 |


Представление о «больших данных» и методах DataMining
|
|
|
|
Big Data (большие данные) методы сбора и обработки больших объемов неструктурированной и структурированной информации для получения результатов, для помощи специалистам в принятии решений или для автоматического принятия решений без участия человека (единично – сейчас, массово - в близкой перспективе). Вместо классических методов обработки данных в таких случаях требуются методы анализа Big Data.
Область знания data science - раздел информатики, изучающий проблемы анализа, обработки и представления данных в цифровой форме - разрабатывает методы по обработке данных в условиях больших объёмов, в т.ч. статистические методы, методы интеллектуального анализа данных. С 2010-х гг data science стала прикладной практикой. Одно из ее направлений развития - Data mining - группа методов обнаружения в данных неочевидных закономерностей, тенденций для принятия решений. «data mining» (дословно «добыча данных», «извлечение данных»,, интеллектуальный анализ данных (ИАД)). Методы data mining могут быть применены как для работы с большими данными, так и для обработки сравнительно малых объемов данных. Задачи, решаемые методами data mining, принято разделять на описательные (англ. descriptive) и предсказательные (англ. predictive). В описательных задачах требуется найти и описать скрытые закономерности, в предсказательных – предсказать тенденцию, сделать предположение о развитии событий в дальнейшем.
ИАД использует методы и области знаний:
- Математическая статистика (дескриптивный анализ, корреляционный и регрессионный анализ, факторный анализ, дисперсионный анализ, компонентный анализ, дискриминантный анализ, анализ временных рядов, анализ выживаемости, анализ связей),
|
|
|
- Математическое моделирование, оптимизация и программирование (методы нечёткой логики; классификационных и деревьев решений; нейронные сети; генетические алгоритмы; эволюционное программирование, байесовское обучение и кластеризация),
- Визуализация ( диаграммы, деревья классификации, кластеры)и иное представление.
Назначение ИАД:
• выявление зависимостей, причинно-следственных связей, ассоциаций и аналогий, определение значений факторов времени, локализация событий или явлений по месту;
• группировка, классификация событий и ситуаций, определение профилей различных факторов (например, разделение заказчиков или событий на кластеры связанных элементов, анализ общих черт);
· прогнозировани е хода процессов, событий, оценка рисков. (оценка продаж, прогнозирование нагрузки сервера или времени простоя сервера, диагностика, выбор наиболее подходящих заказчиков для целевой рассылки, определение точки равновесия для рискованных сценариев).
· Рекомендации: определение продуктов, которые с высокой долей вероятности могут быть проданы вместе, создание рекомендаций
· Поиск последовательностей: анализ выбора заказчиков во время совершения покупок, прогнозирование следующего возможного события
Методы очистки и анализа данных:
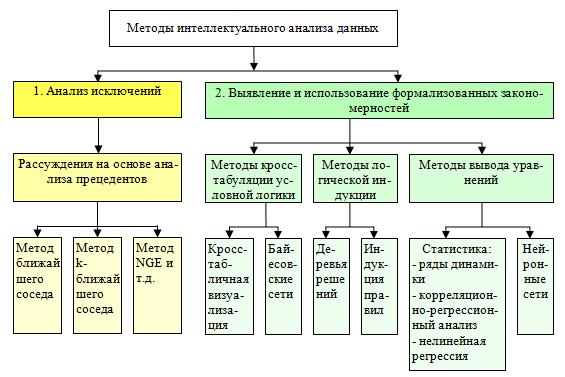
1. нейронные сети,
2. деревья классификации, символьные правила,
3. методы кластериазации (например, метод ближайшего соседа или k-среднего т.п.),
4. метод опорных векторов,
5. байесовские сети,
6. регрессионный и факторный анализ,
7. корреляционно-регрессионный анализ,
8. неиерархические методы кластерного анализа, в том числе алгоритмы k-средних и k-медианы,
9. методы поиска ассоциативных правил,
10. метод ограниченного перебора,
11. эволюционное программирование и генетические алгоритмы,
12. разнообразные методы визуализации данных, проч..
|
|
|
Примерный порядок решения задач методами data mining:
1. Постановка задачи анализа;
2. Сбор и подготовка данных (фильтрация, дополнение, кодирование);
3. Выбор модели (алгоритма анализа данных);
4. Подбор параметров модели и алгоритма обучения;
5. Обучение модели (автоматический поиск остальных параметров модели);
6. Анализ качества обучения, если неудовлетворительный переход на п. 4 или п. 3;
7. Анализ выявленных закономерностей, если неудовлетворительный переход на п. 1, 3.
Пример конкретного инструмента ИАД - Microsoft SQL Server Development - среду создания моделей интеллектуального анализа данных и работы с ними; включает программу SQL Server Development Studio, которая содержит алгоритмы интеллектуального анализа данных и средства создания запросов, которые облегчают создание полноценного решения для нескольких проектов. Кроме того, эта среда включает компонент для поиска моделей и управления объектами интеллектуального анализа данных.
Процесс ИАД в этой программе трактуется как циклический: в процессе создания аналитической модели данных, выполнив просмотр данных, пользователь может обнаружить, что данных недостаточно для создания моделей интеллектуального анализа данных, что ведет к необходимости поиска дополнительных данных, может быть, что после построения нескольких моделей окажется, что они не дают адекватный ответ на поставленную задачу, и необходимо поставить задачу по-другому. Может возникнуть необходимость в обновлении уже развернутых моделей за счет новых поступивших данных. Для создания хорошей модели может понадобиться многократно повторить каждый шаг процесса.
Этапы обработки данных:
1. Постановка задачи
2. Подготовка данных
3. Изучение данных на предмет корректности
4. Построение моделей
5. Исследование и проверка моделей
6. Развертывание и обновление моделей

1) Постановка задачи. Первым шагом процесса интеллектуального анализа данных, здесь надо решить:
· Что необходимо найти? Какие типы связей необходимо найти?
· Какой результат или атрибут необходимо спрогнозировать?
· Какие виды данных нужно иметь? Нужно ли выполнять очистку, статистическую обработку, чтобы данные стали применимыми?
|
|
|
2) Подготовка данных. Второй шаг процесса интеллектуального анализа данных - объединение и очистка данных. Данные могут находиться в разных частях сети храниться в различных форматах или содержать неверные или отсутствующие данные. Перед использованием алгоритмов data mining надо подготовить наборы анализируемых данных из хранилищ данных. Очистка данных - это не только удаление недопустимых данных или интерполяция отсутствующих значений, но и поиск в данных скрытых зависимостей, определение источников самых точных данных и подбор факторов, которые больше всего подходят для использования в анализе. Далее данные фильтруются. Фильтрация удаляет выборки с шумами и пропущенными данными. Отфильтрованные данные сводятся к наборам факторов. Набор признаков формируется в соответствии с гипотезами о том, какие факторы сырых данных имеют высокую прогнозную силу в расчете на требуемую вычислительную мощность для обработки. Например, черно-белое изображение лица размером 100×100 пикселей содержит 10 тыс. бит сырых данных. Они могут быть преобразованы в вектор признаков путём обнаружения в изображении глаз и рта. В итоге происходит уменьшение объёма данных с 10 тыс. бит до списка кодов положения, значительно уменьшая объём анализируемых данных, а значит и время анализа.
Просмотр данных. Третьим шагом процесса интеллектуального анализа данных просмотр подготовленных данных. Для принятия правильных решений при создании моделей интеллектуального анализа данных необходимо понимать данные. Методы исследования данных включают в себя расчет минимальных и максимальных значений, вычисление средневероятного и стандартного отклонения и изучение распределения данных. Например, по максимальному, минимальному и среднему значениям можно заключить, что выборка данных не является репрезентативной, необходимо получить более сбалансированные данные или изменить предположения об ожидаемых результатов. Большая величина стандартного отклонения может свидетельствовать о том, что добавление новых данных поможет усовершенствовать модель.
|
|
|
4) Построение моделей и обучение (если модель на основе нейросети). Четвертым шагом процесса интеллектуального анализа данных, построение моделей интеллектуального анализа данных. Модель включает целевую функцию (что считать критерием оптимальности, правильности решения в результате ИАД). Наблюдения делятся на две категории — обучающий набор и тестовый набор. Обучающий набор используется для «обучения» алгоритма data mining (модели) путем ее модификации до тех пор, пока модель не даст приемлемых результатов с точки зрения целевой функции, а тестовый набор нужен для проверки найденных закономерностей. Доработку модели называют обучением. Обучение обозначает процесс применения некоторого математического алгоритма к данным в структуре с целью выявить закономерности. Закономерности, обнаруженные в процессе обучения, зависят от выбора обучающих данных, выбранного алгоритма и целевой функции.
Примеры алгоритмов и типы зада ч, для решения которых они годятся (на примере инструмента анализа MS Analysis Services:
| Примеры задач | Подходящие алгоритмы Майкрософт |
| Прогнозирование дискретного атрибута: · Пометка клиентов из списка потенциальных покупателей как хороших и плохих кандидатов. · Вычисление вероятности отказа сервера в течение следующих шести месяцев. · Классификация вариантов развития болезней пациентов и исследование связанных факторов. | Алгоритм дерева принятия решений Алгоритма Байеса, Алгоритм кластеризации, Алгоритм нейронной сети, |
| Прогнозирование непрерывного атрибута: · Прогноз продаж на следующий год. · Прогноз количества посетителей сайта с учетом прошлых лет и сезонных тенденций · Формирование оценки риска с учетом демографии. | Алгоритм дерева принятия решений, Алгоритм временных рядов, Алгоритм линейной регрессии, |
| Прогнозирование последовательности: · Анализ маршрута перемещения по веб-сайту компании. · Анализ факторов, ведущих к отказу сервера. · Отслеживание и анализ последовательностей действий во время посещения поликлиники с целью формулирования рекомендаций по общим действиям. | Алгоритм кластеризации последовательностей, |
| Нахождение групп общих элементов в транзакциях: · Использование анализа потребительской корзины для определения мест размещения продуктов. · Выявление дополнительных продуктов, которые можно предложить купить клиент. · Анализ данных опроса, проведенного среди · посетителей события, с целью выявления того, какие действия и стенды были связаны, чтобы планировать будущие действия. | Алгоритм взаимосвязей, Алгоритм дерева принятия решений, |
| Нахождение групп схожих элементов: · Создание профилей рисков для пациентов на основе таких атрибутов, как демография и поведение. · Анализ пользователей по шаблонам просмотра и покупки · Определение серверов, которые имеют аналогичные характеристики использования. | Алгоритм кластеризации, Алгоритм кластеризации последовательностей, |
|
|
|
Исследование и проверка моделей. Пятый шаг интеллектуального анализа данных - исследование построенных моделей интеллектуального анализа данных и проверка их эффективности. Динамическое обновление моделей по мере поступления в организацию новых данных и постоянные изменения, направленные на повышение эффективности решения, должны быть частью стратегии развертывания.
|
|
|
