 |


Тема 5. Многомерные статистические методы
|
|
|
|
Многомерный статистический анализ – раздел математической статистики, посвященный математическим методам построения оптимальных планов сбора, систематизации и обработки многомерных статистических данных, направленным на выявление характера и структуры взаимосвязей между компонентами исследуемого многомерного признака и предназначенным для получения научных и практических выводов. Под многомерным признаком понимается р -мерный вектор 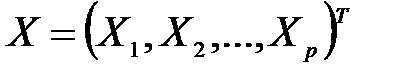 признаков
признаков  , среди которых могут быть количественные, порядковые и классификационные. Результаты измерения этих показателей
, среди которых могут быть количественные, порядковые и классификационные. Результаты измерения этих показателей  на каждом из n объектов исследуемой совокупности образуют последовательность многомерных наблюдений, или исходный массив многомерных данных для проведения многомерного статистического анализа. В рамках многомерного статистического анализа многомерный признак х интерпретируется как многомерная случайная величина, и соответственно, последовательность многомерных наблюдений как выборка из генеральной совокупности.
на каждом из n объектов исследуемой совокупности образуют последовательность многомерных наблюдений, или исходный массив многомерных данных для проведения многомерного статистического анализа. В рамках многомерного статистического анализа многомерный признак х интерпретируется как многомерная случайная величина, и соответственно, последовательность многомерных наблюдений как выборка из генеральной совокупности.
К основным методам многомерного статистического анализа можно отнести кластерный анализ, дискриминантный анализ, компонентный анализ, факторный анализ и метод канонических корреляций. Данные методы имеют достаточно сложный математический аппарат и обычно являются частью статистических пакетов прикладных программ.
Кластерный анализ – это совокупность методов классификации многомерных наблюдений или объектов, основанных на определении понятия расстояния между объектами с последующим выделением из них групп, «сгустков» наблюдений (кластеров, таксонов). При этом не требуется априорной информации о распределении генеральной совокупности. Выбор конкретного метода кластерного анализа зависит от цели классификации. Кластерный анализ используется при исследовании структуры совокупностей социально-экономических показателей или объектов: предприятий, регионов, социологических анкет и т.д.
|
|
|
От матрицы исходных данных 

 (5.1)
(5.1)
переходим к матрице нормированных значений Z c элементами  , (5.2)
, (5.2)
где j =1,2,…, k – номер показателя, i =1,2,…, n – номер наблюдения;
 =
= 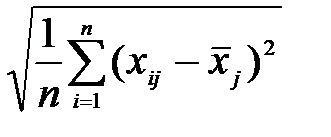 =
=  . (5.3)
. (5.3)
В качестве расстояния между двумя наблюдениями  и
и  используют «взвешенное» евклидово расстояние, определяемое по формуле:
используют «взвешенное» евклидово расстояние, определяемое по формуле:
 , где
, где 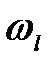 -«вес» показателя;
-«вес» показателя;  .
.
Если 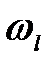 =1 для всех l =1,2,. k, то получаем обычное евклидово расстояние:
=1 для всех l =1,2,. k, то получаем обычное евклидово расстояние:
 (5.4)
(5.4)
Полученные значения удобно представить в виде матрицы расстояний


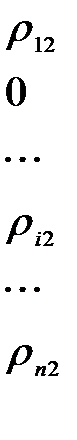


 (5.5)
(5.5)
Так как матрица R симметрическая, т.е.  , то достаточно ограничиться записью наддиагональных элементов матрицы.
, то достаточно ограничиться записью наддиагональных элементов матрицы.
Используя матрицу расстояний, можно реализовать агломеративную иерархическую процедуру кластерного анализа. Расстояния между кластерами определяют по принципу «ближайшего соседа» или «дальнего соседа». В первом случае за расстояние между кластерами принимают расстояние между ближайшими элементами этих кластеров, а во втором- между наиболее удаленными друг от друга.
Принцип работы иерархических агломеративных процедур состоит в последовательном объединении групп элементов сначала самых близких, а затем все более отдаленных друг от друга. На первом шаге алгоритма каждое наблюдение  ,
,  , рассматривается как отдельный кластер. В дальнейшем на каждом шаге работы алгоритма происходит объединение двух самых близких кластеров, и вновь строится матрица расстояний, размерность которой снижается на единицу.
, рассматривается как отдельный кластер. В дальнейшем на каждом шаге работы алгоритма происходит объединение двух самых близких кластеров, и вновь строится матрица расстояний, размерность которой снижается на единицу.
Компонентный анализ предназначен для преобразования системы k исходных признаков в систему k новых показателей (главных компонент). Главные компоненты не коррелированны между собой и упорядочены по величине их дисперсий, причем первая главная компонента имеет наибольшую дисперсию, а последняя, k – я, - наименьшую.
|
|
|
В задачах снижения размерности и классификации обычно используется m первых компонент ( ). При наличии результативного показателя Y может быть построено уравнение регрессии на главных компонентах.
). При наличии результативного показателя Y может быть построено уравнение регрессии на главных компонентах.
Для простоты изложения алгоритма ограничимся случаем трех переменных.
На основании матрицы исходных данных



 ,
,  (5.6)
(5.6)
вычисляем оценки параметров распределения трехмерной генеральной совокупности  ,
,  ,
,  , где
, где  =
=  ;
;  ;
;
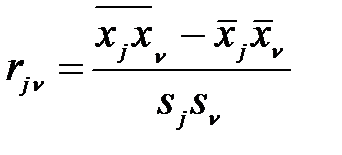 ;
; 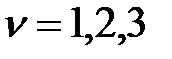 . (5.7)
. (5.7)
Получаем оценку матрицы парных коэффициентов корреляции: 

 .
.
Преобразуем матрицу R в диагональную матрицу  собственных значений характеристического многочлена
собственных значений характеристического многочлена  .
.
Характеристический многочлен имеет вид
 =
= 

 =
=  , (5.8)
, (5.8)
где E – единичная матрица.
Приняв  , получим неполное кубическое уравнение
, получим неполное кубическое уравнение  , (5.9)
, (5.9)
где  ,
,  .
.
Решая это уравнение и учитывая выполнение неравенства  <0, получим:
<0, получим:  ,
,  , (5.10)
, (5.10)
где  . (5.11)
. (5.11)
Отсюда получаем собственные значения  , причем
, причем  и матрицу собственных значений
и матрицу собственных значений 

 . (5.12)
. (5.12)
Собственные значения характеризуют вклады соответствующих главных компонент в суммарную дисперсию исходных признаков  . Таким образом, первая главная компонента оказывает наибольшее влияние на общую вариацию, а третья – наименьшее. При этом должно выполняться равенство
. Таким образом, первая главная компонента оказывает наибольшее влияние на общую вариацию, а третья – наименьшее. При этом должно выполняться равенство  . Вклад l -й главной компоненты в суммарную дисперсию определяется по формуле
. Вклад l -й главной компоненты в суммарную дисперсию определяется по формуле  .
.
Найдем теперь матрицу преобразования V - ортогональную матрицу, составленную из собственных векторов матрицы R. Собственный вектор  , отвечающий собственному числу
, отвечающий собственному числу  , находим как отличное от нуля решение уравнения
, находим как отличное от нуля решение уравнения  . Так как определитель =0, то можно считать, что третья строка есть линейная комбинация первых двух строк. Составим два уравнения
. Так как определитель =0, то можно считать, что третья строка есть линейная комбинация первых двух строк. Составим два уравнения
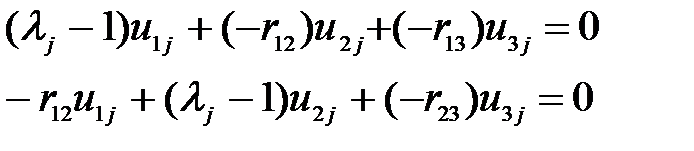 (5.13)
(5.13)
Примем  и получим решение системы двух уравнений с двумя неизвестными.
и получим решение системы двух уравнений с двумя неизвестными.
 (5.14)
(5.14)
Тогда окончательно собственный вектор  имеет вид
имеет вид
 для j =1,2,3. (5.15)
для j =1,2,3. (5.15)
Находим норму вектора  . Тогда матрица V, составленная из нормированных векторов
. Тогда матрица V, составленная из нормированных векторов  , (5.16)
, (5.16)
имеет вид 

 (5.17)
(5.17)
и является ортогональной  .
.
Матрица факторных нагрузок получается по формуле

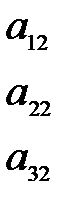
 , (5.18)
, (5.18)
где  - диагональная матрица:
- диагональная матрица: 

 (5.19)
(5.19)
Таким образом, нагрузка l -й главной компоненты 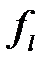 на j -ю переменную
на j -ю переменную 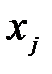 вычисляется по формуле:
вычисляется по формуле:  ; j =1,2,3; l =1,2,3.
; j =1,2,3; l =1,2,3.
|
|
|
Элемент матрицы факторных нагрузок  есть коэффициент корреляции, который измеряет тесноту связи между l -й главной компонентой и -м признаком
есть коэффициент корреляции, который измеряет тесноту связи между l -й главной компонентой и -м признаком  . При этом имеет место соотношение:
. При этом имеет место соотношение:  .
.
Матрица факторных нагрузок A используется для экономической интерпретации главных компонент, которые представляют собой линейный функции исходных признаков. Значения главных компонент для каждого i- объекта  задаются матрицей F. Матрицу значений главных компонент можно получить по формуле:
задаются матрицей F. Матрицу значений главных компонент можно получить по формуле:

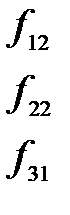

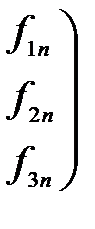 , где (5.20)
, где (5.20)
Z- матрица нормированных значений наблюдаемых переменных  размером
размером  .
.
Таким образом, значения главных компонент получаем из выражения
 , (5.21)
, (5.21)
где  ,
,  ; l =1,2,3.
; l =1,2,3.
Полученные главные компоненты позволяют классифицировать множество исходных признаков на группы, обобщающими показателями которых и являются главные компоненты. В силу ортогональности (независимости) главные компоненты удобны для построения на них уравнения регрессии ввиду отсутствия мультиколлинеарности главных компонент. Для построения уравнения регрессии на главных компонентах в качестве исходных данных следует взять вектор наблюдаемых значений результативного признака y и вместо матрицы значений исходных показателей X – матрицу вычисленных значений главных компонент F.
|
|
|
