 |


Харьковский национальный университет радиоэлектроники
|
|
|
|
___
ХАРЬКОВСКИЙ НАЦИОНАЛЬНЫЙ УНИВЕРСИТЕТ РАДИОЭЛЕКТРОНИКИ
Факультет: ТКВТ
Кафедра: ТКС
Лабораторный практикум по теории электросвязи
Лабораторная работа № 12
Тема: 12 ИССЛЕДОВАННИЕ МЕТОДОВ ЭФФЕКТИВНОГО КОДИРОВАНИЯ
Цель работы: Изучение основных понятий теории информации, информационных характеристик систем передачи сообщений и методов эффективного статистического кодирования на примере эффективного кода Хаффмана, кода Шеннона-Фано и алгоритма арифметического кодирования.
12. 1 Подготовка к выполнению работы
Во время подготовки к выполнению работы нужно ознакомиться с теоретическим материалом по конспекту лекций, рекомендованной литературой и приведенными ниже краткими теоретическими сведениями, выполнить домашнее задание согласно своему варианту, получить у преподавателя допуск и вариант задания на лабораторную работу.
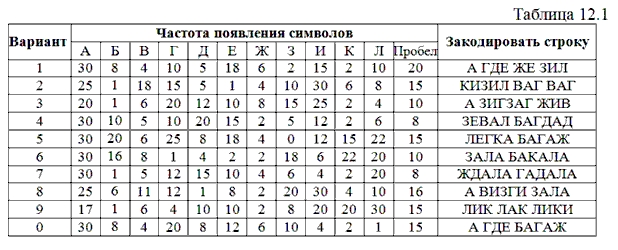
В процессе домашней подготовки к лабораторной работе необходимо ответить на контрольные вопросы, построить код Шеннона-Фано и Хаффмана, закодировать с помощью этих кодов строку символов согласно варианту, указанного преподавателем. Исходные данные для выполнения домашнего задания приведены в таблице 12. 1.
Неравномерное кодирование дискретных источников.
Изучая информационные характеристики дискретных источников информации мы убедились в том, что источники информации, вообще говоря, избыточны в том смысле, что, при эффективном кодировании можно уменьшить затраты на передачу или хранение порождаемой ими информации. Для представления данных потребуется тем меньше бит, чем меньше энтропия. Не нужно долго изучать теорию информации, чтобы догадаться, что для таких источников нужно использовать кодирование, сопоставляющее часто встречающимся сообщениям короткие кодовые комбинации, а редким сообщениям – длинные. Мы начнем с кодирования отдельных букв источника. Оптимальным побуквенным кодом является известный код Хаффмана. Однако, для того, чтобы понять, как правильно кодировать последовательности, нам придется изучить побуквенные код Шеннона - Фано. От него – один шаг к пониманию арифметического кодирования, которое позволяет предельно эффективно кодировать длинные последовательности и обладает при этом относительно невысокой сложностью.
|
|
|
Постановка задачи неравномерного кодирования
Предположим, что для некоторого дискретного источника X с известным распределением вероятностей {p(x), xÎ X} требуется построить эффективный неравномерный двоичный код над алфавитом A = {a}. Как и ранее, мы сосредоточим внимание на двоичных кодах, т. е. мы предполагаем, что A = {0, 1}. Дело в том, что, во-первых, все идеи в полной мере иллюстрируются на этом примере. Во-вторых, обобщение на случай произвольного алфавита не представляет никакой трудности.
В качестве примера источника рассмотрим алфавит русского языка. Сразу же вспоминается азбука Морзе, которая сопоставляет каждой букве комбинацию точек «•» и тире «-». Например, часто встречающейся букве «е» соответствует комбинация «•», а более редкой букве «ч» соответствует комбинация «- - - •». Однако, мы не получим хорошего кода просто заменив точки нулями, а тире – единицами. Нам будет не хватать пауз, разделяющих буквы (3 точки), пауз, разделяющих слова (7 точек). По сути дела код Морзе – это недвоичный код.
Нам необходим такой двоичный код, который допускает однозначное разделение последовательности кодовых слов на отдельные кодовые слова без использования каких-либо дополнительных символов. Это требование называют свойством однозначной декодируемости.
|
|
|
Неравномерный побуквенный код C = { 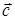 } объема |C| = N над алфавитом A определяется как произвольное множество последовательностей одинаковой или различной длины из букв алфавита A. Код является однозначно декодируемым, если любая последовательность символов из A единственным способом разбивается на отдельные кодовые слова.
} объема |C| = N над алфавитом A определяется как произвольное множество последовательностей одинаковой или различной длины из букв алфавита A. Код является однозначно декодируемым, если любая последовательность символов из A единственным способом разбивается на отдельные кодовые слова.
Пример 12. 1. Для источника X = {0, 1, 2, 3} среди четырех кодов
a)C1 = {00, 01, 10, 11};
b)C2 = {1, 01, 001, 000};
c)C3 = {1, 10, 100, 000};
d) C4 = {0, 1, 10, 01};
первые три кода однозначно декодируемы, последний код – нет.
Первый код этого примера – равномерный код. Понятно, что любой равномерный код может быть однозначно декодирован.
Для декодирования второго кода можно применить следующую стратегию. Декодер считывает символ за символом, и каждый раз проверяет, не совпадает ли полученная последовательность с одним из кодовых слов. В случае успеха соответствующее сообщение выдается получателю, и декодер приступает к декодированию следующего сообщения. В случае кода C2 неоднозначности не может быть, поскольку ни одно слово не является продолжением другого.
Если ни одно кодовое слово не является началом другого, код называется префиксным. Префиксные коды являются однозначно декодируемыми.
Код C3 заведомо не префиксный. Тем не менее, мы утверждаем, что он – однозначно декодируемый. Каждое слово кода C3 получено переписыванием в обратном порядке соответствующего слова кода C2. Для декодирования последовательности кодовых слов кода C3 можно переписать принятую последовательность в обратном порядке и для декодирования использовать декодер кода C2. Таким образом, мы приходим к следующему выводу.
Префиксность – достаточное, но не необходимое условие однозначной декодируемости.
Графически удобно представлять префиксные коды в виде кодовых деревьев. В частности, кодовое дерево кода C2 примера 12. 1. представлено на рис. 12. 1.
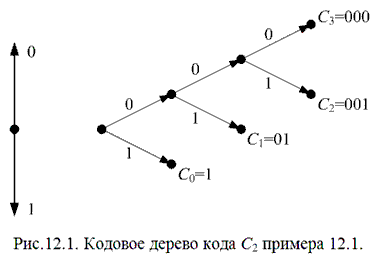
Узлы дерева размещаются на ярусах. На начальном (нулевом) ярусе расположен узел, называемый корнем дерева. Узлы следующих ярусов связаны с узлами предыдущих ярусов ребрами. Ребрам приписаны кодовые символы. Таким образом, каждой вершине дерева соответствует последовательность, считываемая вдоль пути, связывающего данный узел с корнем дерева.
|
|
|
Узел называется концевым, если из него не исходит ни одного ребра. Код называют древовидным, если в качестве кодовых слов он содержит только кодовые слова, соответствующие концевым вершинам кодового дерева.
Древовидность кода и префиксность – синонимы в том смысле, что всякий древовидный код является префиксным, и всякий префиксный код может быть представлен с помощью кодового дерева. Мы будем рассматривать только префиксные коды. В связи с этим возникает вопрос: не потеряли ли мы, оптимальное решение задачи, сузив класс кодов, среди которых мы ищем наилучшие? Ниже мы убедимся в том, что ответ на этот вопрос отрицательный.
Обсудим теперь, какие именно префиксные коды считать хорошими. Наша цель неравномерного кодирования состоит в уменьшении затрат на передачу сообщений, логично выбрать в качестве критерия качества кода среднюю длину кодовых слов. Рассмотрим источник X = {1, …, N}, который порождает буквы с вероятностями {P1, …, PN}. Предположим, что для кодирования букв источника выбран код  с длинами кодовых слов length( 1) = m1, ..., length( N) =mN соответственно. Средней длиной кодовых слов называется величина
с длинами кодовых слов length( 1) = m1, ..., length( N) =mN соответственно. Средней длиной кодовых слов называется величина
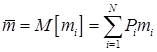 .
.
Пример 12. 2. Рассмотрим источник и коды из примера 12. 1. Подсчитайте среднюю длину кодовых слов кодов C1 и C2 для трех распределений вероятностей на буквах источника:
a) P0 = P1 = P2 = P3 = 1/4;
b) P0 = 1/2; P1 = 1/4: P2 = P3 = 1/8;
c) P0 = P1 = 1/8: P2 = 1/4; P3 = 1/2.
Результаты расчетов показывают, что не всегда и не любой неравномерный код эффективен. Еще один немаловажный аспект, который должен быть учтен при сравнении способов неравномерного кодирования, это сложность реализации кодирования и декодирования, а также сложность построения или модификации кода при изменении статистических данных об источнике.
Подводя итог, мы формулируем задачу побуквенного неравномерного кодирования как задачу построения однозначно декодируемого кода с наименьшей средней длиной кодовых слов при заданных ограничениях на сложность.
|
|
|
