 |


Социокультурные угрозы: репрезентации в языке как средство воздействия на общество.
|
|
|
|
Социокультурные угрозы: репрезентации в языке как средство воздействия на общество.
Е. П. Буторина
Речевые маркеры угрозы и прогнозная аналитика
В современном мире мы можем наблюдать возникновение новых рисков, в том числе и в социокультурной сфере, заметно отличающихся от уже знакомых и привычных количественными и качественными характеристиками. «Вот в чём заключается тренд: в течение последних двадцати лет мы наблюдали появление множества новых типов риска, от которых можно застраховаться, и появление методов «упаковки и продажи» таких рисков» [Хилл 2004: 254]. Эти риски могут быть интерпретированы речевым сознанием как возможные угрозы. «Наивная картина мира представляет ситуацию риска как ситуацию потенциальной угрозы субъекту» [Ефимова 2007: 439]. Глобализация экономической и социокультурной жизни создаёт новые условия для перемещения и распространения этих рисков: «взаимосвязанность позволила продавать риск за границу, создавая большие, глобальные рынки для перераспределения риска» [Хилл 2004: 255].
В этих условиях крайне важно своевременно распознавать угрозы и реагировать на них. Выявлением потенциальных угроз занимается прогнозная аналитика (predictiveanalytics), которая может быть определена как «технология, опирающаяся на опыт (данные) для прогнозирования будущего поведения людей с целью принятия оптимальных решений» [Сигель 2014: 31]. В качестве синонима прогнозной аналитики иногда используют термин datamining («извлечение знаний из данных», или интеллектуальный анализ данных) [Сигель 2014: 33]. Несмотря на то, что некоторые события иногда могут носить случайный и непредсказуемый характер [Талеб 2009], можно привести достаточно много примеров успешного прогнозирования социокультурных явлений с применением алгоритмов интеллектуального анализа данных ([Майер-Шенбергер, Кукьер 2014], [Сигель 2014]).
|
|
|
В возрастающем потоке информации, с каждым днём всё более активно конкурирующей за внимание людей, становится всё сложнее выявлять и оценивать возможные угрозы, поэтому для работы с большими массивами текстов на помощь приходят алгоритмы интеллектуального анализа данных. В этих условиях как данные можно рассматривать слова и взаимодействия, подвергшиеся датификации, которая может быть определена как представление явлений в количественном формате для их последующего алгоритмического анализа [Майер-Шенбергер, Кукьер 2014]. Анализом датифицированных речевых произведений занимается культурономика – раздел вычислительной лексикологии, которая пытается интерпретировать и прогнозировать поведение человека и культурные
тенденции, опираясь на количественный анализ текстов на естественном языке [Майер- Шенбергер, Кукьер 2014].
Если речь идёт о выявлении потенциальных угроз путём анализа лексики, входящей в те или иные речевые произведения, то прежде всего обратим внимание на представление об угрозе в речевом сознании носителя русского языка. Приводимые в словарях толкования лексем, входящих в семантическое поле ‘УГРОЗЫ’, имеют общую архисему ‘ОПАСНЫЙ’. В словаре С. И. Ожегова «ОПАСНЫЙ» толкуется как «способный вызвать, причинить какой-н. вред, несчастье» [Ожегов 1990: 451].
Таким образом, можно видеть, что в толковании представлений об опасности, которые зафиксированы в системе значений русского языка, в первую очередь выделяются две важных составляющих: во-первых, представление о вреде, а во-вторых – о способности его причинить. Опасность для себя в чем-либо может видеть как отдельный субъект, так и целая группа или даже социум, разделяющие некие общие представления. «Под субъектом оценочной структуры подразумевается лицо, часть социума или социум в целом, с точки зрения которого производится оценка. Субъект даёт оценку на основании имеющейся в его
|
|
|
«картине мира» шкалы и соответствующих стереотипов» [Вольф 2006: 68]. Восприятие угрозы определяется в первую очередь тем, как индивидуум, группа иди социум оценивают ключевые, с их точки зрения, компоненты рассматриваемой ситуации. Эта оценка (как рациональная, так и эмоциональная) может быть выявлена на основе анализа больших массивов текстов на естественном языке, которые порождаются членами такого социума. При этом участники речевого акта, содержащего такую оценку, «оказываются в первую очередь носителями эмоций, возникающих, если оценка касается их интересов. Чем сильнее эти интересы затронуты, тем более действенны иллокутивные силы оценки и тем больше речевой акт влияет на эмоциональное состояние адресата» [Вольф 2006: 167]. Таким образом, в случае эмоционального восприятия людьми возможной социокультурной угрозы речь идёт о порождении ими некого множества текстов, под влиянием прочтения которых состояние других людей может измениться настолько, что будут порождены следующие тексты, содержащие оценку этой угрозы, и так далее.
Выявление и систематизация способов языкового выражения оценки (в том числе эмоциональной) потенциально угрожающих ситуаций в таких текстах помимо очевидных приложений в алгоритмах прогнозной аналитики может иметь также важное значение для решения теоретических задач, связанных в том числе с созданием искусственного интеллекта (ArtificialIntelligence – AI). В защиту этой позиции профессор Пенсильванского университета Рэндалл Коллинз выдвинул следующее предположение: «если настоящий искусственный разум будет создан, главную роль в этом сыграет социология. Ограничения,
которые испытывали до сих пор компьютерные модели, проистекали из того факта, что разработчики представляли себе разум так, ка если бы это был отдельный и независимый индивидуальный ум. Однако ведь человеческое мышление базово социально. И дело не только в этом; успешный AI должен быть эмоциональным! Это может звучать парадоксально, но я попытаюсь показать вам < …>, что эмоциональные процессы, которые поддерживают социальный контакт, направляют наши мысли в определённые каналы. Если компьютерный разум намеревается стать способным сделать то, что способно делать человеческое существо, это должен быть компьютер с эмоциями» [Коллинз 2004: 567].
|
|
|
Далее Р. Коллинз развивает эту идею, обращая внимание на то, что акцентирование эмоций в речи фокусирует внимание участников коммуникации прежде всего на важных для дальнейшего обсуждения и анализа темах и идеях. «В идее, что человеческий ум социален, нет ничего таинственного. Эмиль Дюркгейм использовал понятие «коллективное сознание», относя его к понятиям и верованиям, которые разделяются группой людей < …>. Сказать, что ум социален, – это всего лишь сказать, что наше мышление создаётся, когда мы говорим друг с другом. Понятия и идеи, которыми мы обладаем, и наши чувства по поводу того, какие идеи важны, происходят из разговоров, которые мы ведём друг с другом» [Коллинз 2004: 570].
В современных условиях исключительное место в социальных коммуникациях занимают медиа. «То, что мы знаем о нашем обществе и даже о мире, в котором живём, мы знаем благодаря масс-медиа» [Луман 2005: 8]. В ситуациях неопределённости или кризиса эта и без того огромная роль средств массовой информации и коммуникации дополнительно усиливается. «Сила прессы кажется почти безграничной в кризисное время. Когда на горизонте возникает опасность, все граждане превращаются в читателей…» [Московичи 1998а: 233]. Новые медиа, в первую очередь блоги и социальные сети, увеличивают и без того практически непреодолимое влияние медиа, встраивая их в повседневные индивидуальные и групповые коммуникации. «Масс-медиа как таковые неэффективны на уровне отдельного человека. Они не изменяют ни его мнений, ни его установок. Но, проникая в первичные группы соседей, семьи, друзей и т. д. посредством личных обсуждений, они окончательно воздействуют на него и меняют его» [Московичи 1998а: 235
– 236].
Развитие современных социальных медиа приводит к тому, что общая для участников коммуникации реальность не только разделяется этими участниками, но также формируется и воссоздаётся в соответствии с их представлениями о мире. Выдающийся французский психолог С. Московичи в своих исследованиях говорит об образе общества, «состоящего из двух подразделений – одно охвачено сетями, которые, соединяя индивидов, постоянно
|
|
|
создаются и разрушаются ими; второе принадлежит представлениям, которые индивиды разделяют, формируя тем самым свою общую реальность» [Московичи 1998б: 360]. При этом он считает важными характеристиками массовость социальных связей, коммуникаций и порождаемых при этом текстов: «количество и разнообразие этих связей и социальных кругов, к которым принадлежит индивид, является эталонной мерой культуры. Культура тем более продвинута – и добавим, тем более современна, – чем больше это количество. Но особенно важно, что разнообразие и множественность таких социальных кругов гарантируют прогрессирующую эмансипацию индивида от их противоречивого влияния, его своеобразие и известную независимость» [Московичи 1998б: 356 – 357].
Итак, в коммуникациях, реализующих коллективные представления о потенциальных социокультурных угрозах, можно выделить несколько инвариантных признаков. Угроза в них понимается как нечто, получающее негативную оценку всех или значимого большинства участников некоего сообщества. При этом такая оценка заметно отклоняется от нормы в представлении этого сообщества. Кроме того, угроза имеет динамику и отнесена к будущему, т. е. связана с фактором времени.
Оценочные значения и способы их выражения в естественных языках исследовала Е. М. Вольф, неоднократно указывая в своих работах на то, что оценка производится всегда относительно представления о норме и с учётом стереотипа, принятого в том или ином сообществе: «Таким образом, когда говорят о норме, подразумевают признаки стереотипа и их положение на оценочной шкале. Иными словами, норма отражает признаковые характеристики стереотипа оцениваемого объекта» [Вольф 2006: 54]. В её работах помимо общих вопросов семантики оценки для разных языков уточняется специфика основных компонентов оценочных структур: «Сам по себе стереотип устроен достаточно сложно и представляет собой многоаспектную и многоплановую структуру, притом достаточно размытую. Предполагается, что стереотипные представления о вещах опираются на информацию из области восприятия, из области функциональной, а также соотносятся с их ассоциативными связями < …>. Иными словами, оценочные стереотипы включают объекты, в том числе положения вещей, с их признаками + их место в ценностной картине мира» [Вольф 2006: 58 – 59]. При этом подчёркивается, что субъективные оценки не имеют стереотипов: «чисто «эмотивные» (субъективные) оценки не включают стереотипов, так как они не соотносятся с признаками объектов и не подразумевают классификаций < …>. Так, не имеют стереотипов аффективные определения потрясающий, сногсшибательный и т. п. Не существует стереотипов потрясающих людей или сногсшибательных спектаклей, хотя в конкретных ситуациях аффективные слова могут предполагать некий набор частных признаков, каузирующих оценку» [Вольф 2006: 61]. По мнению исследователя, «степень
|
|
|
социальной обусловленности стереотипа бывает различной, т. е. охватывает бó льшие или меньшие социальные группы» [Вольф 2006: 61].
Кроме того, Е. М. Вольф принадлежит наблюдение о том, что норма, на которую опирается оценка, так или иначе находит отражение в структурах и единицах языка. При этом отклонение от норм «в том числе в сторону увеличения признака, как отрицательного, так и положительного (! ), язык может рассматривать как сдвиг в сторону «хуже» < …>. Ср. также само слово естественного языка “ненормальный”» [Вольф 2006: 55].
В своём исследовании Е. М. Вольф обратила внимание и на то, что что оценка связана с представлением о времени: «Отметим, что в зоне некоторых объективных признаков шкала оценок связана с фактором времени. Существуют закономерные корреляции по признаку времени (t) у таких, например, свойств, как молодой – старый, больной – здоровый и т. п. Эти корреляции отражаются, в частности, в употреблении слов уже/ещё, ср. ещё молодой и уже старый, но не *уже молодой, *ещё старый, так как ожидаемое развитие имеет направленность молодой> старый…» [Вольф 2006: 55].
По мнению Е. М. Вольф, важным аспектом оценки является также представление о более сильных или слабых эмоциональных состояниях: «Объективно измерить эмоциональные состояния невозможно, но представление о более сильных и более слабых эмоциональных состояниях неразрывно связано с их существованием. По признаку интенсивности проходит одно из основных различий между самими эмоциональными состояниями, на которых основаны некоторые их классификации – различие между эмоциями и аффектами. Так, например, Д. Юм различает «спокойные» и «бурные» эмоции. К
«спокойным» или «слабым» эмоциям обычно относят такие, как эстетическое удовольствие и наслаждение; к «бурным» такие, как ярость, страх, ужас < …> » [Вольф 2006: 237]. При этом необходимо обратить внимание на следующее замечание автора о нормах различных эмоциональных состояний для каждой речевой культуры: «Каждая эмоция подразумевает в картине мира носителей языка определённую степень интенсивности» [Вольф 2006: 238].
В своей монографии о функциональной семантике оценки Е. М. Вольф предложила список основных языковых интенсификаторов для слов со значением оценки в текстах на русском языке: очень, большой, невероятно, всё более, ещё более, значительно, полный, весь, особенно, крайне, в высшей степени, совсем, совершенный, а также привела наиболее характерные для них контексты [Вольф 2006].
В лингвистике интенсификаторы нередко описываются при помощи лексической функции Magn (от лат. ‘magnus’ – ‘большой’). В числе других лексических функций её описание было предложено А. К. Жолковским и И. А. Мельчуком [Жолковский, Мельчук 1967: 213] для обозначения вербализации интенсивно проявленного признака. Впоследствии
особенности средств выражения функции Magn в русском языке в разное время привлекали внимание многих исследователей (см., например, [Кустова 2011], [Тиханович 2009], [Убин 1969] и др. ).
Авторы концепции лексических функций обратились к математическому пониманию функции как средства представления постоянных логических отношений между различными переменными. В качестве переменных вводимых лексических функций ими рассматриваются в первую очередь лексические единицы естественного языка. В общем случае лексическая функция F при этом интерпретируется как смысл, который выражается специальной лексемой Y в зависимости от исходной лексической единицы X, с которой он соотносится в тексте, т. е. F(X)=Y. В этой формуле исходное слово Х рассматривается в качестве аргумента функции, а выражающее заданный смысл F зависимое от исходного слово Y становится значением функции, в интересующем нас случае Magn (X) = Y: например, Magn (болезнь) = тяжёлая. Разработчики теории лексических функций отмечали, что лексическая функция от одного аргумента может иметь и более одного значения: например, Magn (бояться) = ужасно, жутко, до смерти, как огня, как черт ладана и т. п. [ТКС 1984]. Согласно предложенной концепции, Magn (X) может иметь также «склеенное» выражение, то есть не обозначаться отдельным словом, а входить в качестве смыслового компонента в (квази)синоним или гипоним исходной лексемы X: например, Magn (дождь) = ливень. Поскольку Magn – функция синтагматическая, а отношения (квази)синонимии и гипонимии принадлежат парадигматике, А. Н. Тиханович предлагает для «склеенных» выражений обозначение SynMagn, сближающее эти случаи с функцией Syn для обозначения синонимов. По её данным, в современном русском языке функция Magn более чем в 50% случаев выражена одной лексемой, но в целом более 20% для исходных слов – существительных и почти 40% для исходных прилагательных и глаголов она представлена сочетаниями слов, которые включают предлоги, союзы, а иногда содержат целые идиомы или предложения [Тиханович 2009].
В диссертации А. Н. Тиханович систематизированы грамматические характеристики средств выражения Magn, задаваемые их синтаксической функцией определителя по отношению к исходному слову X. Наряду с предсказуемыми часто встречающимися сочетаниями: существительные определяются согласующимися с ними прилагательными или адъективизированными причастиями, глаголы и прилагательные – наречиями или перешедшими в наречия деепричастиями – автором исследования зафиксированы и редкие случаи грамматической принадлежности интенсификаторов для некоторых слов. Это, например, ситуации использования в качестве средств выражения Magn для исходных слов
– имён существительных глаголов (Magn (дождь) = наяривает), наречий (Magn (дождь) =
стеной) и местоимений (Magn (надежда) = вся). Автор отмечает, что в «склеенных» случаях лексическая функция Magn может быть выражена также при помощи словообразовательных элементов: Magn (опытный) = гипер, экстра, много, высоко [Тиханович 2009].
В исследовании А. Н. Тиханович нашли отражение также практически отсутствующие в словарях неонословные средства выражения лексической функции Magn. Автором описаны, например, используемые в качестве таких средств сочетания с предлогами (Magn (бороться)
= изо всех сил), союзами (Magn (надежный) = как никто), местоимениями (Magn (надеяться) = всей душой), идиомами (Magn (дождь) = льет без устали) и др. Таким образом, можно видеть, что языковые средства, подчёркивающие высокую степень проявленности признака в тексте на русском языке достаточно многочисленны и разнообразны. В дальнейшем это может потребовать дополнительных инструментов исследования таких конструкций, но сначала мы определим общие принципы работы со способами выражения оценки и их интенсификаторами на больших массивах текстов.
Итак, в результате анализа соответствующих исследований удалось установить, что в качестве лексем X и Y функции Magn в контекстах описания социокультурных угроз могут быть использованы конечные множества слов, представимые в виде пополняемых списков, в которые будут включены лексические единицы, обладающие определёнными признаками. В качестве исходных лексем X отбираются слова с семантикой отрицательной оценки, в качестве лексем Y – слова, удовлетворяющие критерию Y = Magn (X), то есть интенсификаторы. Кроме того, нам потребуются показатели статистической значимости совместной встречаемости в текстах исследуемого массива слов X и Y. Например, мы можем считать, что в анализируемом массиве речь идёт об угрозах, если в нём встречаются такие сочетания, как злостное правонарушение, рост преступности, существенное ухудшение, распространение пыток, введение санкций, ужесточение санкций, усиление санкций, возрастает опасность и т. п. статистически значимо чаще по сравнению с другими массивами текстов.
В качестве текстов, которые могут содержать описания социокультурных угроз, были избраны сообщения в микроблоге Twitter. Основанием для такого выбора послужила прежде всего краткость таких сообщений, лёгкость их написания и восприятия значительным количеством носителей языка без явных ограничений принадлежности к той или группе или сообществу. Ещё Г. Лебон отмечал эффективность кратких массовых коммуникаций: «Чем более кратко утверждение, чем более оно лишено какой бы то ни было доказательности, тем более оно оказывает влияние на толпу» [Лебон 2008: 207]. Кроме того, принимались во внимание такие факторы, как спонтанный характер сообщения, который нередко отражает
оценку, сделанную под влиянием эмоций, и предельное фиксированное число символов сообщения.
Следует отметить, что попытки автоматического анализа потока новостных сообщений предпринимались уже неоднократно. По большей части такие исследования были связаны с получением неких оснований для прогнозирования поведения трейдеров на рынке акций:
«При достижении потоком бычьих новостей экстремальных уровней вероятно скорое окончание движения вверх, а когда налицо недостаток оптимизма и положительных новостей, следует ожидать формирования дна и разворота вниз» [Самма 2007: 253]. Для определения экстремального уровня новостей с той или иной оценкой автором было предложено выделять термины и ключевые слова, которые использовались для идентификации новостного потока соответственно как «бычьего» или «медвежьего». К таким единицам прежде всего были отнесены базовые термины для отбора новостей, связанных с рынком акций (Уолл-стрит, инвесторы, акции, ценные бумаги, аналитики, трейдеры), ключевые слова для «бычьих» новостей (оптимизм, надежда, подъём, положительный, оптимистический настрой, бычий) и ключевые слова, которые можно встретить в «медвежьих» новостях (пессимизм, беспокойство, погружение, отрицательный, паника, медвежий).
Особый интерес для изучения опыта анализа оценки ситуаций в текстах на естественном языке представляют работы, в которых изучались массовые настроения и коллективные эмоции (см., например, [Bollenetal 2011], [Cukier 2012], [Golder 2011]). Эмоциональные состояния изучались американскими исследователями Э. Гилбертом и К. Карахалиос (EricGilbert, KarrieKarahalios) по публикациям блога «Живой журнал» (Livejournal) [Сигель 2014: 121 – 126]. Этими авторами был предложен алгоритм вычисления так называемого «индекса страха», или «индекса тревоги». «Живой журнал» предоставляет блогерам возможность помечать каждый свой пост «одним из 132 настроений: зол, занят, пьян, подавлен, спокоен, радостен и т. д. < …> Чтобы придать своим записям ещё одно измерение – экспрессивность, пользователи могут дополнить их маленькими смешными иконками настроений, передающими эмоции < >. При помощи этих обучающих данных были сгенерированы прогнозные модели, способные определять, является ли запись в блоге тревожной (курсив автора – Е. П. Б. ) или нет» [Сигель 2014: 124]. Но большинство публикаций в «Живом журнале» не включает иконок настроения. Для таких записей была применена прогнозная модель. «При всей невероятной сложности человеческой речи прогнозные модели для выявления чувства тревоги следуют относительно простой процедуре, основанной на подсчёте ключевых слов и применении некоторых арифметических операций. Модели не пытаются «понять» смысл записей в блогах».
Например, одна из сгенерированных моделей выявляет тревожные (курсив автора – Е. П. Б. ) записи на основе наличия таких слов, как нервничаю, боюсь, собеседование и больница, и наоборот, отсутствия таких слов, которые характерны для не тревожных (курсив автора – Е. П. Б. ) записей, а именно вау! , круто и люблю (курсив автора – Е. П. Б. )» [Сигель 2014: 125]. При использовании подобных прогнозных моделей удаётся выявить до 32% тревожных записей, которые публикуются в течение дня. Таким образом, сравнение количества выявленных записей в разные дни позволяет судить о колебании предложенного Э. Гилбертом и К. Карахалиос индекса страха, который может быть рассчитан ежедневно для определения массовых настроений и состояний.
Подобные работы были выполнены, как правило, на материале английского языка. Поскольку русский язык по сравнению с английским характеризуется гораздо менее аналитической грамматикой, возникает вопрос о применимости подобного подхода к текстам на русском языке. Здесь можно опираться на два соображения. Во-первых, даже по ключевым словам практически без учёта грамматических связей можно получить удовлетворительные результаты, поскольку значение слова для многих носителей языка в современных коммуникациях нередко сводится почти только к множеству включающих его контекстов. На изменение роли грамматики естественных языков в современных коммуникациях обратил внимание Б. Гройс: «Следовательно, наш диалог с миром всегда базируется на определённых философских предпосылках, определяющих его медиум и риторическую форму. Если мы хотим задать миру вопрос, мы выступаем в качестве пользователей, а если мы собираемся дать ответ на вопрос, заданный нам миром, мы становимся контент-провайдерами. В обоих случаях наши действия определяются специфическими правилами и методами, с помощью которых можно ставить вопросы и давать ответы в рамках глобальной сети. В настоящее время эти правила игры и методы в основном диктуются поисковой системой Google. Она сегодня играет роль, традиционно выполнявшуюся философией и религией < …>. Каковы же правила диалога с миром, предлагаемые нам Google? Согласно этим правилам, любой вопрос должен быть сформулирован в виде слова или комбинации слов. Ответ на него представляет собой множество контекстов, в которых механизм поиска обнаружил это слово или комбинацию» [Гройс 2018: 161 – 162].
Во-вторых, для уточнения результатов можно проводить анализ текстов не только по отдельным словам, а использовать меры неслучайности совместной встречаемости для слов, которые выступают в роли переменных той или иной лексической функции. Величина совместной встречаемости таких слов в пределах одного текста (массива текстов) должна превышать величину их случайного одновременного вхождения в текст (массив текстов).
В настоящее время исследователями используется немало статистических мер, позволяющих с достаточно высокой степенью точности определить показатели совместной встречаемости слов в тексте, однако мы обратимся к наиболее распространенным и апробированным из них: мерам MI-score и t-score. Кроме того, эти меры, как правило, есть среди статистических инструментов, включённых в программное обеспечение наиболее актуальных и доступных корпусов, в которых представлены речевые произведения на русском языке.
«Мера MI (mutualinformation) сравнивает зависимые контекстно-связанные частоты с независимыми, как если бы слова появлялись в тексте совершенно случайно» [Захаров, Хохлова 2010: 78]. Мера t-score тоже отражает частоту совместной встречаемости исходного слова и связанного с ним (лексической функции), её применение позволяет уточнить результаты, полученные при помощи меры MI-score.
Меры совместной встречаемости компонентов единицы вычисляются по следующим формулам.
Формула для вычисления MI-score:
log ( f (n, c) * N )
MI (n, c) = 2
f (n) * f (c)
, где
n – ключевое слово (в нашем случае это исходное слово X)
c– коллокат (в нашем случае это Y, причём Y=Magn (X))
f (n, c) – частота встречаемости ключевого слова n в паре с коллокатомc
f (n), f (c) – независимые частоты ключевого слова n и слова c в корпусе (тексте)
N – общее число словоупотреблений в корпусе (тексте).
Формула для вычисления t-score:
f (n, c) -
f (n) * f (c)

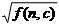 t - score = N
t - score = N
, где
n – ключевое слово (в нашем случае это исходное слово X)
c– коллокат (в нашем случае это Y, причём Y=Magn (X))
f (n, c) – частота встречаемости ключевого слова n в паре с коллокатомc
f (n), f (c) – независимые частоты ключевого слова n и слова c в корпусе (тексте)
N – общее число словоупотреблений в корпусе (тексте).
Для проведения эксперимента нами было выбрано 100 произвольных сообщений в микроблоге Twitter. Примеры твитов, которые были использованы для анализа:
Опасность неравенства: нашим детям грозит бедность (@ForbesRussia 25. 05. 2018)
Есть надежда: красивые и свободные родственники Елизаветы II (@GazetaRu 24. 05. 2018).
Пранкеры узнали у Джонсона о планах введения новых санкций против россиян
(@GazetaRu 24. 05. 2018).
Карта безработных. Роботы лишат нищее население последних денег
(@ForbesRussia 23. 05. 2018).
Для обработки текстов твитов может быть использована одна из стандартных программ, в нашем случае применялась Sketch Engine [SE].
Рассмотрим возможный порядок обработки твитов с опорой на имеющиеся списки лексических единиц.
Для анализа полученного массива твитов нами предварительно были сформированы списки для одиночных лексем, выражающих высокую интенсивность отрицательной оценки (Список 0) и положительной оценки (Список STOP). Твиты с лексемой из Списка 0 – это множество значений Y функции SynMagn отрицательной оценки, они сразу попадают в множество сообщений, в которых содержатся описание угрозы. В Список STOP попадают твиты, включающие слова SynMagn положительной оценки. Такие твиты сразу отбрасываются, поскольку в них не содержится описание угрозы.
Списки лексических единиц могут быть сформированы на базе словарей синонимов, толковых и толково-комбинаторных словарей (например, [Бабенко 2017], [Горбачевич, Балахонова 2016], [Ожегов 1990], [ТКС 1984]). Для включения в списки из словарей отбираются слова с соответствующими пометами. Список 1 и Список 2 также формируются на базе словарей. В Список 1 войдут лексемы X со значением отрицательной оценки, в Список 2 – лексемы Y = Magn (X) и другие интенсификаторы.
Примеры единиц для каждого списка:
Список 0: угроза, опасность, катастрофа, паника, нищета, эпидемия, война т т. п. Список 1: дефицит, безграмотность, болезнь и т. п.
Список 2: невероятно, значительно, полный, весь, крайне, совсем и т. п. Список STOP: красивый, радость, счастье, удовольствие и т. п.
Входящие в твиты слова из Списка 1 и Списка 2 проходят дополнительную обработку, которая заключается в вычислении мер неслучайности совместной встречаемости.
В результате обработки твитов составляются таблицы (Таблица 1 и Таблица 2).
|
|
|
