 |


Пример статистической обработки данных
|
|
|
|
Статобработка состоит в упорядочении выборочных наблюдений и при необходимости в группировке этих наблюдений по достаточно малым интервалам, в вычислении частостей (относительных частот) для каждого интервала, в определении числовых характеристик статистического распределения и графическом представлении результатов в виде гистограмм, полигонов и функций распределения.
После статобработки можно получить различные статистические характеристики (статистики). Среди них важнейшими являются: среднее арифметическое (выборочное среднее, статистическое среднее, средневзвешенное); выборочная дисперсия (статистическая дисперсия); выборочное среднее квадратическое отклонение (выборочное стандартное отклонение, выборочный стандарт).
Используют также такие характеристики: мода – значение случайной величины, имеющее наибольшую вероятность (значение признака, встречающееся с наибольшей частотой); медиана – значение случайной величины, при котором вероятность появления величины Xi, меньших X ср., равна вероятности появления величин, больших X (значение признака, относительно которого эмпирическая совокупность делится на две равные по числу членов части).
Кроме среднего арифметического (статистического начального момента первого порядка) и выборочной дисперсии (статистического центрального момента второго порядка) для оценки асимметрии используют центральный момент третьего порядка, а для характеристики эксцесса (остро вершинности) – центральный момент четвертого порядка.
Более полными характеристиками выборки, по сравнению с ранее рассмотренными, являются эмпирическая функция распределения, гистограмма и полигон.
|
|
|
Гистограмма является графическим представлением статистического ряда, она показывает количество измерений, попавших в каждый, одинаковый по величине интервал.
Эмпирическая функция распределения (статистическая функция распределения, кумулятивная кривая, функция накопленных частот) является статистическим аналогом распределения генеральной совокупности (теоретической функции распределения).
Если объем выборки увеличивается, то от статистических закономерностей можно перейти к вероятностным, так как при этом эмпирическая функция распределения приближается к теоретической функции распределения генеральной совокупности; среднее арифметическое (выборочное среднее) приближается к математическому ожиданию (которое является генеральной средней), а выборочная дисперсия – к дисперсии генеральной совокупности.
Одной из основных и часто выполняемых задач статистической обработки результатов испытаний (наблюдений) является построение (выбор) такого теоретического (вероятностного) распределения, которое наилучшим образом воспроизводило бы характерные признаки (особенности) экспериментального ряда. Такой переход от статистической модели к вероятностному распределению позволяет использовать информацию об аналогах при расчете надежности проектируемых новых устройств и систем.
Вероятностные законы распределения представляют или в виде функции распределения или в виде плотности распределения.
Функцию распределения иногда называют интегральной функцией, а плотность распределения вероятностей – дифференциальной функцией распределения.
Гистограмма при интегрировании принимает вид плавной кривой, которую называют графиком плотности распределения вероятностей (плотности распределения), а уравнение, описывающее его, законом распределения случайной величины.
Упорядочивание выборочных наблюдений состоит в расположении наблюдавшихся значений в порядке возрастания. Полученный ряд называют вариационным, или ранжированным.
|
|
|
Если число членов вариационного ряда велико, то для удобства его изучения наблюдавшиеся значения группируют по интервалам (классам), образуя интервальный ряд. Длину интервалов обычно берут одинаковой. Интервальный ряд может быть построен как для дискретных, так и непрерывных случайных величин.
Классическим примером, на основе которого были впервые получены многие положения математической статистики, является вычисление выборочных значений характеристик распределения признаков случайно составленной группы сверстников (например, группы новобранцев).
Наглядный пример вычисления Х ср, S, S несмещ., моментов и коэффициента вариации можно получить, если использовать данные наблюдения роста группы двадцатилетних юношей-студентов третьекурсников.
Обычно все вычисления в математической статистике производят в табличной форме, которая наиболее удобна, так как обладает наглядностью, обозримостью и позволяет проверять вычисления на каждом этапе (табл. 4.1).
В настоящее время, при наличии настольных компьютеров и карманных калькуляторов, заполнение таких таблиц не вызывает принципиальных трудностей.
В табл. 4.1 приведены цифры, соответствующие росту двадцатилетних юношей. При комплектовании лекционных потоков меньше всего учитывается рост студентов, поэтому выборку можно считать случайной.
Примером грубой ошибки в подобной ситуации было бы вычисление выборочных характеристик с использованием наблюдений роста солдат Преображенского полка царской гвардии.
Порядок выполнения работы
Необходимо выполнить статистическую обработку выборки размером n = 50.
Исходные данные для расчетов лабораторной работы выбираем из табл. 4.1 выборки размером n = 56, для которой дан пример расчета.
1. Аналогично табл. 4.1 чертим таблицу для исходных данных и результатов расчетов с учетом выборки n = 50. Заполняем только два первых столбца (№ и Х), остальные столбцы надо будет заполнить результатами своих расчетов.
Начало выборки соответствует номеру фамилии студента в журнале группы.
Например, № 13. Записываем для 1-го номера Х 1 = 189; для 2-го номера Х 2 = 172 и т.д. до конца таблицы, Х 44 = 177; затем переходим к началу таблицы Х 45 = 183 и далее до Х 50 = 180. В выборку не попадут 6 значений от № 7 до № 12.
|
|
|
2. Для построения гистограммы, полигона распределения и кумулятивной линии заполняем таблицу аналогичную табл. 4.2.
Если данные табл. 4.1 разделить на классы, то можно построить гистограмму и полигон частот.
Разбиение на классы можно выполнить по правилу Штюргеса (Старджеса).
Число классов
 .
.
В нашем случае для n = 56 число классов k = 1 + 3,32*1,75 = 6,81.
Для n = 50 число классов k = 1 + 3,32*1,70= 6,64.
Длина интервала составит l = (X max – X min)/ k.
С другой стороны размах варьирования составляет R = X max – Xmin= 189 – 166 = 23 см.
где X max и X min - соответственно максимальная и минимальная величины.
Исходя из этого, примем число классов равным 6 со ступенями, равными 4 см: 4х6 = 24 см. k = 6; l = 4 см. В дальнейшем, для упрощения записей, размерность «см» не указывается. Варианты (перечень интервалов для интервального ряда) и соответствующие им частоты (частости) образуют статистический ряд выборки.
Таблица 4.1
Варианты заданий: Исходные данные и результаты расчетов
| № | x | 
| 
| 
| 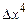
|
| + 7,34 | 53,88 | 395,45 | 2902,58 | ||
| - 5,66 | 32,04 | - 181,32 | 1026,28 | ||
| + 0,34 | 0,12 | 0,039 | 0,0134 | ||
| + 2,34 | 5,48 | 12,81 | 29,98 | ||
| + 0,34 | 0,12 | 0,039 | 0,0134 | ||
| + 4,34 | 18,84 | 81,75 | 354,78 | ||
| + 0,34 | 0,12 | 0,039 | 0,0134 | ||
| + 9,34 | 87,23 | 814,78 | 7610,05 | ||
| + 8,34 | 69,56 | 580,09 | 4837,98 | ||
| - 1,66 | 2,76 | - 4,57 | 7,59 | ||
| - 7,66 | 58,68 | - 449,46 | 3442,83 | ||
| - 1,66 | 2,76 | - 4,57 | 7,59 | ||
| +13,34 | 177,96 | 2373,93 | 31668,20 | ||
| - 3,66 | 13,40 | - 49,03 | 179,44 | ||
| - 0,66 | 0,44 | - 0,287 | 0,19 | ||
| - 8,66 | 75,00 | - 649,46 | 5624,34 | ||
| + 3,34 | 11,16 | 37,26 | 124,45 | ||
| + 0,34 | 0,12 | 0,039 | 0,0134 | ||
| - 6,66 | 44,35 | - 295,41 | 1967,42 | ||
| + 2,34 | 5,48 | 12,81 | 29,98 | ||
| - 6,66 | 44,36 | - 295,41 | 1967,42 | ||
| - 4,66 | 21,72 | - 101,19 | 471,57 | ||
| - 5,66 | 32,04 | - 181,32 | 1026,28 | ||
| + 1,34 | 1,80 | 2,41 | 3,22 | ||
| + 0,34 | 0,12 | 0,039 | 0,0134 | ||
| + 3,34 | 11,16 | 37,26 | 124,45 | ||
| - 1,66 | 2,76 | - 4,57 | 7,59 | ||
| + 0,34 | 0,12 | 0,039 | 0,0134 | ||
| +12,34 | 152,28 | 1879,08 | 23187,86 | ||
| + 2,34 | 5,48 | 12,81 | 29,98 | ||
| - 3,66 | 13,40 | - 49,03 | 179,44 | ||
| + 0,34 | 0,12 | 0,039 | 0,0134 | ||
| - 8,66 | 75,00 | - 649,46 | 5624,34 | ||
| - 9,66 | 93,32 | - 901,43 | 8707,80 | ||
| + 4,34 | 18,84 | 81,75 | 354,78 | ||
| + 7,34 | 53,88 | 395,45 | 2902,58 | ||
| + 0,34 | 0,12 | 0,039 | 0,0134 | ||
| + 6,34 | 40,19 | 254,84 | 1615,69 | ||
| + 2,34 | 5,48 | 12,81 | 29,98 | ||
| - 3,66 | 13,39 | - 49,03 | 179,44 | ||
| + 9,34 | 87,23 | 814,78 | 7610,05 | ||
| + 7,34 | 53,88 | 395,45 | 2902,58 | ||
| - 0,66 | 0,44 | - 0,287 | 0,19 | ||
| - 1,66 | 2,76 | - 4,57 | 7,59 | ||
| + 4,34 | 18,84 | 81,75 | 354,78 | ||
| - 9,66 | 93,32 | - 901,43 | 8707,80 | ||
| - 6,66 | 44,36 | - 295,41 | 1967,42 | ||
| - 4,66 | 21,72 | - 101,19 | 471,57 | ||
| + 2,34 | 5,48 | 12,81 | 29,98 | ||
| - 6,66 | 44,36 | - 295,41 | 1967,42 | ||
| - 5,66 | 32,04 | - 181,32 | 1026,28 | ||
| + 3,34 | 11,16 | 37,26 | 124,45 | ||
| - 4,66 | 21,72 | - 101,19 | 471,57 | ||
| + 2,34 | 5,48 | 12,81 | 29,98 | ||
| - 2,66 | 7,07 | - 18,82 | 50,06 | ||
| + 1,34 | 1,80 | 2,41 | 3,22 | ||
| ∑ | + 0,04 | 1695,90 | 2577,70 | 131951,25 |
|
|
|
Таблица 4.2
Разбивка массива исходных данных на классы, вычисление частот

Число наблюдений с одинаковым значением варианты называют частотой. Сумма частот равна объему выборки – n.
å h i = n.
Отношение частоты к объему выборки называют частостью (относительной частотой).
D h i = h i / n.
|
|
|
