 |


Простая статистическая совокупность. Статистическая функция распределения
|
|
|
|
Предположим, что изучается некоторая случайная величина 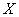 , закон распределения которой в точности неизвестен, и требуется определить этот закон из опыта или проверить экспериментально гипотезу о том, что величина подчинена тому или иному закону. С этой целью над случайной величиной производится ряд независимых опытов (наблюдений). В каждом из этих опытов случайная величина принимает определенное значение. Совокупность наблюденных значений величины и представляет собой первичный статистический материал, подлежащий обработке, осмыслению и научному анализу. Такая совокупность называется «простой статистической совокупностью» или «простым статистическим рядом». Обычно простая статистическая совокупность оформляется в виде таблицы с одним входом, в первом столбце которой стоит номер опыта
, закон распределения которой в точности неизвестен, и требуется определить этот закон из опыта или проверить экспериментально гипотезу о том, что величина подчинена тому или иному закону. С этой целью над случайной величиной производится ряд независимых опытов (наблюдений). В каждом из этих опытов случайная величина принимает определенное значение. Совокупность наблюденных значений величины и представляет собой первичный статистический материал, подлежащий обработке, осмыслению и научному анализу. Такая совокупность называется «простой статистической совокупностью» или «простым статистическим рядом». Обычно простая статистическая совокупность оформляется в виде таблицы с одним входом, в первом столбце которой стоит номер опыта  , а во втором – наблюденное значение случайной величины.
, а во втором – наблюденное значение случайной величины.
Пример 1. Случайная величина  - угол скольжения самолета в момент сбрасывания бомбы (под углом скольжения подразумевается угол, составленный вектором скорости и плоскостью симметрии самолета). Произведено 20 бомбометаний, в каждом из которых зарегистрирован угол скольжения в тысячных долях радиана. Результаты наблюдений сведены в простой статистический ряд:
- угол скольжения самолета в момент сбрасывания бомбы (под углом скольжения подразумевается угол, составленный вектором скорости и плоскостью симметрии самолета). Произведено 20 бомбометаний, в каждом из которых зарегистрирован угол скольжения в тысячных долях радиана. Результаты наблюдений сведены в простой статистический ряд:
|
| 
|
|
|
|
|
| -20 -60 -10 -10 | -30 -100 -80 -60 | -10 -80 |
Простой статистический ряд представляет собой первичную форму записи статистического материала и может быть обработан различными способами. Одним из способов такой обработки является построение статистическойфункции распределения случайной величины.
Статистической функцией распределения случайной величины называется частота события  в данном статистическом материале:
в данном статистическом материале:
|
|
|
 . (7.2.1)
. (7.2.1)
Для того чтобы найти значение статистической функции распределения при данном 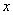 , достаточно подсчитать число опытов, в которых величина приняла значение, меньшее чем , и разделить на общее число
, достаточно подсчитать число опытов, в которых величина приняла значение, меньшее чем , и разделить на общее число 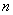 произведенных опытов.
произведенных опытов.
Пример 2. Построить статистическую функцию распределения для случайной величины , рассмотренной в предыдущем примере.
Решение. Так как наименьше наблюденное значение величины равно  , то
, то  . Значение наблюдено один раз, его частота равна
. Значение наблюдено один раз, его частота равна  ; следовательно, в точке
; следовательно, в точке  имеет скачок, равный . В промежутке от до
имеет скачок, равный . В промежутке от до  функция имеет значение ; в точке происходит скачок функции на
функция имеет значение ; в точке происходит скачок функции на  , так как значение наблюдено дважды и т.д.
, так как значение наблюдено дважды и т.д.
График статистической функции распределения величины представлен на рис.7.2.1.

Рис. 7.2.1
Статистическая функция распределения любой случайной величины - прерывной или непрерывной - представляет собой прерывную ступенчатую функцию, скачки которой соответствуют наблюденным значениям случайной величины и по величине равны частотам этих значений. Если каждое отдельное значение случайной величины было наблюдено только один раз, скачок статистической функции распределения в каждом наблюденном значении равен  , где - число наблюдений.
, где - число наблюдений.
При увеличении числа опытов , согласно теореме Бернулли, при любом частота события приближается (сходится по вероятности) к вероятности этого события. Следовательно, при увеличении статистическая функция распределения  приближается (сходится по вероятности) к подлинной функции распределения
приближается (сходится по вероятности) к подлинной функции распределения  случайной величины .
случайной величины .
Если - непрерывная случайная величина, то при увеличении числа наблюдений число скачков функции увеличивается, самые скачки уменьшаются и график функции неограниченно приближается к плавной кривой - функции распределения величины .
В принципе построение статистической функции распределения уже решает задачу описания экспериментального материала. Однако при большом числе опытов построение описанным выше способом весьма трудоемко. Кроме того, часто бывает удобно - в смысле наглядности - пользоваться другими характеристиками статистических распределений, аналогичными не функции распределения , а плотности  . С такими способами описания статистических данных мы познакомимся в следующем параграфе.
. С такими способами описания статистических данных мы познакомимся в следующем параграфе.
|
|
|
|
|
|
