 |


Алгоритм работы поисковой подсистемы
|
|
|
|
Поисковая подсистема системы информационно-лингвистического обеспечения распределенной СППР работает в четырех режимах:
- поиск без использования тезаурусов;
- поиск с использованием тезауруса;
- поиск с использованием частотного тезауруса;
- поиск по уже анализируемому ранее запросу.
Алгоритм работы данной подсистемы может быть представлен следующим образом (рис. 6.2).

Рис. 6.2. Алгоритм работы поисковой подсистемы
Первый этап выполнения поисковой процедуры – это первичный анализ проблемы. На данном этапе происходит задание начальных параметров поиска и инициализация поисковой процедуры, а также производится выбор одного из четырех возможных режимов выполнения процедуры поиска. На втором этапе полученные данные обрабатываются с целью определения их релевантности и ранжирования. Следующим этапом является просмотр полученных и обработанных данных лицом, принимающим решение, для выработки окончательной стратегии разрешения возникшей проблемы.
Рассмотрим каждый этап предлагаемого алгоритма более подробно.
На первом этапе выполняется первичный анализ проблемы (рис. 6.3).
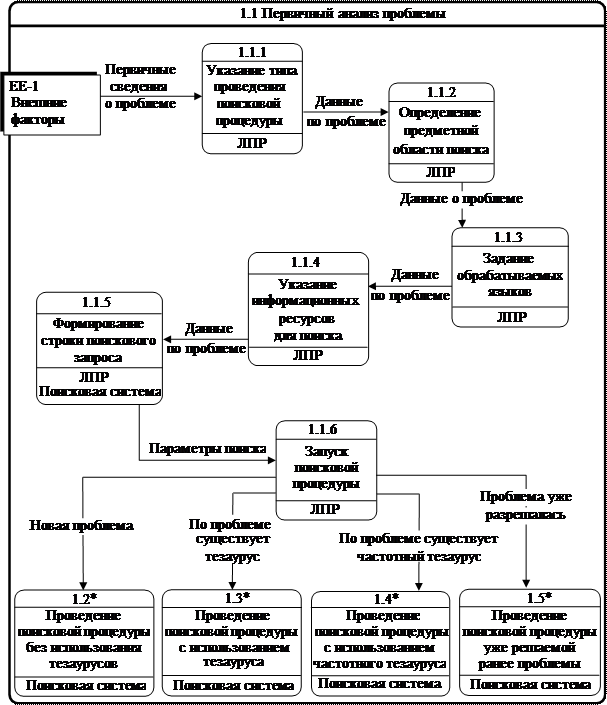
Рис. 6.3. Первичный анализ проблемы
На первом шаге указывается один из типов проведения поисковой процедуры [76]:
- поиск по заданному информационному ресурсу корпоративной сети;
- поиск по информационному ресурсу в Интернете;
- метапоиск по заданным информационным ресурсам корпоративной сети либо по всем ресурсам корпоративной сети;
- метапоиск по заданным информационным ресурсам Интернета;
- метапоиск по заданным поисковым ресурсам Интернета;
- смешанный метапоисковый алгоритм как по ресурсам корпоративной сети, так и в сети Интернет.
|
|
|
В зависимости от выбора того или иного типа поиска информации в пункте выбора информационных ресурсов автоматически изменяется список ресурсов. Например, если поиск производится не в Интернете, то его ресурсы не войдут в список выбора.
Второй шаг первого этапа – это определение предметной области поиска. На данном шаге указываются тезаурус или ключевые слова предметной области (не обязательно имеющие отношение к конкретной проблеме из предметной области), в рамках которых будет проводиться поисковая процедура.
На третьем шаге происходит указание обрабатываемых языков. Это очень важная характеристика, так как она связана с обеспечением мультилингвистичности как поисковой строки, так и ответа системы. По умолчанию поисковая подсистема работает в одноязычном варианте. Возможность мультилингвистичности также может быть ограничена наличием/отсутствием мультилингвистических тезаурусов.
На четвертом шаге необходимо указать информационные ресурсы, в рамках которых будет проведена поисковая процедура. Список ресурсов генерируется динамически в зависимости от выбора типа поиска.
Пятый шаг – формирование поисковой строки – может быть выполнен или с помощью тезаурусов, или вручную.
На шестом шаге, после того как лицо, принимающее решение, определилось с проблемой и задало все начальные характеристики, необходимо выполнить поисковую процедуру по всем четырем режимам.
Покажем обобщенный алгоритм работы проведения поисковых процедур (рис. 6.4) на примере возникновения новой ситуации.
Первый режим поисковой процедуры применяется в случае возникновения новой ситуации, по которой поиск ранее не проводился и, следовательно, отсутствует как обычный, так и частотный тезаурус. Этот режим наиболее прост в исполнении, однако дает наихудшие результаты. Здесь поиск производится по сформированной вручную поисковой строке. Качество выполнения данной процедуры в значительной степени зависит от качества поисковой строки, как и качество определения релевантности и ранжирования, на которое влияет то, каким образом данные обрабатывались.
|
|
|
При рассмотрении этого режима можно выделить функции проверки доступности информационного ресурса и удаления дублирующейся информации. Первая функция несколько ускоряет процесс поиска за счет того, что автоматически удаляет недоступные ресурсы из поиска, вторая отвечает за увеличение коэффициентов релевантности и ранжирования данного документа.

Рис. 6.4. Проведение поисковой процедуры без тезаурусов
Второй и третий режимы работы поисковой процедуры схожи с первым. Однако при этом необходимо отметить, что второй режим использует обычные тезаурусы, а третий – частотные.
Важной частью работы поисковой подсистемы также является мультилингвистичность тезаурусов, возникающая при получении поисковой строки. Здесь необходимо отметить, что если пользователь задал одноязычную поисковую строку и выбрал мультилингвистический поиск, то данная подсистема автоматически переведет одноязычную строку поиска в мультилингвистическую при помощи обычного мультилингвистического тезауруса или добавит новые мультилингвистические термы, используя частотные характеристики термов из частотного мультилингвистического тезауруса, а также проверит наличие мультилингвистичности термов в заданной поисковой строке и выбранных информационных ресурсах.
И, наконец, последний режим работы поисковой процедуры – проведение поисковой процедуры для уже решаемой ранее проблемы. Этот режим не имеет принципиальных отличий от рассмотренных выше режимов, за исключением того, что в результате осуществления проверки релевантности и ранжирования информации существенную роль будут играть просмотренные ранее документы, т. е. если документы, представленные системой, просматривались ЛПР ранее, то их релевантность будет выше и при ранжировании эти документы будут на первом месте.
После проведения поисковой процедуры полученное множество данных необходимо обработать (рис. 6.5).
|
|
|
|

Рис. 6.5. Обработка полученного множества данных
Поисковая процедура без использования мультилингвистических тезаурусов происходит без дополнительной проверки уровня релевантности полученных документов, что значительно снижает качество дальнейшего процесса ранжирования. В этом случае ранжирование происходит исходя из ранга документа, присваиваемого ему ресурсом, с которого данный документ был получен, при этом также учитывается частота употребления каждого документа на разных информационных ресурсах.
Оставшиеся три режима работы поисковой подсистемы проводят дополнительную проверку уровня релевантности каждого документа, на основе которого осуществляется ранжирование документа, однако при ранжировании в случае поиска по решаемой ранее проблеме документы, которые уже просматривались, получают наивысший ранг, а затем идут все остальные документы.
|
|
|
