 |


Дискриминантный анализ как метод многомерной классификаций с обучением
|
|
|
|
Дискриминантный анализ является одним из методов многомерного статистического анализа. Цель дискриминантного анализа состоит в том, чтобы на основе различных характеристик (признаков, параметров) объекта классифицировать его, то есть отнести к одной из нескольких групп (классов) некоторым оптимальным способом. Отличительным свойством дискриминантного анализа является то, что исследователю заранее известно число групп (классов) на которые нужно разбить рассматриваемую совокупность объектов. Задача состоит в том, чтобы построить решающее правило, позволяющее по результатам измерений параметров объекта указать группу, к которой он принадлежит. Число групп заранее известно, также известно, что объект заведомо принадлежит к определенной группе. Такой метод классификации еще называется методом распознавания образов «с учителя».
Рассматривая задачу классификации при наличии обучающих выборок («классификации с обучением» как ее еще называют) в терминах статичного варианта задания исходных статистических данных на «входе» задачи нужно иметь n классифицируемых объектов, представленных данными вида:

Когда каждая i-я строка матрицы отражает значения p характеризующих i-й объект признаков  ,
,  ,…,
,…, 
Обучающие выборки  , j=1, 2,…,k, каждая j-я из которых определяет значения анализируемых признаков
, j=1, 2,…,k, каждая j-я из которых определяет значения анализируемых признаков 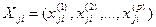 на
на  объектах (то есть i=1, 2,…,n), о которых априори известно, что все они принадлежат j-му классу, причем число k различных выборок равно общему числу всех возможных классов (так, что каждый класс представлен своей порцией выборочных данных).
объектах (то есть i=1, 2,…,n), о которых априори известно, что все они принадлежат j-му классу, причем число k различных выборок равно общему числу всех возможных классов (так, что каждый класс представлен своей порцией выборочных данных).
На «выходе» задачи мы должны иметь результат следующей формы: если число классов k и их смысл известен заранее, то каждое из n классифицируемых многомерных наблюдений должно быть снабжено «адресом» (номером) класса, к которому оно принадлежит.
|
|
|
Дискриминантный анализ применяется, когда исследователь имеет информацию о характере распределения в группах. При использовании дискриминантного анализа вначале формируются обучающие выборки, которые являются носителями информации о распределении внутри каждого класса. Данные обучающих выборок формируются на этапе предварительного анализа экспертами в конкретной рассматриваемой области. НА основе обучающих выборок определяются дискриминантные и классификационные функции, позволяющие с минимальной вероятностью ошибки отнести каждый объект к тому или иному классу.
Узловым моментом в задаче многомерной классификации является выбор метрики расстояния, от которого решающим образом зависит окончательный вариант разбиения объектов на классы при заданном алгоритме разбиения. При этом решение данного вопроса зависит в основном от цели исследования, физической и статистической природы k-мерного вектора наблюдений Х, полноты априорных сведений о характере вероятностного распределения Х. Здесь k – число рассматриваемых показателей.
Расстояние Махаланобиса.

Здесь k и l — номера объектов, xk, xl — их векторы признаков, С — ковариационная матрица признаков
Основные характеристики
Учитывает возможную корреляцию между переменными
Если корреляция между переменными отсутствует, то расстояние Махаланобиса равно расстоянию Евклида
Евклидово расстояние.
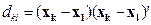
Здесь k и l — номера объектов, xk, xl — их векторы признаков
Основные характеристики
Каждая переменная вектора признаков дает одинаковый вклад наряду с остальными — считается что они ортогональны
Если между переменными имеется корреляция то они будут иметь непропорциональное влияние на результаты анализа
|
|
|
На первоначальном этапе анализа правильности формирования обучающих выборок, она проверяется на корректность на основе статистических критериев: расстояния Махаланобиса и апостериорной вероятности. Предполагая, что распределение внутри каждой группы подчиняется k-мерному нормальному закону распределения, опеределяется вероятность попадания отдельного i-Го наблюдения в каждую группу (апостериорная вероятность). Отнесение экспертом i-го объекта в j-ю группу считается ошибочным, если расстояние Махаланобиса от объекта до центра его группы значительно выше, чем от него до центра других групп, а апостериорная вероятность попадания в свою группу ниже критического значения. В этом случае объект считается некорректно отнесенным и должен быть исключен из выборки. После выполнения указанных расчетов составляется классификационная матрица, в которой указывается процент корректно отнесенных к группе наблюдений, а также число правильно и неправильно отнесенных объектов.
В дальнейшем из рассмотрения исключается не корректно отнесенной наблюдение, которому соответствует максимальное значение расстояния Махаланобиса и минимальная апостериорная вероятность правильной классификации. Для оставшихся n-1 наблюдений процедура тестирования повторяется.
Процедура исключения наблюдений продолжается до тех пор, пока общий коэффициент корректности в классификационной матрице не достигнет 100%, то есть все наблюдения обучающих выборок будут правильно отнесены к соответствующим группам.
Полученные на последнем шаге обучающие выборки используются для получения дискриминантных и классификационных функций (классификаторов), которые в дальнейшем могут использоваться для соотнесения новых объектов к той или иной группе.
содержание
Конец
|
|
|
