 |


Кодирование информации в компьютере
|
|
|
|
В современных компьютерах используется двоичная форма представления данных, содержащая всего две цифры – 0 и 1. Такая форма позволяет создать достаточно простые технические устройства для представления (кодирования) и распознавания (дешифровки) информации. Двоичное кодирование выбрали потому, чтобы максимально упростить конструкцию декодирующей машины, ведь дешифратор должен уметь различать всего два состояния – 0 и 1. Например, 1 - есть ток в цепи, 0 – нет тока в цепи. По этой причине двоичная система и нашла такое широкое распространение.
Современный компьютер может обрабатывать числовую, текстовую, графическую, звуковую и видео информацию. Все эти виды информации в компьютере представлены в двоичном коде, т.е. используется алфавит мощностью два (всего два символа 0 и 1). Такое кодирование принято называть двоичным, а сами логические последовательности нулей и единиц - машинным языком.
| Вид информации | Двоичный код |
| Числовая | 10110011 |
| Текстовая | |
| Графическая | |
| Звуковая | |
| Видео |
Каждая цифра машинного двоичного кода несет количество информации равное одному биту. Данный вывод можно сделать, рассматривая цифры машинного алфавита, как равновероятные события. При записи двоичной цифры можно реализовать выбор только одного из двух возможных состояний, а, значит, она несет количество информации равное 1 бит. Следовательно, две цифры несут информацию 2 бита, четыре разряда - 4 бита и т.д. Чтобы определить количество информации в битах, достаточно определить количество цифр в двоичном машинном коде.
Кодирование текстовой информации
Большая часть пользователей при помощи компьютера обрабатывает текстовую информацию, которая состоит из символов: букв, цифр, знаков препинания и др.
|
|
|
Для того чтобы закодировать 1 символ используют количество информации равное 1 байту, т.е. I=1 байт = 8 бит. При помощи формулы 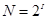 , которая связывает между собой количество возможных событий N и количество информации I, можно вычислить, сколько различных символов можно закодировать:
, которая связывает между собой количество возможных событий N и количество информации I, можно вычислить, сколько различных символов можно закодировать: 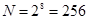 , т.е. для представления текстовой информации можно использовать алфавит мощностью 256 символов. Суть кодирования: каждому символу ставят в соответствие двоичный код от 00000000 до 11111111 или соответствующий ему десятичный код от 0 до 255.
, т.е. для представления текстовой информации можно использовать алфавит мощностью 256 символов. Суть кодирования: каждому символу ставят в соответствие двоичный код от 00000000 до 11111111 или соответствующий ему десятичный код от 0 до 255.
Для разных типов ЭВМ и операционных систем используются различные таблицы кодировки, отличающиеся порядком размещения символов алфавита в кодовой таблице. Международным стандартом на персональных компьютерах является уже упоминавшаяся таблица кодировки ASCII.
Принцип последовательного кодирования алфавита заключается в том, что в кодовой таблице ASCII латинские буквы (прописные и строчные) располагаются в алфавитном порядке. Расположение цифр также упорядочено по возрастанию значений. Стандартными в этой таблице являются только первые 128 символов, т.е. символы с номерами от нуля (двоичный код 00000000) до 127 (01111111). Сюда входят буквы латинского алфавита, цифры, знаки препинания, скобки и некоторые другие символы. Остальные 128 кодов, начиная со 128 (двоичный код 10000000) и кончая 255 (11111111), используются для кодировки букв национальных алфавитов, символов псевдографики и научных символов.
В настоящее время для кодировки русских букв используют пять различных кодовых таблиц (КОИ-8, СР1251, СР866, Мас, ISO), причем тексты, закодированные при помощи одной таблицы, не будут правильно отображаться в другой кодировке.
В большинстве случаев о перекодировке текстовых документов заботится не пользователь, а специальные программы - конверторы, которые встроены в приложения.
|
|
|
Начиная с 1997 г. последние версии Microsoft Windows и Office поддерживают новую кодировку Unicode, которая на каждый символ отводит по 2 байта, а, поэтому, можно закодировать не 256 символов, а 65536 различных символов.
|
|
|
