 |


Выборочное уравнение регрессии
|
|
|
|
Две случайные величины могут быть связаны либо функциональной зависимостью, либо статистической зависимостью, либо быть независимыми. Строгая функциональная зависимость реализуется редко, так как обе или одна из двух величин подвержены еще воздействию случайных факторов. Причем среди этих факторов могут быть и общие для обеих величин, т.е. воздействующие на обе случайные величины. В этих случаях возникает статистическая зависимость.
Статистической называется зависимость, при которой изменение одной из величин влечет изменение распределения другой. В частности, изменение одной из величин вызывает изменение среднего значения другой. В этом случае статистическая зависимость называется корреляционной. Например, связь между количеством удобрений и урожаем, между вложенными средствами и прибылью.
Среднее арифметическое наблюдавшихся значений случайной величины Y, соответствующих значению X=x, называется условным средним 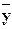 x и является точечной оценкой математического ожидания. Аналогично определяется условное среднее
x и является точечной оценкой математического ожидания. Аналогично определяется условное среднее 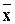 y.
y.
Условное математическое ожидание M (Y | x) является функцией от x, следовательно, его оценка, т.е. условное среднее 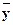 x, также функция от x:
x, также функция от x:
x = f*(x).
Это уравнение называется выборочным уравнением регрессии Y на X. Функцию f*(x) называют выборочной регрессией, а ее график – выборочной линией регрессии Y на X. Аналогично уравнение
y = φ* (y),
функцию φ* (y) и ее график называют выборочным уравнением регрессии, выборочной регрессией и выборочной линией регрессии X на Y.
Отыскание параметров функций f*(x) и φ * (y), если вид их известен, оценка тесноты связи между величинами X и Y – задачи корреляционного анализа. Задачей регрессионного анализа есть оценка параметров функции регрессии βi и остаточной дисперсии σост2.
|
|
|
Остаточная дисперсия – та часть рассеивания Y, которую нельзя объяснить действием X. σост2 может служить для оценки точности подбора функции регрессии и полноты набора признаков, включенных в анализ. Вид зависимости g(x) выбирают, исходя из характера поля корреляции и природы процесса.
Оценкой коэффициента линейной регрессии β является выборочный коэффициент регрессии Y на X ryx. Значения параметра r yx и параметра b уравнения прямой линии регрессии
Y = ryx x + b
подбираются таким образом, чтобы точки (x1,y1), (x2,y2),…,(xn,yn), построенные по данным наблюдений, на плоскости xOy лежали как можно ближе к прямой линии регрессии. Это равносильно требованию, чтобы сумма квадратов отклонений функции Y(xi) от yi была минимальной. В этом суть МНК.
Выборочное уравнение прямой линии регрессии Y на X может быть записано в таком виде:
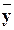 x – = rв sy/sx (x – ),
x – = rв sy/sx (x – ),
где sx и sy – выборочные средние квадратические отклонения X и Y, а
rв = 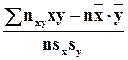 –
–
выборочный коэффициент корреляции, вычисленный по сгруппированным данным. Здесь nxy – частота пары вариант (x,y). Аналогично находят выборочное уравнение прямой линии регрессии X на Y:
y – = rв sx/sy (y – )
Для того, чтобы установить, соответствует ли найденная по выборке математическая модель зависимости между Y и X статистическим данным, следует оценить значимость коэффициентов регрессии и значимость уравнения регрессии.
Проверить значимость коэффициентов регрессии означает установить, достаточна ли величина оценки для обоснованного вывода о том, что коэффициент регрессии отличен от нуля. Выдвигают гипотезу H0: коэффициент регрессии равен нулю β =0. Проверку гипотезы H0 осуществляют с помощью распределенной по закону Стьюдента статистики
t = │b / sb│
где b – оценка коэффициента регрессии, а sb – оценка его среднего квадратического отклонения, другими словами стандартная ошибка оценки. Если │t │≥ tкр (α, k), нулевую гипотезу о равенстве нулю коэффициента регрессии отвергают, и коэффициент считают значимым. При │t │< tкр нет оснований отвергать нулевую гипотезу.
|
|
|
Оценки среднего квадратического отклонения коэффициентов регрессии вычисляют по формулам:
sβ0 = sост / 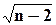 ; sβ1 = sост / (sx ),
; sβ1 = sост / (sx ),
где sx = 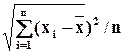 ,
,
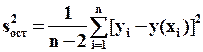 – оценка остаточной дисперсии.
– оценка остаточной дисперсии.
Доверительный интервал для значимых параметров строится по обычной схеме:
b – t(α,k)sb < β < b + t(α,k)sb.
Проверить соответствие математической модели зависимости Y от X статистическим данным следует с помощью оценки значимости самого уравнения регрессии. Оценку значимости приближения функции регрессии в целом выполняют с помощью критерия Фишера, для чего сравнивают c Fкр значение статистики
Fрасч = 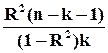
Здесь R2 – коэффициент детерминации, n – объем выборки, k – количество факторных признаков.
|
|
|
