 |


Методы, используемые при поиске и сортировке
|
|
|
|
T.П. Тюрина, В.И. Емельянов
Практикум по дискретной математике
(часть 1)
Учебно-методическое пособие
Новомосковск 2007
Оглавление
Введение....................................................................................................... 5
Практическая работа № 1 Изучение методов сортировки данных........... 6
1.1 Теоретическая часть............................................................................... 6
1.2 Методы, используемые при поиске и сортировке................................ 9
1.2.1 Основные понятия............................................................................... 9
1.2.2 Поиск................................................................................................. 10
1.2.3 Оценки времени исполнения............................................................. 18
1.2.4 Сортировки....................................................................................... 19
1.3 Практическая часть.............................................................................. 40
1.3.1 Содержание отчёта по практической работе................................... 40
1.3.2 Приложение на Delphi, в котором представлена работа некоторых методов сортировки и поиска.................................................................................. 40
1.3.3 Пример выполнения.......................................................................... 51
1.3.4 Варианты заданий............................................................................. 53
1.4 Вопросы для самопроверки................................................................ 62
Практическая работа № 2 Представление множеств в компьютере........ 64
2.1 Теоретическая часть............................................................................. 64
2.1.1 Множества и операции над ними..................................................... 64
2.1.2 Представление множеств и отношений в программах.................... 67
2.1.4 Представление множеств в приложениях на Delphi........................ 82
2.1.5 Характеристический вектор множества........................................... 83
2.2 Практическая часть.............................................................................. 85
2.2.1 Задание к работе............................................................................... 85
|
|
|
2.2.2 Примеры выполнения....................................................................... 86
2.2.3 Варианты заданий............................................................................. 90
2.3 Вопросы для самопроверки................................................................ 92
Практическая работа № 3 Элементы теории графов............................... 94
3.1 Теоретическая часть............................................................................. 94
3.2 Практическая часть............................................................................ 111
3.2.1 Задание к работе............................................................................. 111
3.2.2 Примеры выполнения..................................................................... 111
3.2.3 Вариантв заданий............................................................................ 117
Практическая работа № 4 Элементы теории множеств и алгебры логики 122
4.1 Указание к выполнению..................................................................... 122
4.2 Задание к работе................................................................................ 122
4.3 Практическая часть............................................................................ 122
4.4 Вопросы для самопроверки.............................................................. 133
Практическая работа № 5 Исследование логических функций............. 135
5.1 Задание к работе................................................................................ 135
5.2 Практическая часть............................................................................ 135
5.2.1 Пример выполнения........................................................................ 135
5.2.2 Варианты заданий........................................................................... 138
5.3 Вопросы для самопроверки.............................................................. 140
Практическая работа № 6 Изучение методов минимизации логических функций................................................................................................................... 142
6.1 Краткие теоретические сведения....................................................... 142
6.2 Практическая часть............................................................................ 144
6.2.1 Задание к работе............................................................................. 144
6.2.2 Примеры выполнения..................................................................... 144
6.3 Вопросы для самопроверки.............................................................. 147
Практическая работа № 7 Моделирование работы узлов компьютера с помощью Еxcel.......................................................................................................... 149
|
|
|
7.1 Теоретическая часть........................................................................... 149
7.2 Практическая часть............................................................................ 152
7.2.1 Схемы сравнения кодов.................................................................. 153
7.2.2 Дешифраторы.................................................................................. 158
7.3 Задания к работе................................................................................ 160
7.4 Вопросы для самопроверки.............................................................. 164
Список литературы.................................................................................. 165
Введение
В практикум включены необходимые теоретические сведения, содержание работ, примеры выполнения, варианты заданий, вопросы по самоконтролю знаний для 7 практических работ. Некоторые практические работы относятся к нескольким разделам дисциплины, поэтому для них можно, не «привязывая» к конкретному разделу, выполнять описание в виде отдельных приложений. Все практические работы выполняются с использованием компьютера.
Практическая часть дисциплины адаптирована для обучения будущих специалистов по обработке информации. Практикум содержит дополнительные сведения из теории множеств, теории графов и алгебры логики, описание практических работ, запланированных для выполнения студентами в процессе изучения предмета с привлечением средств Excel, Delphi.
Содержание пособия полностью соответствует требованиям программы дисциплины и относится к практической части. Подготовка рукописи вызвана необходимостью создания учебного пособия для студентов, т. к. подобные практикумы по дискретной математике отсутствуют. Практикум содержит краткое изложение теории, которая относится непосредственно к выполнению работ, варианты заданий, примеры выполнения. В конце каждого раздела приведены контрольные вопросы. Студенту предлагается выполнить индивидуальные задания.
Некоторые практические работы являются традиционными, и составные части их представлены в учебниках и методических разработках других вузов, основная часть является авторской. Недостатком является отсутствие практической работы по нечётким множествам. Пособие может быть рекомендовано студентам дневной и заочной форм обучения.
|
|
|
Практическая работа № 1. Изучение методов сортировки данных
Цель работы: изучение наиболее известных методов сортировки данных и их использование на примерах конкретных задач.
Теоретическая часть
Для дискретного анализа характерно, что самые простые, казалось бы, ничем не примечательные задачи могут быть предметом серьёзного научного исследования. Здесь мы рассматриваем одну из таких простых задач, которая часто встречается в приложениях, называется задачей сортировки и до сих пор остается интересной.
При рассмотрении данного круга задач необходимо предварительно изучить тему «Множества и отношения». Рефлексивное, транзитивное, но антисимметричное отношение R на множестве A называется частичным порядком. Частичный порядок важен в тех ситуациях, когда мы хотим как-то охарактеризовать старшинство. Иными словами, решить при каких условиях можно считать, что один элемент множества превосходит другой.
Примеры частичных порядков.
«£» на множестве вещественных чисел;
«Ì» на подмножествах универсального множества;
«…делит…» на множестве натуральных чисел.
Множества с частичным порядком принято называть частично упорядоченными множествами (ч. у. м.).
Если R – отношение частичного порядка на множестве A, то при х  y и xRy мы называем x предшествующим элементом или предшественником, а y – последующим. У произвольно взятого элемента y может быть много предшествующих элементов. Однако если x предшествует y, и не существует таких элементов z, для которых xRz и zRy, x называется непосредственным предшественником (иначе говорят, что y покрывает x) и обозначается x < y [3].
y и xRy мы называем x предшествующим элементом или предшественником, а y – последующим. У произвольно взятого элемента y может быть много предшествующих элементов. Однако если x предшествует y, и не существует таких элементов z, для которых xRz и zRy, x называется непосредственным предшественником (иначе говорят, что y покрывает x) и обозначается x < y [3].
Линейным порядком на множестве A называется отношение частичного порядка, при котором из любой пары элементов можно выделить предшествующий и последующий.
Постановка задачи: пусть задано конечное множество А, состоящее из n элементов ai, на нём задано отношение линейного порядка Р.
Требуется перенумеровать элементы А числами от 1 до n таким образом, чтобы из того, что i<j следовало (ai, aj) Є P. Выполнение этой задачи называется сортировкой массива данных [3].
|
|
|
Способы сравнения могут быть очень разнообразными, но в большинстве случаев они исходят из двух базовых элементарных упорядочений: упорядочение чисел по значению и упорядочение слов по алфавиту.
Потребность в сортировке больших объёмов данных ощущалась очень давно, например, в комплекте счётно-аналитических машин Холлерита была специальная сортирующая машина.
Во многих задачах требуется иметь данные, расположенные в порядке возрастания или в порядке убывания. Такое упорядочение в программировании называется сортировкой. Сортировка применяется во многих задачах. Существуют различные методы сортировки: одни из них просты, но более медленные, другие быстрые, но более сложные. Одни сортируют каждый массив заново, другие распознают уже упорядоченные части массива и поэтому работают быстрее.
Выдающийся специалист по программированию Д. Кнут посвятил сортировке и поиску данных почти весь второй том трудов «Искусство программирования для ЭВМ» [4].
Сортировка данных – обработка информации, в результате которой элементы её (записи) располагаются в определённой последовательности в зависимости от значения некоторых признаков элементов, называемых ключевыми.
Наиболее распространёнными видами сортировки данных являются упорядочение массива записей – расположение записей сортируемого массива данных в порядке монотонного изменения значения ключевого признака. Сортировка данных позволяет сократить в десятки раз продолжительность решения задач, связанных с обработкой больших массивов записей. Такое ускорение происходит за счёт сокращения времени поиска записей с определёнными значениями ключевых признаков. Упорядочение осуществляется в процессе многократного просмотра исходного массива.
Одними из важнейших процедур обработки структурированной информации являются сортировка и поиск. Сортировкой также называют процесс перегруппировки заданной последовательности (кортежа) объектов в некотором определенном порядке. Определенный порядок (например, упорядочение в алфавитном порядке, по возрастанию или убыванию количественных характеристик, по классам, типам и т. п.) в последовательности объектов необходим для удобства работы с этими объектами. В частности, одной из целей сортировки является облегчение последующего поиска элементов в отсортированном множестве. Под поиском подразумевается процесс нахождения в заданном множестве объекта, обладающего свойствами или качествами задаваемого априори эталона (или шаблона).
|
|
|
Например, требуется решить задачу: даны целые числа x, a 1, a 2, …, an (n >0). Определить, каким по счёту идёт в последовательности a 1, a 2, …, an член, равный x. Если такого члена нет, то предусмотреть соответствующее сообщение.
В этом примере мы сталкиваемся с задачей поиска. «Одно из наиболее часто встречающихся в программировании действий – поиск. Он же представляет собой идеальную задачу, на которой можно испытывать различные структуры данных…» – пишет Н. Вирт [14]. Теория поиска – важный раздел теории информации.
Очевидно, что с отсортированными (упорядоченными) данными работать намного легче, чем с произвольно расположенными. Упорядоченные данные позволяют эффективно их обновлять, исключать, искать нужный элемент и т. п. Достаточно представить, например, словари, справочники, списки кадров в неотсортированном виде и сразу становится ясным, что поиск нужной информации является труднейшим делом.
Методы, используемые при поиске и сортировке
Основные понятия
Существуют различные алгоритмы сортировки данных. И понятно, что не существует универсального, наилучшего во всех отношениях алгоритма сортировки. Эффективность алгоритма зависит от множества факторов, среди которых можно выделить основные:
– числа сортируемых элементов;
– степени начальной отсортированности (диапазона и распределения значений сортируемых элементов);
– необходимости исключения или добавления элементов;
– доступа к сортируемым элементам (прямого или последовательного). Принципиальным для выбора метода сортировки является последний фактор [16].
Если данные могут быть расположены в оперативной памяти, то к любому элементу возможен прямой доступ. Удобной структурой данных в этом случае выступает массив сортируемых элементов. Если данные размещены на внешнем носителе в файле последовательного доступа, то к ним можно обращаться последовательно. В качестве структуры подобных данных можно взять файловый тип [9].
В этой связи выделяют сортировку двух классов объектов: массивов (внутренняя сортировка) и файлов (внешняя сортировка).
Процедура сортировки предполагает, что при наличии некоторой упорядочивающей функции F расположение элементов исходного множества меняется таким образом, что

 ,
,
где знак неравенства понимается в смысле того порядка, который установлен в сортируемом множестве.
Поиск и сортировка являются классическими задачами теории обработки данных, решают эти задачи с помощью множества различных алгоритмов. Рассмотрим наиболее популярные из них.
Поиск
Для определенности примем, что множество, в котором осуществляется поиск, задано как массив:
var a: array [0..N] of item;
где item – заданный структурированный тип данных, обладающий хотя бы одним полем (ключом), по которому необходимо проводить поиск.
Результатом поиска, как правило, служит элемент массива, равный эталону, или отсутствие такового.
Важно знать и про ассоциативную память. Это можно понимать как деление памяти на порции (называемые записями), и с каждой записью ассоциируется ключ. Ключ – это значение из некоторого вполне упорядоченного множества, а записи могут иметь произвольную природу и различные параметры. Доступ к данным осуществляется по значению ключа, которое обычно выбирается простым, компактным и удобным для работы.
Дерево сортировки – бинарное дерево, каждый узел которого содержит ключ и обладает следующим свойством: значения ключа во всех узлах левого поддерева меньше, а во всех узлах правого поддерева больше, чем значение ключа в узле.
Таблица расстановки.
Поиск, вставка и удаление, как известно, – основные операции при работе с данными [16]. Мы начнем с исследования того, как эти операции реализуются над самыми известными объектами – массивами и (связанными) списками.
Массивы
На рисунке 1.1 показан массив из семи элементов с числовыми значениями. Чтобы найти в нем нужное нам число, мы можем использовать линейный поиск (процедура представлена на псевдокоде, подобном языку Паскаль):
int function SequentialSearch (Array A, int Lb, int Ub, int Key);
begin
for i = Lb to Ub do
if A (i) = Key then
return i;
return –1;
end;
Максимальное число сравнений при таком поиске – 7; оно достигается в случае, когда нужное нам значение находится в элементе A[6]. Различают поиск в упорядоченном и неупорядоченном массивах. В неупорядоченном массиве, если нет никакой дополнительной информации об элементе поиска, его выполняют с помощью последовательного просмотра всего массива и называют линейным поиском. Рассмотрим программу, реализующую линейный поиск. Очевидно, что в любом случае существуют два условия окончания поиска: 1) элемент найден; 2) весь массив просмотрен, и элемент не найден. Приходим к программе:
While (a[i]<>x) and (i<n) do Inc(i);
If a[i]<>x then Write (‘Заданного элемента нет’)
Если известно, что данные отсортированы, можно применить двоичный поиск:
int function BinarySearch (Array A, int Lb, int Ub, int Key);
begin
do forever
M = (Lb + Ub)/2;
if (Key < A[M]) then
Ub = M – 1;
else if (Key > A[M]) then
Lb = M + 1;
else
return M;
if (Lb > Ub) then
return –1;
end;
Переменные Lb и Ub содержат, соответственно, верхнюю и нижнюю границы отрезка массива, где находится нужный нам элемент. Мы начинаем всегда с исследования среднего элемента отрезка. Если искомое значение меньше среднего элемента, мы переходим к поиску в верхней половине отрезка, где все элементы меньше только что проверенного. Другими словами, значением Ub становится равным (M – 1) и на следующей итерации мы работаем с половиной массива. Таким образом, в результате каждой проверки мы вдвое сужаем область поиска. Так, в нашем примере, после первой итерации область поиска – всего лишь три элемента, после второй остается всего лишь один элемент. Таким образом, если длина массива равна 6, нам достаточно трех итераций, чтобы найти нужное число.

Рисунок 1.1 – Массив
Двоичный поиск – очень мощный метод. Если, например, длина массива равна 1023, после первого сравнения область сужается до 511 элементов, а после второй – до 255. Легко посчитать, что для поиска в массиве из 1023 элементов достаточно 10 сравнений.
Кроме поиска нам необходимо бывает вставлять и удалять элементы. К сожалению, массив плохо приспособлен для выполнения этих операций. Например, чтобы вставить число 18 в массив на рисунке 1.1, нам понадобится сдвинуть элементы A [3]… A [6] вниз – лишь после этого мы сможем записать число 18 в элемент A [3]. Аналогичная проблема возникает при удалении элементов. Для повышения эффективности операций вставки / удаления предложены связанные списки.
Иначе двоичный поиск (бинарный поиск) называют поиском делением пополам. В большинстве случаев процедура поиска применяется к упорядоченным данным (телефонный справочник, библиотечные каталоги и пр.).
Односвязные списки
На рисунке 1.2 те же числа, что и раньше, хранятся в виде связанного списка; слово «связанный» часто опускают. Предполагая, что X и P являются указателями, число 18 можно вставить в такой список следующим образом:
X->Next = P->Next;
P->Next = X;
Списки позволяют осуществить вставку и удаление очень эффективно. Поинтересуемся, однако, как найти место, куда мы будем вставлять новый элемент, т. е. каким образом присвоить нужное значение указателю P. Увы, для поиска нужной точки придется пройтись по элементам списка. Таким образом, переход к спискам позволяет уменьшить время вставки / удаления элемента за счет увеличения времени поиска.

Рисунок 1. 2 – Односвязный список
Поиск в бинарных деревьях
Мы использовали двоичный поиск для поиска данных в массиве. Этот метод чрезвычайно эффективен, поскольку каждая итерация вдвое уменьшает число элементов, среди которых нам нужно продолжать поиск. Однако операции вставки и удаления элементов не столь эффективны. Двоичные деревья позволяют сохранить эффективность всех трех операций – если работа идет со «случайными» данными. В этом случае время поиска оценивается как O (lg n). Наихудший случай – когда вставляются упорядоченные данные. В этом случае оценка время поиска – O (n).
Двоичное дерево – это дерево, у которого каждый узел имеет не более двух наследников. Пример бинарного дерева приведен на рисунке 1.5. Предполагая, что Key содержит значение, хранимое в данном узле, мы можем сказать, что бинарное дерево обладает следующим свойством: у всех узлов, расположенных слева от данного узла, значение соответствующего поля меньше, чем Key, у всех узлов, расположенных справа от него, – больше. Вершину дерева называют его корнем. Узлы, у которых отсутствуют оба наследника, называются листьями. Корень дерева на рисунке 1.3 содержит число 20, а листья – 4, 16, 37 и 43. Высота дерева – это длина наидлиннейшего из путей от корня к листьям. В нашем примере высота дерева равна 2.
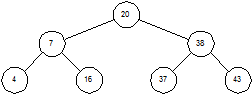
Рисунок 1.3 – Двоичное дерево
Чтобы найти в дереве какое-то значение, мы стартуем из корня и движемся вниз. Например, для поиска числа 16, мы замечаем, что 16 < 20, и потому идем влево. При втором сравнении имеем 16 > 7, так что мы движемся вправо. Третья попытка успешна – мы находим элемент с ключом, равным 16.
Каждое сравнение вдвое уменьшает количество оставшихся элементов. В этом отношении алгоритм похож на двоичный поиск в массиве. Однако, все это верно только в случаях, когда наше дерево сбалансировано. На рисунке 1.4 показано другое дерево, содержащее те же элементы. Несмотря на то, что это дерево тоже бинарное, поиск в нем похож, скорее, на поиск в односвязном списке, время поиска увеличивается пропорционально числу запоминаемых элементов.
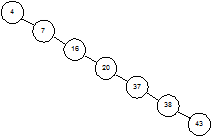
Рисунок 1.4 – Несбалансированное бинарное дерево
Вставка и удаление
Чтобы лучше понять, как дерево становится несбалансированным, посмотрим на процесс вставки пристальнее. Чтобы вставить 18 в дерево на рисунке 1.3 мы ищем это число. Поиск приводит нас в узел 16, где благополучно завершается. Поскольку 18 > 16, мы попросту добавляет узел 18 в качестве правого потомка узла 16 (рисунок 1.5).
Теперь мы видим, как возникает несбалансированность дерева. Если данные поступают в возрастающем порядке, каждый новый узел добавляется справа от последнего вставленного. Это приводит к одному длинному списку. Обратите внимание: чем более «случайны» поступающие данные, тем более сбалансированным получается дерево.
Удаления производятся примерно так же – необходимо только позаботиться о сохранении структуры дерева. Например, если из дерева на рисунке 1.5 удаляется узел 20, его сначала нужно заменить на узел 37. Это даст дерево, изображенное на рисунок 1.6. Рассуждения здесь примерно следующие. Нам нужно найти потомка узла 20, справа от которого расположены узлы с большими значениями. Таким образом, нам нужно выбрать узел с наименьшим значением, расположенный справа от узла 20. Чтобы найти его, нам и нужно сначала спуститься на шаг вправо (попадаем в узел 38), а затем на шаг влево (узел 37); эти двухшаговые спуски продолжаются, пока мы не придем в концевой узел, лист дерева.
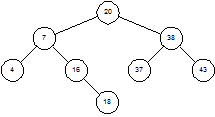 Рисунок 1.5 – Бинарное дерево после добавления узла 18
Рисунок 1.5 – Бинарное дерево после добавления узла 18
|  Рисунок 1.6 – Бинарное дерево после удаления узла 20
Рисунок 1.6 – Бинарное дерево после удаления узла 20
|
Разделенные списки
Разделенные списки – это связные списки, которые позволяют вам прыгнуть (skip) к нужному элементу. Это позволяет преодолеть ограничения последовательного поиска, являющегося основным источником неэффективного поиска в списках. В то же время вставка и удаление остаются сравнительно эффективными. Оценка среднего времени поиска в таких списках есть O (lg n). Для наихудшего случая оценкой является O (n), но худший случай крайне маловероятен.
Идея, лежащая в основе разделенных списков, очень напоминает метод, используемый при поиске имен в адресной книжке. Чтобы найти имя, вы помечаете буквой страницу, откуда начинаются имена, начинающиеся с этой буквы. На рисунке 1.6, например, самый верхний список представляет обычный односвязный список. Добавив один «уровень» ссылок, мы ускорим поиск. Сначала мы пойдем по ссылкам уровня 1, затем, когда дойдем до нужного отрезка списка, пойдем по ссылкам нулевого уровня.
Эта простая идея может быть расширена – мы можем добавить нужное число уровней. Внизу на рисунке 1.6 мы видим второй уровень, который позволяет двигаться еще быстрее первого. При поиске элемента мы двигаемся по этому уровню, пока не дойдем до нужного отрезка списка. Затем мы еще уменьшаем интервал неопределенности, двигаясь по ссылкам 1‑го уровня. Лишь после этого мы проходим по ссылкам 0‑го уровня.
Вставляя узел, нам понадобится определить количество исходящих от него ссылок. Эта проблема легче всего решается с использованием случайного механизма: при добавлении нового узла мы «бросаем монету», чтобы определить, нужно ли добавлять еще слой. Например, мы можем добавлять очередные слои до тех пор, пока выпадает «решка». Если реализован только один уровень, мы имеем дело фактически с обычным списком и время поиска есть O (n). Однако если имеется достаточное число уровней, разделенный список можно считать деревом с корнем на высшем уровне, а для дерева время поиска есть O (lg n).
Поскольку реализация разделенных списков включает в себя случайный процесс, для времени поиска в них устанавливаются вероятностные границы. При обычных условиях эти границы довольно узки. Например, когда мы ищем элемент в списке из 1000 узлов, вероятность того, что время поиска окажется в 5 раз больше среднего, можно оценить как 1/ 1,000,000,000,000,000,000 (рисунок 1.7).

Рисунок 1.7 – Устройство разделенного списка
Оценки времени исполнения
Для оценки эффективности алгоритмов можно использовать разные подходы. Самый бесхитростный – просто запустить каждый алгоритм на нескольких задачах и сравнить время исполнения. Другой способ – оценить время исполнения. Например, мы можем утверждать, что время поиска есть O (n) (читается так: о большое от n). Это означает, что при больших n время поиска не сильно больше, чем количество элементов. Когда используют обозначение O (), имеют в виду не точное время исполнения, а только его предел сверху, причем с точностью до постоянного множителя. Когда говорят, например, что алгоритму требуется время порядка O (n 2), имеют в виду, что время исполнения задачи растет не быстрее, чем квадрат количества элементов. Чтобы почувствовать, что это такое, посмотрите таблицу 1.1, где приведены числа, иллюстрирующие скорость роста для нескольких разных функций. Скорость роста O (log 2 n) характеризует алгоритмы типа двоичного поиска.
Таблица 1.1 – Скорость роста нескольких функций O()
| n | log2 n | n log2 n | n 1.25 | n 2 |
| 1 | 0 | 0 | 1 | 1 |
| 16 | 4 | 64 | 32 | 256 |
| 256 | 8 | 2,048 | 1,024 | 65,536 |
| 4,096 | 12 | 49,152 | 32,768 | 16,777,216 |
| 65,536 | 16 | 1,048,565 | 1,048,476 | 4,294,967,296 |
| 1,048,476 | 20 | 20,969,520 | 33,554,432 | 1,099,301,922,576 |
| 16,775,616 | 24 | 402,614,784 | 1,073,613,825 | 281,421,292,179,456 |
Если считать, что числа в таблице 1.1 соответствуют микросекундам, то для задачи с 1048476 элементами алгоритму со временем работы O (log 2 n) потребуется 20 микросекунд, алгоритму со временем работы O (n 1.25) – порядка 33 секунд, алгоритму со временем работы O (n 2) – более 12 дней. В нижеследующем тексте для каждого алгоритма приведены соответствующие O ‑оценки. Более точные формулировки и доказательства можно найти в [12], [15].
Как мы видели, если массив отсортирован, то искать его элементы необходимо с помощью двоичного поиска. Однако не забудем, что массив должен быть отсортированным! В следующем разделе мы исследует разные способы сортировки массива. Оказывается, эта задача встречается достаточно часто и требует заметных вычислительных ресурсов, поэтому сортирующие алгоритмы исследованы вдоль и поперек, известны алгоритмы, эффективность которых достигла теоретического предела.
Связанные списки позволяют эффективно вставлять и удалять элементы, но поиск в них последователен и потому отнимает много времени. Имеются алгоритмы, позволяющие эффективно выполнять все три операции.
Сортировки
Сортировка вставками
Один из простейших способов отсортировать массив – сортировка вставками. В обычной жизни мы сталкиваемся с этим методом при игре в карты. Чтобы отсортировать имеющиеся у вас карты, вы вынимаете карту, сдвигаете оставшиеся карты, а затем вставляете карту на нужное место. Процесс повторяется до тех пор, пока хоть одна карта находится не на месте. Как среднее, так и худшее время для этого алгоритма – O (n 2). Дальнейшую информацию можно получить в книге Кнута [4].
На рисунке 1.8 (a) мы вынимаем элемент 3. Затем элементы, расположенные выше, сдвигаем вниз – до тех пор, пока не найдем место, куда нужно вставить 3. Это процесс продолжается на рисунке 1.8 (b) для числа 1. Наконец, на рисунке 1.8 (c) мы завершаем сортировку, поместив 2 на нужное место.

Рисунок 1.8 – Сортировка вставками
Если длина нашего массива равна n, нам нужно пройтись по n – 1 элементам. Каждый раз нам может понадобиться сдвинуть n – 1 других элементов. Вот почему этот метод требует довольно-таки много времени.
Сортировка вставками относится к числу методов сортировки по месту. Другими словами, ей не требуется вспомогательная память, мы сортируем элементы массива, используя только память, занимаемую самим массивом. Кроме того, она является устойчивой – если среди сортируемых ключей имеются одинаковые, после сортировки они остаются в исходном порядке.
Сортировка с помощью включения
Кто играл в карты, процедуру сортировки включениями осуществлял многократно. Как правило, после раздачи карт игрок, держа карты веером в руке, переставляет карты с места на место, стремясь их расположить по мастям и рангам, например, сначала все тузы, затем короли, дамы и т. д. Элементы (карты) мысленно делятся на уже «готовую последовательность» и неправильно расположенную последовательность. Теперь на каждом шаге, начиная с i = 2, из неправильно расположенной последовательности извлекается очередной элемент и перекладывается в готовую последовательность на нужное место.
for i:=2 to N do
begin
x:=a[i];
<включение х на соответствующее место готовой последовательности a[1],…, a[i]>
End
Поиск подходящего места можно осуществить одним из методов поиска в массиве, описанным выше. Затем х либо вставляется на свободное место, либо сдвигает вправо на один индекс всю левую сторону. Схематично представим алгоритм для конкретного примера:
Исходные элементы 23 34 12 13 9
i =2 23 34 12 13 9
i =3 12 23 34 13 9
i =4 12 13 23 34 9
i =5 9 12 13 23 34
В алгоритме поиск подходящего места осуществляется как бы просеиванием x: при движении по последовательности и сравнении с очередным a[j]. Затем х либо вставляется на свободное место, либо а[j] сдвигается вправо и процесс как бы «уходит» влево.
Сортировка с помощью прямого включения
Элементы массива, начиная со второго, последовательно берутся по одному и включаются на нужное место в уже упорядоченную часть массива, расположенную слева от текущего элемента а[i]. В отличие от стандартной ситуации включения элемента в заданную позицию массива, позиция включаемого элемента при этом неизвестна. Определим её, сравнивая в цикле поочерёдно a [ i ] с a [ i ‑1], а [ i ‑2],… до тех пор, пока не будет найден первый из элементов меньший или равный а [ i ], либо не будет достигнут левый конец массива. Поскольку операции сравнения и перемещения чередуются друг с другом, то этот способ часто называют просеиванием или погружением. Очевидно, что программа, реализующая описанный алгоритм, должна содержать цикл в цикле.
program sortirovka_l;
(*сортировка включением по линейному поиску*)
const N=5;
type item= integer;
var a: array [0..n] of item; i, j: integer; x: item;
begin (*задание искомого массива*)
for i:=1 to N do begin write ('введите элемент a [', i, ']=');
readln (a[i])
end;
for i:=1 to N do begin write (a[i], ' ');
end;
writeln;
(*алгоритм сортировки включением*)
for i:=2 to n do
begin
x:=a[i]; j:=i; a[0]:=x; (*барьер*)
while x<a [j-l] do
begin
a[j]:=a [j‑1]; j:=j‑1;
end;
a[j]:=x;
{for k:=1 to n do write (a[k], ' ') end; writeln;} end;
(*вывод отсортированного массива*)
for i:=1 to N do
begin
write (a[i], ' '); end;
readln; end.
В рассмотренном примере программы для анализа процедуры пошаговой сортировки можно рекомендовать использовать трассировку каждого прохода по массиву с целью визуализации его текущего состояния. В тексте программы в блоке непосредственного алгоритма сортировки в фигурных скобках находится строка, которая при удалении скобок выполнит требуемое (параметр k необходимо описать в разделе переменных – var k:integer).
Вернемся к анализу метода прямого включения. Поскольку готовая последовательность уже упорядочена, то алгоритм улучшается при использовании алгоритма поиска делением пополам. Такой способ сортировки называют методом двоичного включения.
program sortirovka_2;
(*сортировка двоичным включением*)
const N=5;
type item= integer;
var a: array [0..n] of item; i, j, m, L, R: integer; x: item;
begin (*задание элементов массива*)
for i: – l to N do begin write ('введите элемент a [', i, ']= ');
readln (a[i]);
end;
for i:=1 to N do begin write (a[i], ' ');
end;
writeln;
(*алгоритм сортировки двоичным включением*)
for i:=2 to n do
begin
x:=a[i]; L:=l; R:^i;
while L<R do
begin
m:=(L+R) div 2; if a [m] <=x then L:=m+1 else R:=m;
end;
for j:=i downto R+l do a[j]:=a [j‑1];
a[R]:=x; end;
(* вывод отсортированного массива*)
for i: – l to N do
begin write (a[i], ' ');
end;
readln;
end.
Сортировка Шелла
Метод, предложенный Дональдом Л. Шеллом, является неустойчивой сортировкой по месту. Эффективность метода Шелла объясняется тем, что сдвигаемые элементы быстро попадают на нужные места. Среднее время для сортировки Шелла равняется O (n 1.25), для худшего случая оценкой является O (n 1.5). Дальнейшие ссылки см. в книге Кнута [4].
На рисунке 1.8 приведен пример сортировки вставками. Мы сначала вынимали 1, затем сдвигали 3 и 5 на одну позицию вниз, после чего вставляли 1. Таким образом, нам требовались два сдвига. В следующий раз нам требовалось два сдвига, чтобы вставить на нужное место 2. На весь процесс нам требовалось 2+2+1=5 сдвигов.
На рисунке 1.9 иллюстрируется сортировка Шелла. Мы начинаем, производя сортировку вставками с шагом 2. Сначала мы рассматриваем числа 3 и 1: извлекаем 2, сдвигаем 3 на 1 позицию с шагом 2, вставляем 2. Затем повторяем то же для чисел 5 и 2: извлекаем 2, сдвигаем вниз 5, вставляем 2 и т. д. Закончив сортировку с шагом 2, производим ее с шагом 1, т. е. выполняем обычную сортировку вставками. Всего при этом нам понадобится 1 + 1+ 1 = 3 сдвига. Таким образом, использовав вначале шаг, больший 1, мы добились меньшего числа сдвигов.

Рисунок 1.9 – Сортировка Шелла
Можно использовать самые разные схемы выбора шагов. Как правило, сначала мы сортируем массив с большим шагом, затем уменьшаем шаг и повторяем сортировку. В самом конце сортируем с шагом 1. Хотя этот метод легко объяснить, его формальный анализ довольно труден. В частности, теоретикам не удалось найти оптимальную схему выбора шагов. Кнут провел множество экспериментов и следующую формулу выбора шагов (h) для массива длины N.
Вот несколько первых значений h:
 .
.
Чтобы отсортировать массив длиной 100, прежде всего, найдем номер s, для которого hs ³ 100. Согласно приведенным цифрам, s = 5. Нужное нам значение находится двумя строчками выше. Таким образом, последовательность шагов при сортировке будет такой: 13–4–1. Ну, конечно, нам не нужно хранить эту последовательность: очередное значение h находится из предыдущего.
Сортировка с помощью дерева
Улучшенный метод сортировки выбором с помощью дерева. Метод сортировки прямым выборо
|
|
|
