 |


Анализ медико-биологических данных на основе их графического представления
|
|
|
|
Задачи биостатистики
Ниже приведены наиболее распространенные определения статистики вообще, и биостатистики в частности.
Статистика – отрасль знаний (наука), изучающая методы сбора, систематизации, обработки и интерпретации результатов наблюдений с целью выявления статистических закономерностей.
Биостатистика (биометрика) – отрасль знаний, связанная с разработкой и использованием статистических методов в научных исследованиях в медицине, здравоохранении и эпидемиологии.
Чтобы вникнуть в суть этих определений выясним, в чем была необходимость появления биостатистики, какие задачи она решает?
В своей практической деятельности врач, как правило, имеет дело с одним пациентом (в дальнейшем будем использовать термин биообъект), измеряет какие-то показатели его здоровья (признаки), ставит диагноз и назначает лечение. Это единичное явление, отдельный акт. Например, измерив рост одного человека, мы сразу делаем вывод: высокий, среднего роста он или низкорослый. А как поступить, если нам надо описать группу людей, учитывая, что они все разного роста (рисунок 1).
Рисунок 1
| Хср=178 см |
| Хср=178 см |
Первое, что приходит на ум – это определить средний рост. Теперь задумайтесь, а что это нам дает, какую информацию о росте людей в данной группе несет среднее значение. Многих такой вопрос ставит в тупик. Давайте обратимся к рисунку 2.
Рисунок 2
Из него видно, что при равенстве средних значений рост людей в двух группах значительно разница. Отсюда можно сделать вывод, что для их сравнения одних только средних недостаточно. По-видимому, нужны еще какие-то показатели.
Когда на автомобильном предприятии выпускают партию машин одной модели можно однозначно охарактеризовать объем двигателей этих машин, например, 1500 см3. Так нельзя поступить в случае биологических объектов в связи с тем, что они весьма изменчивы, обладают индивидуальными свойствами. Как говорят: нет двух одинаковых людей, как и нет двух одинаковых болезней.
|
|
|
Еще один пример приведен на рисунке 3. Это результаты измерения артериального давления до и после приема некоторого гипотензивного препарата. В исследовании приняли участие две группы.


Рисунок 3
Задача состоит в том, чтобы определить, насколько эффективен препарат, ведь реакции были неоднозначны: у кого-то снижение было значительным, у кого- то - незначительным, а есть и такие у кого АД повысилось. И еще одно - в какой из двух групп эффект был более выраженным? Стоит ли такой препарат производить и назначать гипертоникам? Подобные проблемы решаются на основе статистического анализа множественных наблюдений.
Обобщая вышесказанное, мы можем сформулировать первую задачу биостатистики - анализ групповых свойств и массовых явлений в биологической среде. Этому вопросу посвящен раздел статистики называемый описательной статистикой.
Теперь перейдем ко второй задаче биостатистики. Предположим, что в предыдущем примере с гипотензивным препаратом, испытанном на 7 больных, вы сделали вывод о его эффективности. Можем ли мы на этом основании предложить его для массового выпуска, будет ли он помогать и другим, тысячам, страдающим повышенным артериальным давлением? Наверное, многие ответят нет, не можем. Что же в таком случае делать, как проверить это средство, ведь как бы мы не увеличивали количество привлеченных к испытаниям лиц, все равно не сможем охватить всю совокупность гипертоников земного шара (в статистике используют термин генеральная совокупность). А ведь только это нас и интересует, а не результаты какого-то отдельного (выборочного) исследования, ведь мы предполагаем назначать препарат повсеместно. Статистические методы позволяют перенести результаты выборочных исследований на всю генеральную совокупность объектов, но с учетом, что есть вероятность ошибочности нашего утверждения. И если эта вероятность невелика, то мы принимаем сделанные выводы, в противном случае – отвергаем. Вопрос о том велика или невелика ошибка решает сам исследователь, исходя из сути решаемой проблемы. Например, я утверждаю, что данный препарат эффективен во всей генеральной совокупности, при этом вероятность ошибки составляет 0,05 (т.е. 5 %) и это меня вполне устраивает. Возможно, у кого-то другого более жесткие требования и он удовлетвориться только вероятностью ошибки не более 0,01 (1%).
|
|
|
Следующий случай продемонстрирует нам, к каким последствиям может привести незнание законов статистики и неумение ими пользоваться. Случай этот выдуманный, но весьма показательный. Фармкомпания разработала лекарственное средство, позволяющее повысить уровень гемоглобина, и испытало его на выборке из 5 человек. Результаты, приведенные на графике 4А, позволяют говорить о высокой его эффективности, ведь чем выше доза препарата, тем выше уровень Hb.
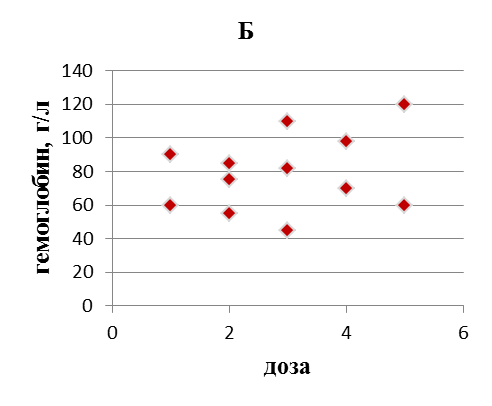

Рисунок 4
На основании этих данных было налажено массовое производство, вложены значительные финансовые и людские ресурсы. Однако, время показало, что препарат залежался на складах и его не назначают врачи. Озадачившись, ученые провели повторное, более массовое испытание и вот, что оно дало – одна и та же доза может быть эффективной для одних лиц и неэффективной для других (рисунок 4Б). Отнеся результаты выборочных исследований на всю генеральную совокупность, исследователи не оценили вероятность ошибки полученных результатов, а она была, по-видимому, значительной, т.е. полученная эффективность носила случайный характер.
Таким образом, мы фактически сформулировали вторую задачу биостатистики. Смысл ее в принятии наиболее обоснованного суждения относительно свойств и характеристик генеральной совокупности с опорой на результаты изучения выборки. Эта задача рассматривается в разделе, называемом теорией проверки статистических гипотез.
|
|
|
Статистические методы позволяют также решать задачи выявления взаимозависимостей между признаками, изучения динамики состояния биообъектов во времени, задачи классификации и прогнозирования.
Основные понятия и определения биостатистики
Терминология имеет важное значение в любой области знаний, поскольку, не владея ей, нельзя понять суть излагаемого, и соответственно невозможно использовать знания на практике. Проблема состоит еще в том, что различные авторы или коллективы, научные школы могут использовать различную терминологию. Так, с советских времен в статистике закрепились термины и обозначения, отличающиеся от тех, что приняты в зарубежной литературе. Поэтому нам необходимо определиться с терминологией, которую будем использовать в дальнейшем.
Любой биообъект характеризуется какими-либо признаками. Например: рост, вес, артериальное давление, пульс, уровень гемоглобина, цвет глаз и т.д. При измерении этих признаков у разных объектов получаем статистические данные. Если у каждого объекта измеряется один признак (например, гемоглобин), то получаются одномерные данные, если два признака (гемоглобин и ЧСС) – то данные двумерные, и т.д. – многомерные.
Пусть измерен пульс у разных людей и получены статистические данные: 65, 68, 72, 75, 80, 60, 65, 64, 61, 77, 73, 73, 69, 60…..
С математической точки зрения пульс представляет собой случайную величину. Это одно из основных понятий теории вероятности, на которую во многом опирается статистика. Случайной величиной X (x1, x2, x3 …..xi……xn) называется величина, которая в результате опыта может в определенных пределах принять то или иное значение, неизвестно заранее какое именно.
Генеральная совокупность - это множество всех обследуемых объектов, объединенных общими свойствами. Генеральная совокупность мужчин объединена половой принадлежностью, а генеральная совокупность голубоглазых мужчин имеют два общих свойства. Один и тот же объект может принадлежать разным генеральным совокупностям, в зависимости от того о каком общем свойстве идет речь.
|
|
|
Как правило (но не всегда), генеральная совокупность имеет очень много элементов (объектов), либо они труднодоступны. Поэтому обследуется некоторая часть генеральной совокупности – выборочная совокупность (выборка). Количество объектов в выборочной совокупности называется объемом выборки (n).
Выборка должна давать правильное, неискаженное представление о генеральной совокупности, или, как говорят, быть репрезентативной. Например, нельзя судить о заболеваемости кишечными инфекциями, обследуя только районы с высокими социально-экономическими условиями.
Как мы уже отмечали, результаты исследования выборки с определенной долей вероятности распространяются на всю генеральную совокупность, т.е. определяется их статистическая значимость.
Классификация признаков
Почему важно знать классификацию признаков (иногда говорят шкалы измерения)? Тип признака во многом определяет те статистические методы, которые могут быть применены для обработки данных. В литературе встречаются различные классификации, но все они достаточно близки друг к другу и предлагаемая ниже вполне достаточна для освоения основ биостатистики.
Различают количественные и качественные признаки. Количественные признаки выражаются числами. Значения количественных признаков могут быть непрерывными или дискретными. Дискретные – это признаки, значения которых отличаются не менее чем на единицу измерения признака (число человек в семье, койко-дни). Непрерывные признаки – это признаки, значения которых могут отличаться друг от друга на любую сколь угодно малую величину (рост, вес человека, объем).

Рисунок 5
Качественные признаки выражаются категориями. В свою очередь они в зависимости от вида данных делятся на номинальные (классификационные) и ординальные (порядковые). Говорят также, что соответствующие качественные признаки измеряются в номинальной или порядковой шкале. Разница между этими шкалами состоит в следующем.
Признак, измеряемый в номинальной шкале, принимает одно значение из конечного числа заведомо установленных градаций. Примерами признаков, измеряемых в номинальной шкале, являются пол (мужской, женский), цвет глаз (карие, зеленые, серые), классификация животных и т. п. Статистические данные, измеряемые в номинальных шкалах, представляются в виде таблиц, в которых приводятся частоты появления той или иной градации признака. Часто номинальные данные появляются при обработке эпидемиологических данных. Например, может представлять интерес вопрос о частоте встречаемости того или иного признака при том или ином заболевании.
|
|
|
Значения качественных признаков, измеряемых в ординалъной шкале, могут быть упорядочены, т.е. расположены по возрастанию или убыванию. Примерами таких признаков являются качество условий жизни (плохое, удовлетворительное, хорошее, очень хорошее), температура (нормальная, повышенная, высокая, очень высокая), шкала оценки боли. Для признаков, измеряемых в ординальных шкалах, операции сложения и вычитания не имеют смысла. Так, нельзя сказать, что студент, получивший на экзамене «пять» по статистике знает предмет на одну единицу лучше, чем студент, получивший по этому предмету «четыре», поскольку для знаний не существует единицы измерения. Однако можно сказать, что первый студент знает статистику лучше, чем второй.
Для представления значений ординальных признаков в числовой форме используется следующий способ. Все значения признака записываются в порядке возрастания в виде ряда. Каждому значению ставится в соответствие натуральное число, равное его номеру в ряду. Это число называется рангом. Например, качество условий жизни (плохое, удовлетворительное, хорошее, очень хорошее) будет представлено рангами 1, 2, 3, 4. Для ординальных признаков, представленных в виде рангов, разработаны специальные статистические методы, позволяющие измерять степень близости признаков (например, ранговая корреляция), проверять гипотезы о виде распределения, проводить дисперсионный анализ.
Для данных, представленных в номинальной шкале, также не определены операции сложения и вычитания. Эти данные (в отличие от ординальных признаков) не могут быть упорядочены и, следовательно, оцифрованы с помощью рангов. Применяя специальные статистические методы для номинальных признаков, можно проверить гипотезы о независимости признаков и о принаддежности двух или нескольких выборок к одной совокупности.
Анализ медико-биологических данных на основе их графического представления
Вернемся к примеру с анализом роста в группе людей. Если группа достаточно большая, то мы получим очень большой ряд данных: 175, 172, 180, 188, 166, 168, 170, 175, 178, 182, 188, 169 175, 172, 180, 188, 166, 168, 170, 175, 178, 182, 188, 169 175, 172, 180, 188, 166, 168, 170, 175, 178, 182, 188, 169……… и затруднимся дать обобщающую характеристику этой совокупности. Для более наглядного представления данных обычно используются графики, рисунки, диаграммы, таблицы. Воспользуемся подобным методом и мы – разобьем весь диапазон роста от минимума до максимума на равные интервалы по 10 см и посчитаем сколько объектов попадет в каждый из этих интервалов (частоту встречаемости), а затем построим график, как показано на рисунке 6А – по оси абсцисс отложим интервалы, а по оси ординат – частоту встречаемости (абсолютную или относительную в %).
Полученный график называется гистограммой распределения, он показывает, насколько часто встречаются те или иные значения изучаемой случайной величины (его вероятность), в данном случае роста, или другими словами как рост распределен по различным диапазонам. Теперь по этому графику попытаемся дать обобщенную характеристику изучаемой группе.

| 
| ||
| Рисунок 6 |
Минимальный рост лежит в пределах от 140 до 150 см, самые высокие имеют рост 190-200 см. Наиболее часто встречается средний рост (170-180 см) в 25% всех случаев. По мере удаления от среднего роста в меньшую и большую сторону частота встречаемости снижается. Низкорослые и высокие встречаются реже, чем лица среднего роста. Самые маленькие (140-150 см) составляют 10% совокупности, самые высокие (190-200 см) - 12%.
Представим, что количество обследованных бесконечно увеличивается, а длина интервалов бесконечно уменьшается, тогда мы получим график, который изображен на рисунке 6 в виде огибающей гистограммы. Это кривая дает нам представление о законе распределения случайной величины (иногда говорят просто распределение). Она может иметь различную форму. Распределение многих случайных величин имеет симметричный колоколообразный вид, и такое распределение называется нормальным (еще его называют Гауссовским распределением). Нормальное распределение имеет важное значение в статистике, поскольку обладает рядом замечательных свойств, о которых мы поговорим позже. Кроме нормального существуют и другие виды распределения. Так, форма гистограммы, представленной на рисунке 6Б, явно не соответствует колоколообразному виду. В статистике широко используются биноминальное, логарифмическое, хи-квадрат распределения, распределения Стъюдента, Фишера и др.
Надо отметить, что оценка закона распределения по кривой огибающей гистограммы является не совсем корректным, качественным, учитывая также и то, что гистограмма строится по ограниченным выборочным данным. Существуют специальные статистические процедуры и критерии, которые позволяют строго количественно оценить закон распределения. Им будет посвящена специальная глава.
В медицинских исследованиях при построении гистограмм длительность интервалов может быть не одинаковой, а их границы заранее оговорены. Например, в возрастной физиологии приняты следующие возрастные периоды
| возраст мужчин, лет | возраст женщин, лет | |
| период второго детства | 8-13 | 8-12 |
| подростковый период | 14-17 | 13-16 |
| юношеский период | 18-21 | 17-20 |
| взрослый период | 22-35 | 21-35 |
| зрелый период | 36-55 | 36-60 |
| пожилой период | 56-63 | 61-67 |
При анализе частоты пульса возможны такие интервалы: меньше 60 уд/мин, 60-80 уд/мин, больше 80 уд/мин.
В других случаях мы можем воспользоваться правилом построения гистограмм.
Пусть дана случайная величина Х (х1, х2,..., хn) – значения артериального давления у 25 испытуемых
108, 115, 133, 102, 110, 118, 118, 120, 120, 127, 127, 127, 110, 100, 105, 120, 120, 130, 135, 140, 135, 146, 145, 160, 155
Необходимо выполнить следующие шаги:
1. Элементы выборки объемом n =25 расположить в ранжированный ряд (по возрастанию или убыванию)
100; 102; 105; 108; 110; 110; 115; 118; 118; 120; 120; 120; 120; 127; 127; 127; 130; 133; 135; 135; 140; 145;146; 155; 160
2. Вычислить размах R (разность между минимальным и максимальным значением случайной величины):
R=xmax-xmin =160-100=60 мм.рт.ст.
3. Разбить вариационный ряд на k непересекающихся интервалов. k вычисляют по формуле Стерднесса, предусматривающей выделение оптимального числа интервалов:
k =1+3,322lg(n) (округлить до целого)
Можно воспользоваться следующими рекомендациями
Т.к. в нашем случае объем выборки равен 25, то выберем k =6. 4. Определить длину одного интервала
b=R/k =60/6=10 мм.рт.ст.
5. Определить границы каждого интервала 6. Определить частоты - количество ni элементов выборки, попавших в i -й интервал (элемент, совпадающий с правой границей интервала, относится к последующему интервалу) Наряду с частотами одновременно подсчитываются также относительные частоты Полученные результаты сводятся в таблицу, называемую таблицей частот группированной выборки.
7. Далее строится гистограмма (рисунок 7).
Рисунок 7 - Гистограмма распределения
|
 и процент случаев
и процент случаев  .
.

|
|
|
