакетом SPSS-10, показало, что главные компоненты и варимакс-факторы совпадают с точностью до сотых долей (по величинам факторных нагрузок).
Оставим в стороне такие чисто практические удобства, как скорость и простота сбора и анализа результатов1. Наиболее значимым и полезным для нашего исследования свойством субсистемы ТЕСТАН+ следует считать удобную возможность анализа конгруэнтности — автоматического сравнения различных эмпирически найденных факторных решений и ключей (теоретических факторных систем), а также конфирматорный факторный анализ (КФА) (см. таблицу 7).
Алгоритм КфА в системе ТЕСТАН
Идеи, реализованные нами в оригинальном алгоритме конфирматорно-го анализа, сводятся к следующему. Этот простой алгоритм основан на сравнении эмпирических корреляций между пунктами с корреляциями, репродуцированными на основе заданных факторов. КФА призван проверить, в какой степени заданные вами факторы (заданные в шкальных ключах) позволяют объяснить существующие интеркорреляции между пунктами, Основная формула для расчета матрицы репродуцированных корреляций между пунктами является традиционной для косоугольного многофакторного решения (Сотгеу, 1973):
|
|
|
[Ri] = [W] * [Rs] * [W]\
где [Ri] — матрица репродуцированных корреляций между пунктами;
[W] — матрица ключей «шкалы * пункты» в формате факторных псевдонагрузок (~l< =Wij< = +1);
[V/]' —транспонированный вариант матрицы [W];
[Rs] — матрица интеркорреляций между шкалами (поправка на косо-
угольность). .
Для матрицы [Rs] можно использовать как эмпирическую, так и теоретическую модель. Первую TESTAN+ рассчитывает автоматически — в ходе выполнения процедуры «Внутренняя валидность» (см. табл. 7). Во втором случае пользователь просто редактирует матрицу [Rs], полученную после расчетов, в соответствии со своими собственными представлениями.
1 Хотя именно это и приводит к повышению темпа исследовательских работ — делает возможным в считанные дни разработать мощный тест, собрать по нему в компьютерном классе (в локальной сети) представительный массив в несколько сот протоколов, тут же проанализировать, построить обоснованную факторную структуру, отбросить неудачные пункты (не дающие вклад ни в один из интерпретируемых факторов).
Алгоритм КФА в TESTAN+ рассчитывает остаточную корреляцию (разность эмпирической и репродуцированной) и сходство (между эмпирической и теоретической корреляцией) для каждой пары пунктов. Пользователь может ввести собственные критические уровни для остаточной корреляции и сходства. По умолчанию установлены следующие значения:
Критическая остаточная корреляция (КОР) 1, 0
Критическое сходство (КС) -0, 2
Все пары пунктов с остаточной корреляций выше КОР (или со сходством ниже КС) указываются в файле с результатами КФА. Чем меньше пар пунктов указано в файле с результатами КФА, тем успешнее следует считать принятую модель заданных факторов. Те нары пунктов, корреляцию между которыми пользователь (разработчик теста) fie смог предсказать, возможно, нуждаются в переформулировании. Или в пересмотре нуждается общая концепция тестовых шкал.
О результатах, полученных нами с использованием данного алгоритма, см. следующую главу 4.
|
|
|
Тестирование
в Интернете (Тепетестинг)
В 1997 году под нашим руководством в России состоялась первая олимпиада для выпускников школ с использованием Интернет-технологии «Телетестинг» {Шмелев, Ларионов, Серебряков, 1998). В этом случае пользователь получает на свой локальный компьютер только тестовые задания, а обработка данных производится на сервере у разработчика. Существует ряд модификаций этой общей схемы — от меньшей до большей нагрузки на процессы сетевого обмена информацией. Самый «нагруженный» для сети вариант — это так называемое «он-лайн-тестирование». В этом случае по сети передается либо гипертекстовая страничка с тестовыми заданиями, либо фактически каждое отдельное задание теста. Для тестов, где существенно время ответа, этот вариант имеет смысл применять при наличии высокоскоростных оптических линий и нет смысла — при наличии медленных теле-фонно-модемных линий связи. Кроме того, существенным недостатком этого варианта является фактическая незащищенность тестовых заданий от несанкционированного распространения.
В «Телетестинге» нами был применен комбинированный подход: проведение теста в режиме off-line (без подключения к Интернету), а получение теста и обработка результатов — в режиме on-line. При этом применены многае достижения предыдущего периода. Это и использование алгоритмов со случайным предъявлением тестовых заданий из большого банка (random selection), н адаптивное тестирование (CAT — computer adaptive testing, Шмелев, 1999).
В чем же конкретно Интернет-технологии новы, почему можно говорить о том, что они знаменуют качественно новый этап в развитии психологического тестирования?
• Формируется новый тип диагностической ситуации «дистанционное тестирование» (ее неправильно считать «заочной», ибо она характеризуется определенными элементами интерактивпости, хотя и менее выраженными, чем при очном тестировании). В силу дистанционных отношений между экспериментатором и испытуемым повышается роль мотивации самопознания, повышается роль добровольцев, которым необходимо «оплатить» их участие в пилотировании сырой версии методики с помощью автоматизированной интерпретации их сугубо предварительных результатов, тем самым повышается роль систем автоматизированной интерпретации. Если в очном компьютерном тестировании экспериментатор может «на словах» пояснить испытуемому малопонятный для него профиль, то в заочном тестировании испытуемый хочет получить связный и понятный текст (т. н. «narrative report» — повествовательный отчет).
• Взаимоотношения между пользователями и разработчиками тестов оказываются по-настоящему интерактивными, складывается интерактивная модель сотрудничества. При этом банки протоколов автоматически пополняются, что создает возможности внесения своевременных коррективов в методики.
|
|
|
• Кардинально расширяется аудитория пользователей тестов и других процедур, включая и испытуемых, и экспериментаторов. В результате значительно повышается репрезентативность диагностических норм, популя-ционная устойчивость ключей и т. д. Если раньше на получение нескольких сотен протоколов уходили недели и месяцы, то теперь это можно получить
за один день'.
• Резко расширяются возможности участия специалистов (в том числе из разных стран) по созданию корпоративных банков тестовых заданий и систем интерпретации результатов2.
Существуют и явные проблемные аспекты, которые приносит с собой эпоха Интернета в науку в целом и, в частности, в экспериментальную психологию индивидуальных различий. Повышается роль электронных публикаций и явно сокращается роль академических публикаций в форме «твердых копий» (обычные журналы и книги). Исследователи, захваченные невиданными ранее возможностями и перспективами, просто не успевают доводить до стандартных публикаций свои новейшие разработки.
1 К сожалению, несмотря на все наши агитационные призывы, пользователи слишком редко и мало передавали нам собранные ими банки протоколов по нашим компьютерным тестам в течение всей «эпохи» персональных компьютеров.
2 В качестве примера такого сотрудничества следует указать проект, который реализовал в Интернете Л. Голлберг, о чем мы коротко упоминали во второй главе, IPIP — International Personality Item Pool (адрес в Интернете — http: //www. ipip. ori. org).
В русскоязычном Интернете уже сейчас можно назвать десятки сайтов, на которых опубликованы развлекательные психологические тесты (см. обзор в так называемом «Тест-ревю» на сайте http: //www. ht. ru), все-таки эти поделки в большинстве случаев произведены программистами и журналистами, а профессиональные психологи чаще осознают высокую ответственность за сообщение каких-то сведений о личности испытуемого в ситуации, когда нет возможности как-либо устно смягчить или скорректировать его возможную неадекватную болезненную реакцию на эту информацию.
Перед тем как взяться за «интернетизацию» личностных тестов, мы применили «Телетестинг» для тестирования знаний. Обратная связь в этой области хотя и значима, но в меньшей степени может породить возможный эффект типа «ятрогении» (внушенное заболевание). Но главным в обращении к тестированию знаний для нас было то обстоятельство, что именно в этой области во второй половине 90-х годов в России сложился квалифицированный спрос на тестовые услуги, обеспеченный техническим наличием первых учебных компьютерных классов, подключенных к Интернету. За пять лет — с 1997 по 2001 год — в олимпиадах «Телетестинг» приняло участие около 60 тысяч старшеклассников и абитуриентов из более чем 100 городов России и ближнего зарубежья1.
Постепенно к Интернету стали «подключаться» не только математики и программисты (те же руководители компьютерных классов), но и психологи. Значительно расширилась аудитория добровольцев-интересантов, которые ныне представляют собой настоящую армию любителей самотестирования, насчитывающую, по самым скромным оценкам, уже несколько десятков тысяч человек (если судить по суммарной суточной посещаемости сайтов, на которых опубликованы психологические тесты). На сегрдня создаются предпосылки для реализации в Интернете идеи «виртуальной лаборатории», в которой многие процессы и процедуры по созданию тестов будут осуществляться в интерактивном режиме он-лайн. Одним из прототипов такой лаборатории уже сейчас может служить разработанный нами раздел «Психоигротека» на сайте «Гуманитарные технологии» (http: // www. ht. ru). Другой образец такой лаборатории предложен в русском Интернете нашим бывшим сотрудником Д. С. Сатиным (http: // testology. psychology. ru). В совместном исследовании с В. Г. Ромеком Сатину удалось показать, что в Интернете принципиально не меняются психометрические параметры таких классических личностных вопросников, как,
1В ходе олимпиады-98 мы предъявили участникам факультативно т. н. «Тест интеллектуального потенциала» (ТИП). Уже в первый лень мы получили свыше 2000 протоколов по всей России, и тем самым задача получения репрезентативных норм на общенациональной выборке (правда, определенного возраста) была решена с невиданной ранее скоростью.
например, вопросника EPI, выполненного в нашей адаптации 1984 года (Ромек, Сатин, 2000).
Если иметь в виду проект «Психосемантика личностных черт», то использование достижений этого исследовательского проекта в Интернете уже обозначилось, в частности, в такой форме. А. Г. Ларионов разработал и реализовал в Интернете опросник «Модель идеального руководителя» (см. ссылку в «Психоигротеке» на сайте http: //www. ht. ru), в котором пользователям предлагается не только выбирать качества из заданного набора, но и формулировать собственные качества, При этом свободные формулировки анализируется с помощью банка в 2090 личностных черт, построенного в рамках проекта ТЕЗАЛ. В результате индивидуальная модель идеального руководителя строится в форме стандартного факторного профиля 15РФ (без фактора социальной желательности).
Другой пример представляет собой сетевая версия так называемого «Фототеста» (см. тот же адрес в Интернете): пользователи оценивают фотопортреты с помощью факторных шкал Большой Пятерки, получают обратную связь о том, как точно они пользуются этими факторами в ходе визуальной диагностики, могут прислать собственный фотопортрет и получить его оценку со стороны независимых пользователей Интернета (этот проект получил у нас условное название «Имидж-ателье»).
Но, увы, дальнейшее обсуждение замечательных перспектив (и новых проблем), связанных с созданием «виртуальных лабораторий», остается пока за рамками данной программы исследований, основные работы по которой были выполнены еще до эпохи Интернета.
Глава 4
Валидность МОДЕЛЬНЫХ ПРЕДСТАВЛЕНИЙ
В этой главе мы пытаемся расположить первую группу гипотез в такой последовательности, чтобы облегчить читателю прослеживание логики последовательного усложнения средств отображения личностного " семантического пространства. Но автор вместе с тем отчетливо осознает, что работа по взаимной увязке приведенных в этой главе модельных представлений во многом еще находится в промежуточной стадии. На карте полиморфного описания ЛСП остается немало белых пятен, порождающих иной раз больше вопросов, чем ответов.
Полученные нами эмпирические данные могут рассматриваться лишь как один из возможных источников аргументации в пользу того или иного модельного представления. Релевантность эмпирическим данным, как это было всегда в истории гуманитарного научного познания, является не единственным, а лишь одним из возможным аргументов в пользу выбора той или иной модельной системы.
Не меньшую роль здесь и по сей день продолжают играть «культурно-исторические» и субъективистские факторы: сила инерции (смена парадигм происходит медленно и последовательно и не может осуществляться прыжками через одну или сразу две-три ступени). Кроме того, идеологические соображения и контекст релевантных прикладных задач по-прежнему диктуют выбор моделей, по крайней мере, не в меньшей степени, чем соответствие эмпирическим данным.
КРОСС-КУЛЬТУРНАЯ ГИПОТЕЗА: S-ДАННЫЕ
Таксономические исследования
Выделение максимально универсальных контекстно-независимых характеристик личности, направлений межиндивидуальной вариации личностных особенностей (dimensions) было и продолжает оставаться страстной мечтой
самых одержимых исследователей в этой области. По силе одержимости и по своей когнитивной основе эту исследовательскую установку вполне уместно сравнить с упованиями средневековых алхимиков, искавших возможность синтеза всех возможных веществ (прежде всего золота, как мы помним) путем комбинирования всего нескольких простых элементов.
Как мы уже отмечали в первой главе, к 60—70-м годам нынешнего столетия фактически стала очевидной бесплодность попыток свести все многообразие индивидуального поведения к небольшому перечню универсальных черт: любые факторные системы давали возможность объяснить лишь меньшую часть (меньше 50 процентов) дисперсии наблюдаемого поведения. Но несмотря на это снижение пафоса, задача поиска максимально возможной универсальной системы остается актуальной хотя бы в том смысле, что исследователям необходимо выбрать одну из множества альтернативных факторных систем. Содержательно-психологическая интерпретация таких универсальных факторов позволила бы создать объяснительный фундамент для современной дифференциальной психологии и вносила бы необходимый {хотя и не достаточный) вклад в прогнозирование поведения людей в широком классе ситуаций и на больших отрезках времени.
Одним из эвристически ценных приемов в поиске глобальных личностных факторов следует признать межкультурные сравнения. Именно такая кросс-ситуационность, которая является универсальной для разных языковых культур, для разных социальных условий, указывает нам на заведомо глобальные характеристики.
На этом пути мы прежде всего попытались сравнить факторно-таксономические модели лексики личностных черт, построенные для английского и русского языков. Нами сравнивалась факторная модель, построенная Л. Голд-бергом (Goldberg, 1990), и модель, полученная в нашем таксономическом проекте (Шмелев и др., 1991): Стратегия сопоставительной работы подробно обсуждалась с профессором Орегонского университета США Льюисом Голдбергом по электронной почте и в ходе очных встреч на разных конференциях. Результаты сравнения опубликованы в совместной статье в «Психологическом журнале» в 1993 году (Голдберг, Шмелев, 1993).
Вычислительная работа по сравнению факторных структур была выполнена А. Г. Шмелевым и основывалась на следующем основном технологическом приеме. Каждому англоязычному термину, для которого известна факторная нагрузка по английским факторам, полученным Л. Р. Голдбергом, ставился в соответствие некий русскоязычный эквивалент, для которого известна факторная нагрузка по русским факторам из исследования А. Г. Шмелева и соавторов. Такое соответствие позволяло применить процедуру подсчета конгруэнтности факторов по традиционной формуле:
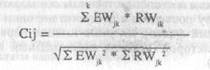
где Cij — коэффициент конгруэнтности между русскоязычным фактором j и англоязычным фактором i;
EWki — факторная нагрузка английского слова к на английский фактор i;
RWkj — факторная нагрузка русского эквивалента для англоязычного слова к на русский фактор j.
На первом шаге были взяты множественные русскоязычные эквиваленты для 75 названий классов Нормана и матрица факторных нагрузок из первого исследования Голдберга (опубликована в статье Goldberg, 1990). Эти эквиваленты были получены с помощью независимого пере-водчика-билингвиста из московской редакции издательства «Прогресс» А. А. Зура. Всего было использовано 220 русских слов из русского словника (около трех русских слов на одно английское в среднем). Для всех русскоязычных эквивалентов одного английского слова факторные нагрузки из русскоязычной матрицы усреднялись. В результате. подсчета конгруэнтности между каждым английским фактором и каждым из пятнадцати русских факторов были получены результаты, подтвердившие кросс-культурную устойчивость пятифакторной модели. В табл. 8 приведен самый важный фрагмент матрицы из коэффициентов конгруэнтности, указывающих на сходство английских (по строкам) и русских (но столбцам) факторов.
Таблица 8
Межъязыковая конгруэнтность факторов на материале русских эквивалентов для
75 имен кластеров Нормана.
Англоязычная таблица факторных нагрузок взята по данным первого исследования
Голдберга (Goldberg, 1990).
| Английские факторы | Русские факторы 3 4 | |||||
| 1, Surgency | 0. 03 | 0. 08 | 0. 83** | -0. 26 | 0. 32 | 0. 46 |
| 2. Agreeableness | 0. 80** | 0. 31 | -0. 34 | 0. 05 | -0. 20 | -0. 60 |
| 3. Conscientious | 0. 36 | 0. 33 | 0. 28 | 0. 78** | 0. 40 | -0. 45 |
| 4. Em. Stability | -0. 19 | 0. 38 | -O. 50 | 0. 45 | 0. 75** | 0. 11 |
| 5. Intellect | -0. 17 | 0. 70** | 0. 23 | 0. 37 | 0. 42 | -0. 32 |
Примечание. ** — максимальные элементы для строк матрицы.
Легко видеть, что существует изоморфизм двух факторных структур — максимумы по строкам и столбцам таблицы совпадают. То есть каждому английскому фактору поставлен в соответствие один и только один самый похожий русский фактор из числа именно первой пятерки самых мощных русских факторов (дающих максимальный вклад в дисперсию экспертных оценок).
Для сравнения мы привели данные для шестого русского фактора (шестой столбец в табл. 8). Известные различия двух факторных моделей проявляются в том, что иерархии английских и русских факторов по значимости различаются: в русской культуре на первом месте стоит фактор моральной оценки личности (с компонентом эмпатийности, аффек-тотимичности — как в факторе А из 16PF Кэттэлла), а в англо-американской —'- фактор, который в психосемантической традиции можно было бы интерпретировать как фактор Динамизма (Сила + Активность Осгуда). Но можно ли делать из этого первого результата далеко идущие выводы в плане обсуждаемой здесь гипотезы?
Для того чтобы проверить устойчивость полученного нами изоморфизма, а также для того, чтобы повысить качество подобранных соответствий русских и английских слов, А. Г. Шмелевым на базе компьютерной системы ТЕЗАЛ-3 была проделана работа по подбору оптимальных русских эквивалентов' для каждого из 339 английских терминов из усовершенствованного списка Голдберга (Goldberg, 1990).
При этом в качестве оптимального перевода мы пытались взять (за небольшим исключением) слово, которое предлагалось системой ТЕЗАЛ в результате следующей формальной процедуры: из всех вариантов русского перевода английского слова бралось то русское слово, которое оказывалось формально ближе к так называемому «интегральному семантическому портрету» для всех слов из данного кластера Голдберга (включающего заданное для перевода английское слово). Тем самым учитывался типовой семантический контекст, который мы имели в результате наличия 100 английских кластеров.
Использованный прием легко проиллюстрировать на первом же слове из первого кластера Голдберга — Gregarious. Словарные переводы этого слова на русский язык — «стадный, общительный». Но мы ищем такое русское слово из базового словника системы ТЕЗАЛ, которое является максимально семантически близким к двум другим словам из данного кластера, имеющим вполне однозначные русскоязычные эквиваленты (экстравертированный и общительный). Такое слово система ТЕЗАЛ автоматически находит, и им оказывается русское слово «компанейский», именно оно и взято в качество эквивалента (но не слово «стадный», которое в русском языке обладает отрицательной оценочной нагрузкой, отрицательной «социальной желательностью»). Конечно, в ряде случаев такая тактика приводила к серьезным проблемам: наилучшим эквивалентом для каких-то двух английских слов оказывалось одно и то же русское или наоборот. В этих случаях в качестве эквивалента приходилось
1 Эти эквиваленты (как и многие другие методически ценные материалы) опубликованы нами в приложении к докторской диссертации 1994 года. В этой книге мы имеем возможность опубликовать только материалы, значимые для более широкого круга читателей, а не для узкого круга специалистов, которые могут вознамериться перепроверить результаты нашего исследования.
брать не лучший, но второй или третий по качеству. Но таких «натяжек» было немного — всего 15 случаев (менее 5 процентов). Важным побочным технологическим результатом этой работы было получение психологически оптимизированного списка англо-русских однозначных эквивалентов личностных черт.
Какова же мера качества такой эквивалентности? Конгруэнтность факторных структур позволяет ее оценить. В табл. 9 мы видим, нто изоморфизм сохраняется, причем на более высоком уровне, чем в табл. 1. То есть проделанная процедура дала определенный эффект. Для четырех факторов из пяти достигнут уровень сходства, вполне сопоставимый с уровнем внутрикультурной устойчивости результатов. Это следует рассматривать как безусловное свидетельство наличия принципиального тождества межкультурных инвариантов в лексиконе личностных черт на уровне наиболее глобальных семантических признаков (факторов).
Таблица 9
Межъязыковая конгруэнтность факторов на материале русских эквивалентов для 339 терминов Голдберга. Русскоязычные эквиваленты подобраны с помощью системы ТЕ-ЗАЛ. Англоязычная таблица факторных нагрузок взята по данным третьего исследования Голдберга (Goldberg, 1990).
| Русские факторы | ||||||
| Английские | ||||||
| факторы | ||||||
| 1. Surgency | 0. 07 | 0. 29 | 0. 90** | -0. 07 | 0. 50 | 0. 36 |
| 2. Agreeableness | 0. 87** | O. 40 | -0. 10 | 0. 37 | -0. 15 | -0. 48 |
| 3. Conscientious | 0. 31 | 0. 53 | 0. 24 | 0. 96** | 0. 57 | -0. 51 |
| 4. Em. Stability | 0. 28 | 0. 28 | -0. 43 | 0. 59 | 0. 45 | -0. 85** |
| 5. Intellect | 0. 37 | 0. 92** | 0. 48 | 0. 53 | 0. 40 | -O. 40 |
Примечание. ** — максимальные элементы для строк матрицы.
|
|
|
