 |


Представление множеств и отношений в программах
|
|
|
|
В этом параграфе рассматривается представление множеств в программах. Термин «представление» (еще употребляют термин «реализация») применительно к программированию означает следующее. Задать представление какого-либо объекта (в данном случае множества) – значит, описать в терминах используемой системы программирования структуру данных, используемую для хранения информации о представляемом объекте, и алгоритмы над выбранными структурами данных, которые реализуют присущие данному объекту операции. Предполагается, что в используемой системе программирования доступны такие общеупотребительные структуры данных, как массивы, структуры (или записи) и указатели. Таким образом, применительно к множествам определение представления подразумевает описание способа хранения информации о принадлежности элементов множеству и описание алгоритмов для вычисления объединения, пересечения и других введенных операций [5].
Следует подчеркнуть, что, как правило, один и тот же объект может быть представлен многими разными способами, причем нельзя указать способ, который является наилучшим для всех возможных случаев. В одних случаях выгодно использовать одно представление, а в других – другое. Выбор представления зависит от целого ряда факторов: особенностей представляемого объекта, состава и относительной частоты использования операций в конкретной задаче и т. д. Умение выбрать наиболее подходящее для данного случая представление является основой искусства практического программирования. Хороший программист отличается тем, что он знает много разных способов представления и умело выбирает наиболее подходящий.
Множества и задачи информационного поиска
|
|
|
Наиболее продуктивный подход к разработке эффективного алгоритма для решения любой задачи – изучить ее сущность. Довольно часто задачу можно сформулировать на языке теории множеств, относящейся к фундаментальным разделам математики. В этом случае алгоритм ее решения можно изложить в терминах основных операций над множествами. К таким задачам относятся и задачи информационного поиска, в которых решаются проблемы, связанные с линейно упорядоченными множествами [1].
Многие задачи, встречающиеся на практике, сводятся к одной или нескольким подзадачам, которые можно абстрактно сформулировать как последовательность основных команд, выполняемых на некоторой базе данных (универсальном множестве элементов). Например, выполнение последовательности команд, состоящих из операций поиск, вставка, удаление и минимум, составляет существенную часть задач поиска. Об этих и других подобных командах и пойдет речь ниже [12].
Рассмотрим несколько основных операций над множествами, типичных для задач информационного поиска.
• Поиск (а; S) определяет, принадлежит ли элемент а множеству S;
если а  S, результат операции – ответ «да»; в противном случае –
S, результат операции – ответ «да»; в противном случае –
ответ «нет».
• Вставка (а, S) добавляет элемент а в множество S, то есть заменяет S на S U { а }.
• Алгоритм правильного обхода(S) печатает элементы множества S с
соблюдением порядка.
• Удаление (a, S) удаляет элемент а из множества S, то есть заменяет S на S \ { а }.
• Объединение (S 1, S 2, S 3) объединяет множества S 1 и S 2, т. е. строит
множество S 3 = S 1 U S 2.
• Минимум (S) выдает наименьший элемент множества S.
Следующая операция – операция минимум(S). Для нахождения наименьшего элемента в двоичном дереве поиска Т строится путь v 0, vi, …, vp, где v 0-корень дерева Т, vi – левый сын вершины vi -1 (i = 1,2,…, р), а у вершины vp левый сын отсутствует. Ключ вершины v p, и является наименьшим элементом в дереве Т. В некоторых задачах полезно иметь указатель на вершину vy, чтобы обеспечить доступ к наименьшему элементу за постоянное время.
|
|
|
Алгоритм выполнения операции минимум(S) использует рекурсивную процедуру левый сын(v), определяющую левого сына вершины v. Алгоритм и процедура выглядят следующим образом.
Input
двоичное дерево поиска Т для множества S
begin
if T = 0 then output «дерево пусто»;
else
вызвать процедуру левый сын(r)
(здесь r – корень дерева Т);
минимум:=1 (v), где v – возврат процедуры левый сын;
end
Output ответ «дерево пусто», если Т не содержит вершин;
минимум – наименьший элемент дерева Т в противном случае.
Procedure левый сын (v).
begin
if v имеет левого сына w then return левый сын (w)
else return v
end
Пример 2.1 Проследите работу алгоритма минимум на дереве поиска, изображенном на рисунке 2.7.
Решение. Дерево Т не пусто, следовательно, вызывается процедура левый сын (1).
Вершина 1 имеет левого сына – вершину 2, значит, вызывается процедура левый сын (2).
Вершина 2 имеет левого сына вершину 4, значит, вызывается процедура левый сын (4).
Вершина 4 не имеет левого сына, поэтому вершина 4 и будет возвратом процедуры левый сын.
Ключом вершины 4 является слово begin, следовательно, наименьшим элементом дерева Т является значение минимум= begin.
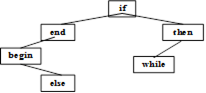
Рисунок 2.7 – Дерево поиска минимума S
Реализовать операцию удаление (a, S) на основе бинарных поисковых деревьев тоже просто. Допустим, что элемент а, подлежащий удалению, расположен в вершине v. Возможны три случая:
• вершина v является листом; в этом случае v просто удаляется
из дерева;
• у вершины v в точности один сын; в этом случае объявляем отца вершины v отцом сына вершины v, удаляя тем самым v из дерева (если v – корень, то его сына делаем новым корнем);
• у вершины v два сына; в этом случае находим в левом поддереве вершины v наибольший элемент b, рекурсивно удаляем из этого поддерева вершину, содержащую b, и присваиваем вершине v ключ b. (Заметим, что среди элементов, меньших а, элемент b будет наибольшим элементом дерева. Кроме того, вершина, содержащая b, может быть или листом, являющимся чьим-то правым сыном, или иметь только левое поддерево.)
Ясно, что до выполнения операции удаление (а, S) необходимо проверить, не является ли дерево пустым и содержится ли элемент а в множестве S. Для этого придется выполнить операцию поиск (а, S), причем, и в случае положительного ответа необходимо выдать кроме ответа «да» и номер вершины, ключ которой совпадает с a (далее ключ вершины v будем обозначать через l (v)). Кроме этого, для реализации операции удаление (a, S) требуется знать и номер вершины w, являющейся отцом вершины v. Саму же рекурсивную процедуру удаление (а, S) можно реализовать так, как показано ниже.
|
|
|
Procedure удаление (а, S)
begin
if v – лист then удалить v из Т
else
(2) if v имеет только левого или только
правого сына u then
(3) if v имеет отца w then
назначить и сыном w
else
сделать u корнем дерева,
присвоив ему номер v
else
найти в левом поддереве v наибольший элемент b, содержащийся в вершине у;
(6) return удаление (b, S);
(7) l(v):=b;
end
Пример 2.2 Проследите за работой алгоритма удаление (а, S) для двоичного дерева поиска S, изображенного на рисунке 2.7, если a – это слово «if».
Решение. Слово «if» расположено в корне с номером 1, у которого два сына (вершины 2 и 3), поэтому выполняем строку (5) алгоритма. Наибольшее слово, меньшее «if» (лексикографически), расположенное в левом поддереве корня и находящееся в вершине 2, – это end. Вызываем процедуру удаление (end, S).
Условие строки (2) алгоритма выполняется, так как вершина 2 с ключом end имеет только левого сына. Условие строки (3) не выполняется, так как удаляемая вершина является корнем. Поэтому переходим к строке (4): делаем вершину 2 корнем, сыновьями которого становятся вершины 4 (левым) и 3 (правым). Работа процедуры удаление (end, S) закончена.
Продолжаем выполнение алгоритма (выполняем строку (7)): полагаем ключ вершины 1 равным «end» (l (I):= end).
Полученное в результате дерево изображено на рисунке 2.8.
Заметим, что при работе рассмотренных алгоритмов необходимо находить сыновей, отца и ключ заданной вершины двоичного дерева поиска. Это можно сделать довольно просто, если дерево в памяти компьютера хранится в виде трех массивов: LEFTSON, RIGHTSON и KEY. Эти массивы устроены следующим образом:
| LEFTSON (i) = |  v, если v – левый сын вершины i
*, если у вершины i левого сына нет v, если v – левый сын вершины i
*, если у вершины i левого сына нет
|
| RIGHTSONM (i) = |  v, если v – правый сын вершины i
*, если у вершины i правого сына нет v, если v – правый сын вершины i
*, если у вершины i правого сына нет
|
key (i) = l (i) – ключ вершины i.
|
|
|

Рисунок 2.8 – Результат работы алгоритма удаление (а, S) для двоичного дерева поиска S
Например, бинарное поисковое дерево, изображенное на рисунке 2.7, может быть представлено в виде таблицы 2.1.
Таблица 2.1 – Представление бинарного поискового дерева в виде таблицы
| I | LEFTSON | RIGHTSON | KEY |
| 1 | 2 | 3 | if |
| 2 | 4 | * | end |
| 3 | * | 6 | then |
| 4 | * | 5 | begin |
| 5 | * | * | else |
| 6 | * | * | while |
Правила поиска сыновей и ключа заданной вершины следуют из определения массивов. Определение отца заданной вершины состоит в нахождении строки массивов LEFTSON или RIGHTSON, в которой находится номер заданной вершины. Например, отцом вершины 4 является вершина 2, так как число 4 находится во второй строке массива LEFTSON.
Объединение множеств
Обратимся теперь к объединению множеств, то есть к операции объединение (S 1, S 2, S 3).
Если множества S 1 и S 2 линейно упорядочены, то естественно требовать такого порядка и от их объединения. Один из возможных способов объединения состоит в последовательном выполнении описанной выше операции вставка для добавления каждого элемента одного множества в другое. При этом, очевидно, операцию вставка предпочтительнее выполнять над элементами меньшего множества с целью сокращения времени на объединение. Отметим, что такой способ работы подходит как для непересекающихся, так и для пересекающихся множеств.
Во многих задачах объединяются непересекающиеся множества. Это упрощает процесс, так как исчезает необходимость каждый раз проверять, содержится ли добавляемый элемент в множестве, либо удалять повторяющиеся экземпляры одного и того же элемента из S 3.
Процедура объединения непересекающихся множеств применяется, например, при построении минимального остовного дерева в данном нагруженном графе.
Рассмотрим алгоритм объединения непересекающихся множеств на основе списков. Будем считать, что элементы объединяемых множеств пронумерованы натуральными числами 1,2,…. n. Кроме того, предположим, что имена множеств – также натуральные числа. Это не ограничивает общности, поскольку имена множеств можно просто пронумеровать натуральными числами.
Представим рассматриваемые множества в виде совокупности линейных связанных списков. Такую структуру данных можно организовать следующим образом.
Сформируем два массива R и next размерности n, в которых R (i) – имя множества, содержащего элемент i, a next(i) указывает номер следующего элемента массива R, принадлежащего тому же множеству, что и элемент i. Если i – последний элемент какого-то множества, то положим next (i) = 0. Для указателей на первые элементы каждого множества будем использовать массив list, число элементов которого равно числу рассматриваемых в задаче множеств, и элемент которого list (j) содержит номер первого элемента множества с именем j в массиве R.
|
|
|
Кроме того, сформируем массив size, каждый элемент которого size (j) содержит количество элементов множества с именем j.
Будем различать внутренние имена множеств, содержащиеся в массиве к, и внешние имена, получаемые множествами в результате выполнения операции объединение. Соответствие между внутренними и внешними именами множеств можно установить с помощью массивов Ехт-NAME и INT-NAME. Элемент массива EXT-NAME(j) содержит внешнее имя множества, внутреннее имя которого есть j, а INT-NAME(k) – внутреннее имя множества, внешнее имя которого есть к.
Пример 2.3 Используя только что определенные массивы, опишите множества {1,3,5,7}, {2,4.8}, {6} с внешними именами 1, 2, 3 и внутренними именами 2, 3, 1 соответственно.
Решение. Прежде всего, отметим, что общее количество элементов всех множеств равно восьми. Поэтому размерность массивов R и next будет n = 8. Кроме того, напомним, что номера элементов массивов list, SIZE, Ехт-NAME и значения элементов массива R – это внутренние имена множеств, а массива INT-NAME внешние.
Алгоритм выполнения операции объединение (S1, S2, S3) состоит в добавлении к списку элементов большего из множеств S1 и S2 элементов меньшего множества и присвоение полученному множеству внешнего имени S3. При этом вычисляется также размер построенного множества S3.
Объединение (i, j, к)
Input
i, j – внешние имена объединяемых множеств
(пусть размер i меньше размера j);
массивы R, NEXT, LIST, SIZE, ЕХТ-NAME, INT-NAME;
begin
A:=INT-NAME(i);
B:=INT-NAME(j);
element:=LIST(A);
while element <> 0 do
begin
R(element):=B;
last:=element;
element:=NEXT(element)
end
NEXT(last):=LIST(B);
LIST(B):=LIST(A);
SIZE(B):=SIZE(B) + SIZE(A);
INT-NAME(K):=B;
EXT-NAME(B):=k
End
Объединение множеств i, j с внешним именем k.
В процессе работы алгоритм совершает следующие действия:
1) определяет внутренние имена множеств i и j;
2) определяет начало списка элементов меньшего множества;
3) просматривает список элементов меньшего множества и изменяет соответствующие элементы массива R на внутреннее имя большего множества;
4) объединяет множества путем подстановки меньшего множества перед большим;
5) присваивает новому множеству внешнее имя k.
Заметим, что время выполнения операции объединения двух множеств с помощью рассмотренного алгоритма пропорционально мощности меньшего множества.
|
|
|
